AI 实践:本地搭建 RAG + LLMs
2025-08-09
0.背景
突出一批「典型场景」,利用 AI 能力实现,加深原理的理解。
这次的主要内容,都在 local-RAG-with-LLM。
实践:先做、尽快做完,再依赖迭代做到完美。
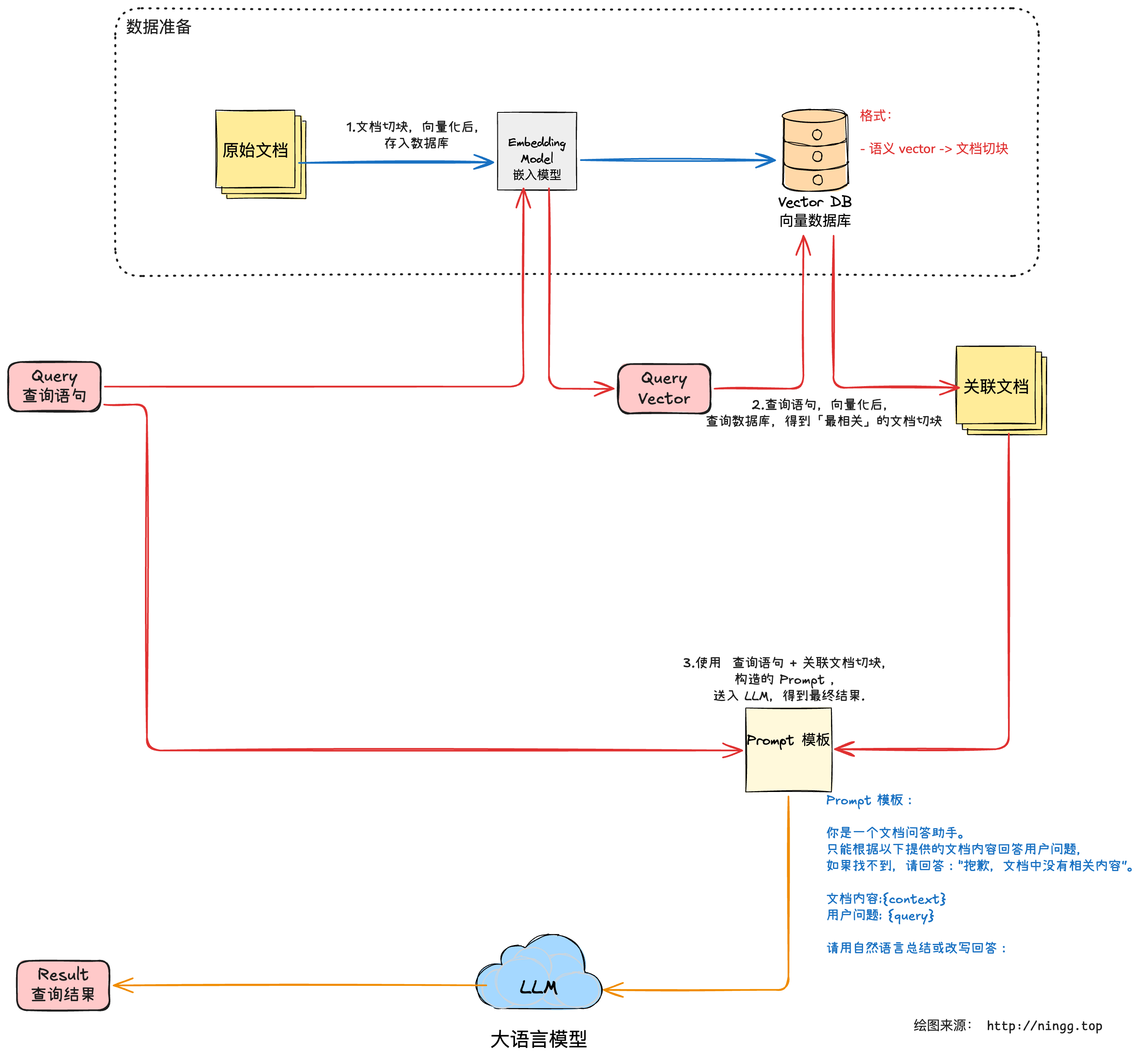
1.RAG 系统原理
包含几个部分:
- 基础工具:向量数据库、大数据模型、向量化工具(也可以复用大模型能力)
- 基础数据:关联文档
- 具体过程:
- 1.数据准备:
- 1.1.将关联文档,进行切块
- 1.2.将文档切块,向量化
- 1.3.向量化的文档切块,存入
向量数据库
- 2.查询语句 Query,在向量化后,得到
向量化Query,依赖向量数据库,使用向量化Query,查询出 最相关的几个文档切块 - 3.将 Query 语句 + 相关的文档切块,加入
prompt 模板,输入给 LLM 模型,得到最终的答案。
- 1.数据准备:
注意:
1.两次向量化:第一部分
向量化,只是获取了相关的文档片段;后续,仍然是语言文本构造 prompt,输入给 LLM 模型,在大模型内部,仍然会进行二次向量化。2.向量数据库,边界:只认识向量,不认识语言文本;需要在外部,将语言文本,转换为向量。
示意图:
2. 实践:本地搭 RAG 系统 + Ollama
示例代码: 更多细节参考 design-manual
import faiss
import numpy as np
import requests
import textwrap
import json
# ========= 1. Ollama API 封装 =========
OLLAMA_API = "http://localhost:11434/api"
def ollama_embed(text, model="deepseek-r1:8b"):
"""调用 Ollama embedding 接口"""
resp = requests.post(f"{OLLAMA_API}/embed", json={"model": model, "input": text})
data = resp.json()
# print('ollama_embed result data:', data)
return np.array(data["embeddings"][0], dtype="float32")
def ollama_chat(prompt, model="deepseek-r1:8b"):
"""调用 Ollama Chat 接口"""
payload = {
"model": model,
"prompt": prompt,
"stream": False
}
resp = requests.post(f"{OLLAMA_API}/generate", json=payload)
data = resp.json()
# print('ollama_chat result data:', data)
return data["response"].strip()
# ========= 2. 加载文档并切分 =========
docs = [
"""我们的系统支持多种支付方式,包括支付宝、微信支付和银行卡支付。
在支付过程中如遇到问题,可以联系客服协助处理。""",
"""用户可以通过点击登录页面的“忘记密码”,
使用注册邮箱或手机号进行验证,即可重置密码。""",
"""完成订单后,您可以在“个人中心-订单管理”页面申请电子发票。
系统将自动开具并发送到您的邮箱。"""
]
def split_into_chunks(text, chunk_size=200):
text = text.replace("\n", " ")
return textwrap.wrap(text, chunk_size)
chunks = []
for doc in docs:
processed_doc = split_into_chunks(doc)
chunks.extend(processed_doc)
chunk_embeddings = []
for chunk in chunks:
emb = ollama_embed(chunk)
chunk_embeddings.append(emb)
# ========= 3. 构建向量库 =========
dim = len(ollama_embed("测试")) # 向量维度
index = faiss.IndexFlatL2(dim)
index.add(np.array(chunk_embeddings))
# ========= 4. 检索 =========
def retrieve_chunks(query, top_k=3):
query_emb = ollama_embed(query)
D, I = index.search(np.array([query_emb]), top_k)
return [chunks[i] for i in I[0]]
# ========= 5. 生成答案 =========
def answer_query(query):
retrieved = retrieve_chunks(query, top_k=3)
context = "\n".join(retrieved)
prompt = f"""
你是一个文档问答助手。
只能根据以下提供的文档内容回答用户问题,
如果找不到,请回答:“抱歉,文档中没有相关内容”。
文档内容:
{context}
用户问题: {query}
请用自然语言总结或改写回答:
"""
return ollama_chat(prompt)
# ========= 6. 测试 =========
if __name__ == "__main__":
# q = "系统支持哪些支付方式?"
q = "你是谁?"
print("用户提问:", q)
print("助手回答:", answer_query(q))
特别注意:上面的 prompt 模板,其中包含 原始 query + 相关文档片段 context
prompt = f"""
你是一个文档问答助手。
只能根据以下提供的文档内容回答用户问题,
如果找不到,请回答:“抱歉,文档中没有相关内容”。
文档内容:
{context}
用户问题: {query}
请用自然语言总结或改写回答:
"""
原文地址:https://ningg.top/ai-series-local-rag-with-llm-practise/