AI百面:Transformer 原理 & 要点
2025-05-31
0.概要
在 Trae/Cursor 下编辑文档,整理 Transformer 核心原理。
术语:
- GPT 是“生成预训练变换器”(Generative Pretrained Transformer)的缩写
- BERT 是“双向编码器表示”(Bidirectional Encoder Representations from Transformers)的缩写
1.Transformer 原理
几个离散的知识点:
- 词嵌入:Word Embedding,将词转换为「向量」,依赖分词算法?
- 位置编码:Positional Encoding,普通的词向量,并无法表示出「词之间顺序信息」,因此,将词的顺序编码,也形成一个「位置向量」。
- 矩阵:高维的向量运算,引入矩阵。
1.1.嵌入 Embedding
在机器学习和自然语言处理(NLP)中,嵌入(Embedding) 是一种将离散型数据(如词语、类别、符号)转换为连续型向量表示的技术。
其本质是,构建一个从高维稀疏空间到低维稠密空间的映射,旨在捕捉数据背后的语义或结构关系。
2.自注意力机制(Self-Attention Mechanism)
自注意力机制是Transformer的核心机制之一。它的基本思想是让模型在处理每个词汇时,都能够关注到输入序列中的所有其他词汇。这样,模型就能够根据整个输入序列的信息来生成每个词汇的表示。
在自注意力机制中,每个词汇的向量表示都会被同时用作查询(Query)、键(Key)和值(Value)。
具体来说,对于每个词汇的向量表示x,我们会得到三个向量:q=Wx,k=Wx和v=Wv,其中W是可学习的权重矩阵。
疑问:如何学习的 W 权重矩阵?对于所有输入,都是相同的 W 吗?
常用 Xavier/Glorot 初始化 W,确保前向传播信号稳定:
W∼Uniform(−1/根号d_model,1/根号d_model)
然后,我们会计算每个词汇与其他所有词汇之间的注意力分数(Attention Score),该分数是通过将查询向量与键向量的点积得到的。最后,我们会使用这些注意力分数来加权值向量,得到每个词汇的自注意力表示。
向量的点积,得到数值,本质是「a向量」在「b向量」上的投影,数值越大,注意力越高(两个向量的关系约密切)。 更多细节,参考向量点乘与叉乘的概念及几何意义
3. Q/K/V注意力(Query/Key/Value Attention)
Q/K/V注意力是自注意力机制的核心组成部分。在自注意力机制中,每个词汇的向量表示都会被转换为三个向量:查询向量(Query Vector)、键向量(Key Vector)和值向量(Value Vector)。
这三个向量的作用分别如下:
- 查询向量(Query Vector):用于与其他词汇的键向量进行匹配,以计算注意力分数。
- 键向量(Key Vector):用于与查询向量进行匹配,以计算注意力分数。
- 值向量(Value Vector):用于根据注意力分数生成每个词汇的自注意力表示。
通过Q/K/V注意力的方式,Transformer能够在处理每个词汇时,都能够关注到整个输入序列的信息。这使得模型能够更好地理解和处理文本数据。
4.编码器 和 Embedding 的区别
疑问:llm 模型,现在流行的都是 解码器模型,但是还有 embedding 层,这个是否可以认为就是 编码器的功能呢?
理解有一部分对,但不能完全等号化。我们可以拆开来看:
1. LLM 主体是解码器(Decoder-only)
- 现代主流大模型(GPT 系列、LLaMA、DeepSeek 等)用的是 Transformer 的解码器结构,原因是它擅长自回归生成(根据前文预测下一个 token)。
- 在这个架构里,输入文本会先经过一个 embedding 层 转成向量,再经过多层解码器计算。
2. Embedding 层的作用 ≠ 编码器的作用
- Embedding 层:只是一个
查表或线性映射,把 token ID 映射到一个固定维度的稠密向量空间。它是“输入变向量”的入口,功能比较简单,没有复杂的上下文建模。 - 编码器(Encoder):在
BERT这种 Encoder-only 模型里,编码器会对整个输入序列做双向上下文建模,产生每个位置的上下文向量,能捕捉语义关系。 - 所以 embedding 层只是
向量化输入符号,而编码器是理解并处理输入的上下文语义。
3. 为什么 decoder-only 也有 embedding 层
- 无论是 Encoder、Decoder 还是 Encoder-Decoder 架构,输入第一步都要把 token ID 转成 embedding。
- 在 decoder-only LLM 中,这个 embedding 后面直接送进多层解码器做自回归计算,而不是送到一个独立的编码器模块。
4. 类比
- Embedding 层:像是把单词翻译成数字坐标(但还不解释含义)。
- 编码器:是个“理解器”,会把整句话上下文都考虑进去,把每个词的表示调成适合后续任务的形式。
- 所以 embedding 层只是输入预处理,不等于编码器。
5.模型训练过程中,embedding 层参数是否会变
疑问:embedding 词嵌入时,每个分词映射的 稠密空间向量,是怎么确定的?这个向量是在「大模型预训练过程中」动态变化的吗?
是的,embedding 向量在大模型预训练过程中是动态变化的,而且是通过训练数据和损失函数一点点学出来的,不是人工设定的。 我给你分步骤解释一下:
1. 初始状态
-
在模型刚初始化时,embedding 层是一个形状类似
[词表大小, 向量维度]的矩阵(比如
[50,000, 4,096])。 - 每一行代表一个 token 对应的向量,值是随机初始化的(通常是高斯分布或均匀分布的随机数)。
- 刚开始它不“懂”语义,比如 “cat” 和 “dog” 的向量可能完全不相关。
2. 训练时的更新机制
- 预训练中,模型会反复看到大量文本(几百亿 token 以上)。
- 对于每个训练样本,token 会先映射到 embedding 向量,然后经过解码器计算预测下一个 token(或其他训练目标)。
- 预测错误时,损失函数(loss)会反向传播,不仅更新 Transformer 里的注意力和前馈层权重,也会更新 embedding 层里相关 token 的向量。
-
结果是:
- 出现在相似上下文中的词,embedding 会被“拉近”到类似方向。
- 出现在完全不同语境的词,embedding 会被“推开”。
3. 为什么是动态变化的
- 训练过程中,每次梯度更新都会改变 embedding 矩阵中涉及到的行(即 batch 里出现的 token 对应的行)。
-
随着训练进行,embedding 从一堆随机向量逐渐形成“语义地图”,比如:
- 数字会聚在一起
- 颜色词聚在一起
- 动词和名词分布不同
- 这个过程和 Transformer 主体是同步训练的,并不是先训练 embedding 再训练主干。
4. 类比
你可以把 embedding 矩阵想成一个“单词在高维空间的地理坐标表”:
- 初始时,所有城市坐标是乱摆的。
- 训练中,模型不断收到“这两个城市很近 / 那两个城市很远”的反馈,于是它会动态搬家调整位置。
- 最终形成一个语义地理图,相似词像邻居,不相关的词相隔很远。
画了一个 “embedding 向量训练演化示意图”,直观展示从随机分布到语义分布的变化过程,这样你就能看到它是怎么在预训练中“长大”的。
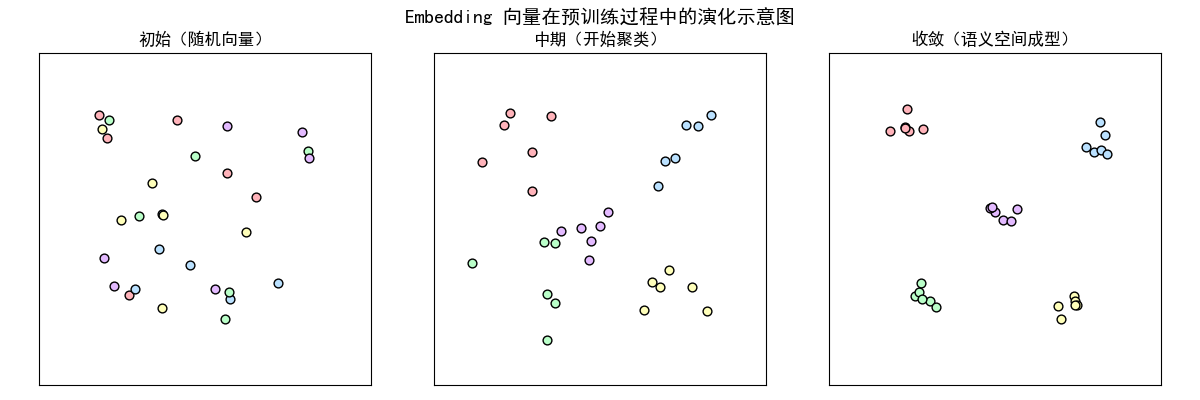
6.自回归模型
GPT 这样的解码器模型是通过逐字预测生成文本,因此它们被视为一种自回归模型。
- 自回归模型会将之前的输出作为未来预测的输入。
- 因此,在 GPT 中,每个新词的选择都是基于之前的文本序列,这样可以提高生成文本的连贯性。
[!NOTE]
自回归,是一种用于
时间序列分析的统计技术,它假设时间序列的当前值是其过去值的函数。自回归模型,使用类似的数学技术来确定序列中,元素之间的概率相关性。然后,它们使用所得知识,来猜测未知序列中的下一个元素。
自相关,用于衡量序列中元素之间的相关性;一般会圈定一个时间窗口,计算窗口内元素之间的相关性。大部分场景下,窗口之前的元素,对窗口之后的元素影响较小。
7.独立的嵌入模型
虽然我们可以使用预训练模型(例如 Word2Vec)为机器学习模型生成嵌入,但 LLM 通常会生成自己的嵌入,这些嵌入是输入层的一部分,并在训练过程中进行更新。
将嵌入作为 LLM 训练的一部分进行优化,而不直接使用 Word2Vec ,有一个明确的优势:嵌入能够针对特定的任务和数据进行优化。
原文地址:https://ningg.top/ai-series-100-transformers-intro/