AI 实践:RAG 架构演进 & 核心技术
2025-08-23
0.概要
先大量阅读、模仿,再形成自己的理解。
RAG 技术的演进是一个从简单到复杂、从 Naive 到 Agentic 的系统性优化过程;阅读本文后,您将理解 RAG 演进的每一步都攻克了哪些挑战。
- 首先剖析
Naive RAG的基础架构及其核心挑战, - 继而,深入探讨三个优化方向:
- 查询优化:包括查询
重写、查询扩展等策略 - 语义增强:重点解析 Anthropic 提出的
上下文检索方法 - 计算效率:客观评价
缓存增强生成(CAG)的技术边界
- 查询优化:包括查询
- 最终,聚焦
Agentic RAG的范式突破,详解其两大核心机制:- 动态数据源路由
- 答案验证与修正循环
1. Naive RAG 的出现
2022 年底 ChatGPT 的推出让 LLMs 成为了主流,几乎与此同时,Naive RAG 也应运而生。检索增强生成(RAG)技术的出现旨在解决原生 LLM 所面临的问题。简而言之就是:
-
幻觉问题。
-
- 有限的
上下文窗口大小。
- 有限的
-
- 无法访问
非公开数据。
- 无法访问
-
- 无法自动获取训练截止日期后的新信息,且
更新知识需要重新训练。
- 无法自动获取训练截止日期后的新信息,且
RAG 的最简单实现形式如下:
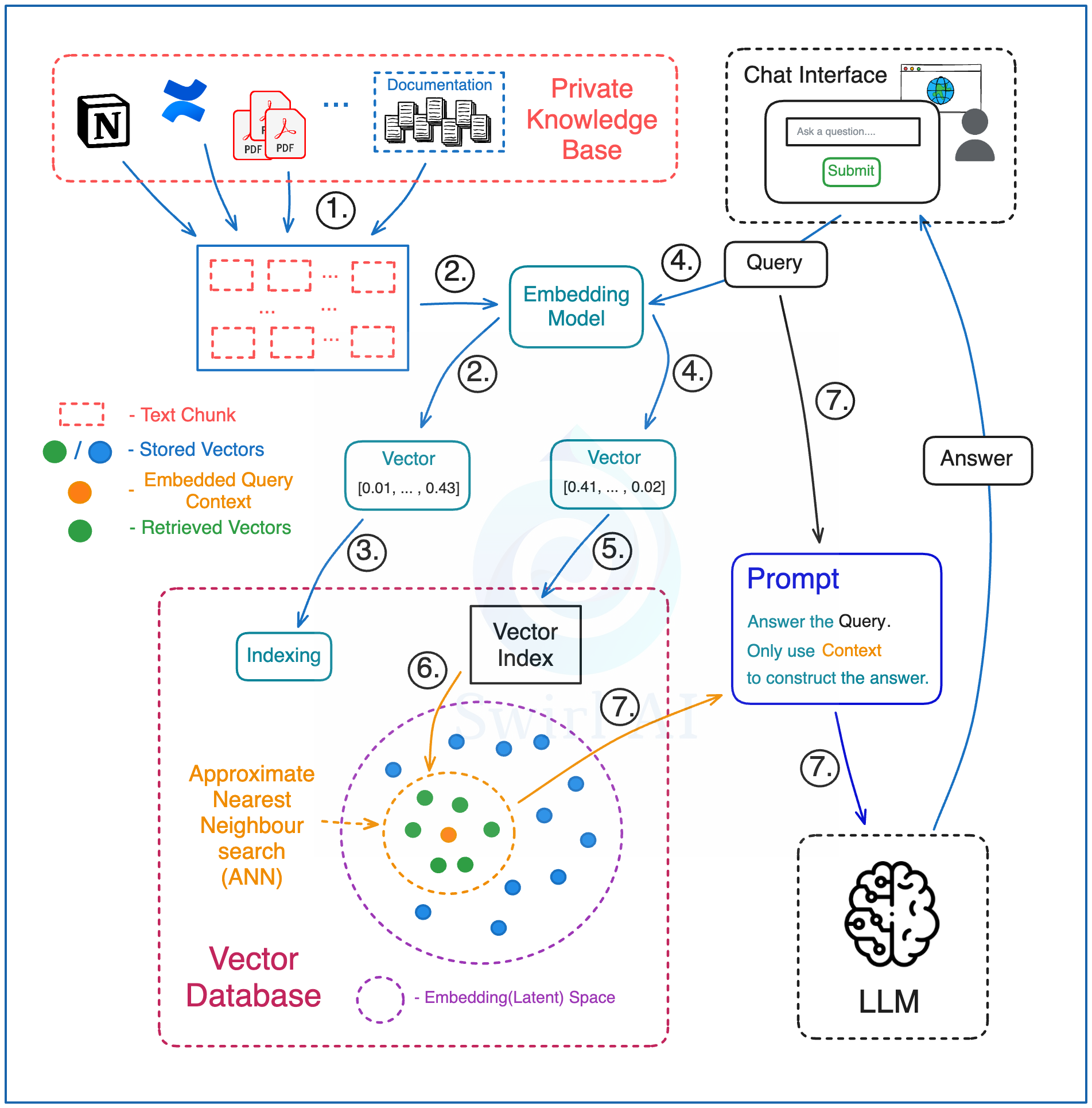
1.1.预处理(Preprocessing)
1)将整个知识库的文本语料分割成文本块(chunk) —— 每个文本块代表一段可供查询的上下文片段。目标数据可来自多种来源,例如以 Confluence 文档为主、PDF 报告为辅的混合资料库。
2)使用嵌入模型(Embedding Model)将每个文本块转换为向量嵌入(vector embedding)。
3)将所有向量嵌入存储到向量数据库(Vector Database)中。 同时分别保存代表每个嵌入的文本及其指向嵌入的指针。
1.2.检索(Retrieval)
4)在向量数据库或知识检索系统中,为了确保查询和存储的知识能够准确匹配,需要用同一个嵌入模型(Embedding Model)来处理存储到知识库中的文档内容和用户的查询。
5)使用生成的向量嵌入在向量数据库的索引上运行查询。 选择要从向量数据库中检索的向量数量 —— 等同于你将检索并最终用于回答查询的上下文数量。
6)向量数据库针对提供的向量嵌入,在索引上执行近似最近邻(ANN)搜索,并返回之前选定数量的上下文向量。 该过程会返回在给定嵌入空间(Embedding/Latent space)中最相似的向量,需将这些返回的向量嵌入映射到其对应的原始文本块。
7)通过提示词(prompt)将问题连同检索到的上下文文本块传递给 LLM。 指示 LLM 仅使用提供的上下文来回答给定问题。这并不意味着不需要提示词工程(Prompt Engineering)——你仍需确保 LLM 返回的答案符合预期范围,例如,如果检索到的上下文中没有可用数据,则应确保不提供编造的答案。
2. Naive RAG 的动态组件
即便不采用任何高级技术,在构建生产级 RAG 系统时也需要考虑许多动态组件。
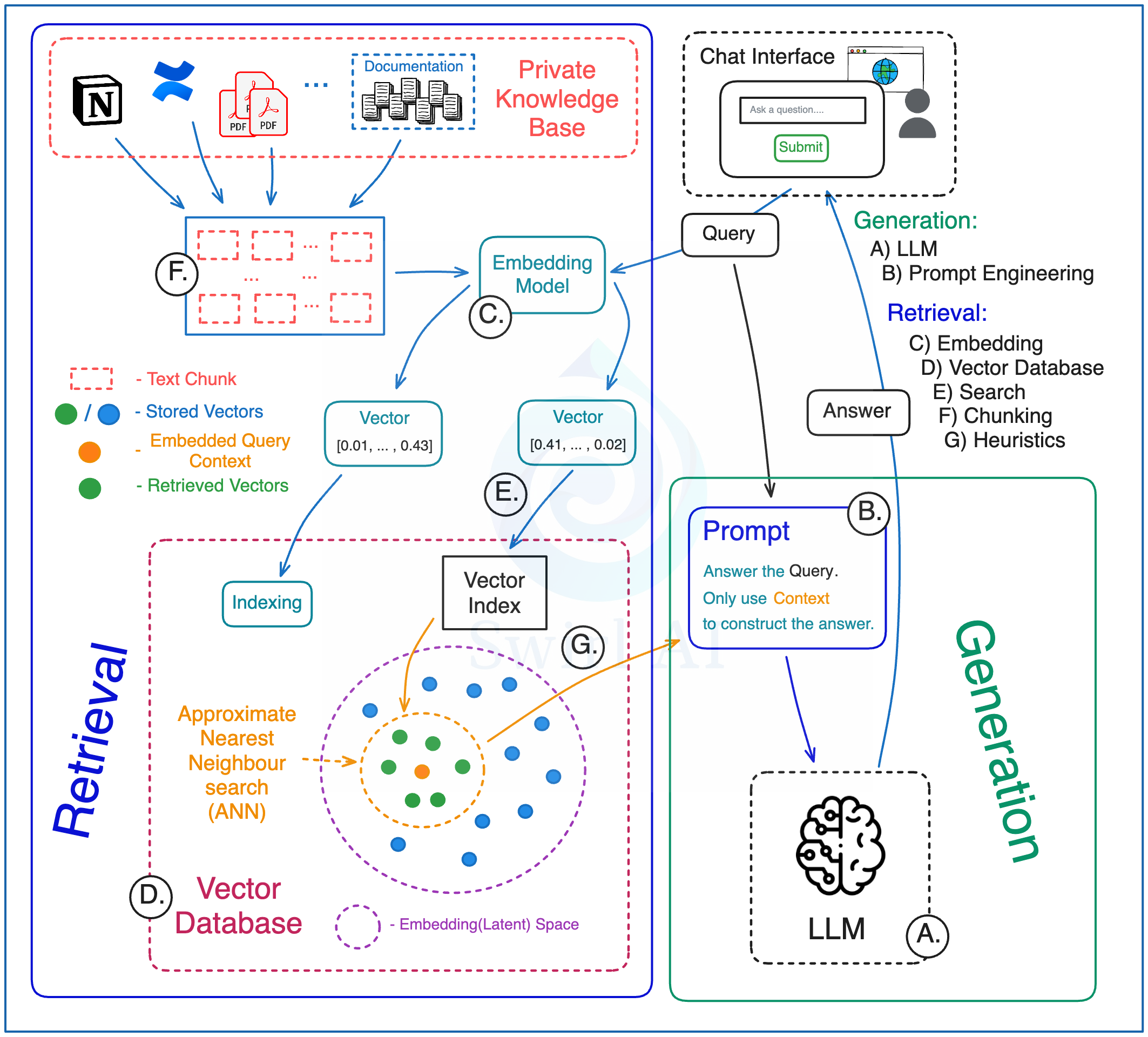
2.1.检索(Retrieval)
F) 分块策略 - 如何对用于外部上下文的数据进行分块
- 小文本块与大文本块的选择
- 滑动窗口或固定窗口的文本分块方法
- 检索时是否关联父块/链接块,或仅使用原始的检索数据
C) 选择嵌入模型,将外部上下文嵌入到 latent space 或从 latent space 中查询。 需要考虑上下文嵌入(Contextual embeddings)。
D) 向量数据库
- 选择哪种数据库
- 选择部署位置
- 应与向量嵌入一并存储哪些元数据?这些数据将用于检索前的预筛选和检索后的结果过滤。
- 索引构建策略
E) 向量搜索
- 选择相似度度量标准
- 选择查询路径:元数据优先,还是近似最近邻(ANN)优先
- 混合搜索方案
G) 启发式规则 - 应用于检索流程的业务规则
- 根据文档的时间相关性调整权重
- 对上下文进行去重(根据多样性进行排序)
- 检索时附带内容的原始来源信息
- 根据特定条件(如用户查询意图、文档类型)对原始文本进行差异化预处理
2.2.生成(Generation)
A) 大语言模型 - 为你的应用程序选择合适的 LLM
B) 提示词工程 - 即使能在提示词(prompt)中调用上下文信息,也仍需精心设计提示词:你依然需要调整系统(包括设定角色(Role)、规则(Rules)、输出格式(Format)等对齐手段),才能生成符合预期的输出,并防范越狱攻击。
完成上述所有工作后,我们才得以构建可运行的 RAG 系统。
但残酷的事实是,此类系统往往难以真正解决业务问题。由于各种原因,这种系统的准确性可能很低。
3. 改进 Naive RAG 系统的高级技术
为不断提高 Naive RAG 系统的准确性,我们采用了以下一些较为成功的技术:
- 查询改写(Query Alteration) - 可采用以下几种技巧:
- 查询重写(Query rewriting) :让大语言模型(LLM)
重写原始查询,以更好地适应检索过程。重写的方式有多种,例如,修改语法错误,或将查询简化为更简短精炼的语句。 - 查询扩展(Query Expansion):让 LLM 对原始查询进行多次改写,
创建多个变体版本(variations)。接着,多次检索过程,以获取更多相关文档的上下文。
- 查询重写(Query rewriting) :让大语言模型(LLM)
- 重排序(Reranking) - 对初次检索出的文档,用比常规上下文搜索更复杂的方法进行重排序。通常,这需要使用更大的模型,并且在检索阶段有意获取远超实际所需数量的文档。重排序(Reranking)与前文提到的查询扩展(Query Expansion)配合使用效果尤佳,因为后者通常能返回比平时更多的数据。整个过程类似于我们在推荐系统中常见的做法。
- 嵌入模型的微调(Fine-Tuning of the embedding model) - 某些领域(如医疗)在使用基础嵌入模型进行数据检索效果不佳。此时,你就需要对自己的嵌入模型进行定制化微调。
接下来,我们再看些其它高级的 RAG 技术与架构。
4. 上下文检索(Contextual Retrieval)
上下文检索(Contextual Retrieval)的概念由 Anthropic 团队在 2024年底提出。其目标在于提升基于检索增强生成(RAG)的 AI 系统中检索到的数据的准确性和相关性。
我非常喜欢上下文检索的直观性和简洁性。而且它的确能带来不错的效果。
以下是上下文检索的实现步骤:
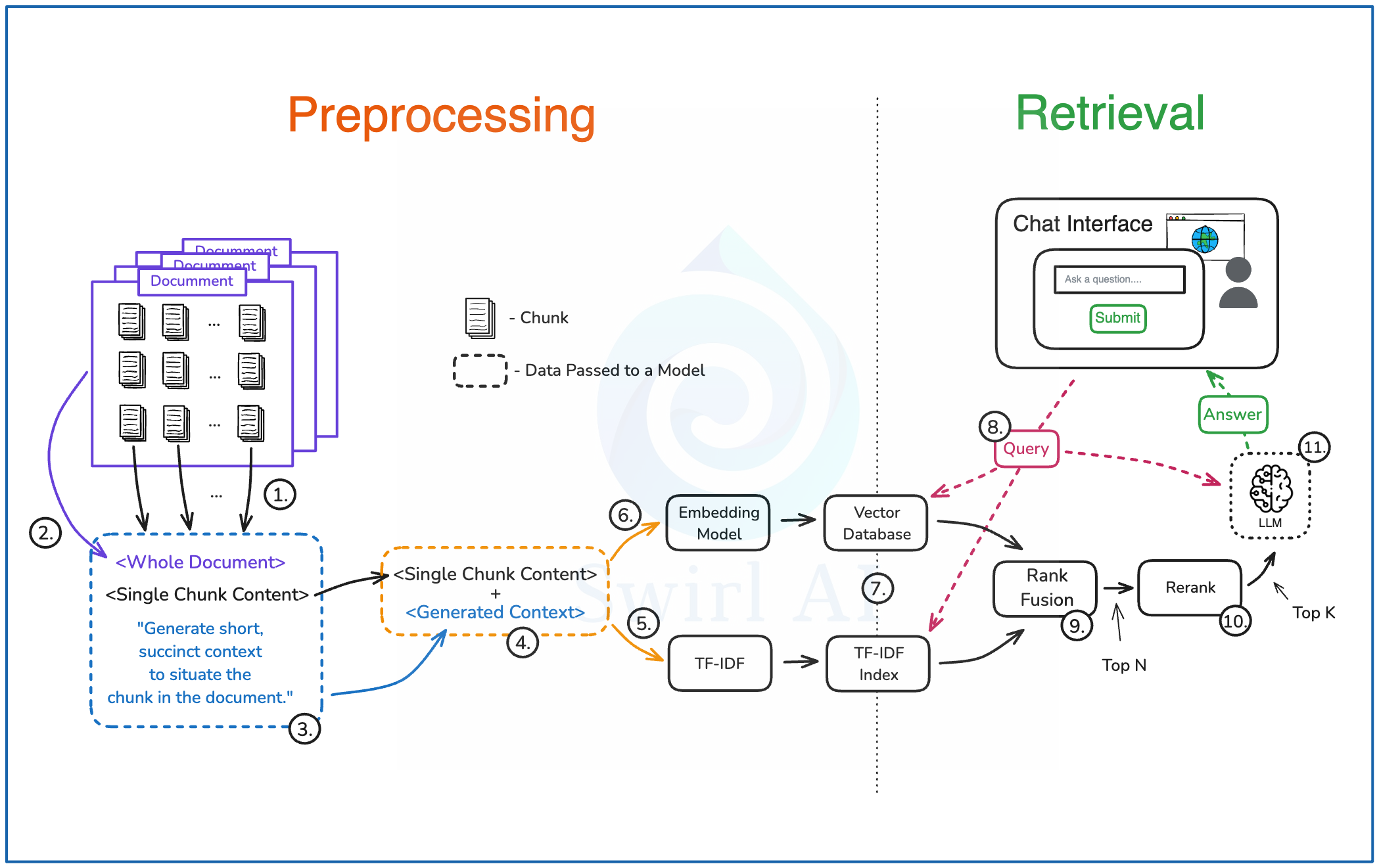
4.1.预处理(Preprocessing)
1)使用选定的分块策略将每份文档分割成若干个文本块。
2)将每个文本块单独与完整文档一起加入提示词中。
3)在提示词中添加指令,要求 LLM 定位该文本块在文档中的位置,并为其生成简短的上下文。随后将此提示词输入选定的 LLM。
4)将上一步生成的上下文,与其对应的原始文本块合并。
5)将组合后的数据输入一个 TF-IDF 嵌入器(embedder)。
6)再将数据输入一个基于 LLM 的嵌入模型(embedding model)。
7)将步骤 5 和步骤 6 生成的数据存入支持高效搜索的数据库中。
4.2.检索(Retrieval)
8)使用用户查询(user query)检索相关上下文。使用近似最近邻(ANN)搜索实现语义匹配,同时使用 TF-IDF 索引进行精确搜索。
9)使用排序融合(Rank Fusion)技术对检索结果进行合并、去重,并选出排名前 N 的候选项。
10)对前一步的结果进行重排序(Rerank),将范围缩小至前 K 个候选项。
11)将步骤 10 的结果与用户查询一起输入 LLM,生成最终答案。
4.3.思考
- 步骤 3. 听起来(并且实际也)耗费惊人,但通过应用提示词缓存技术(Prompt Caching),成本可以显著降低。
- 提示词缓存技术既可在专有(闭源)模型场景下使用,也可在开源模型场景下使用(请参阅下一段内容)。
5. 缓存增强生成(Cache Augmented Generation)的昙花一现
2024 年底,一份白皮书在社交媒体上短暂刷屏。它介绍了一项有望彻底改变 RAG (检索增强生成) 的技术(真的能吗?)—— 缓存增强生成(Cache Augmented Generation, CAG)。我们已经了解了常规 RAG 的工作原理,下面简要介绍一下 CAG:
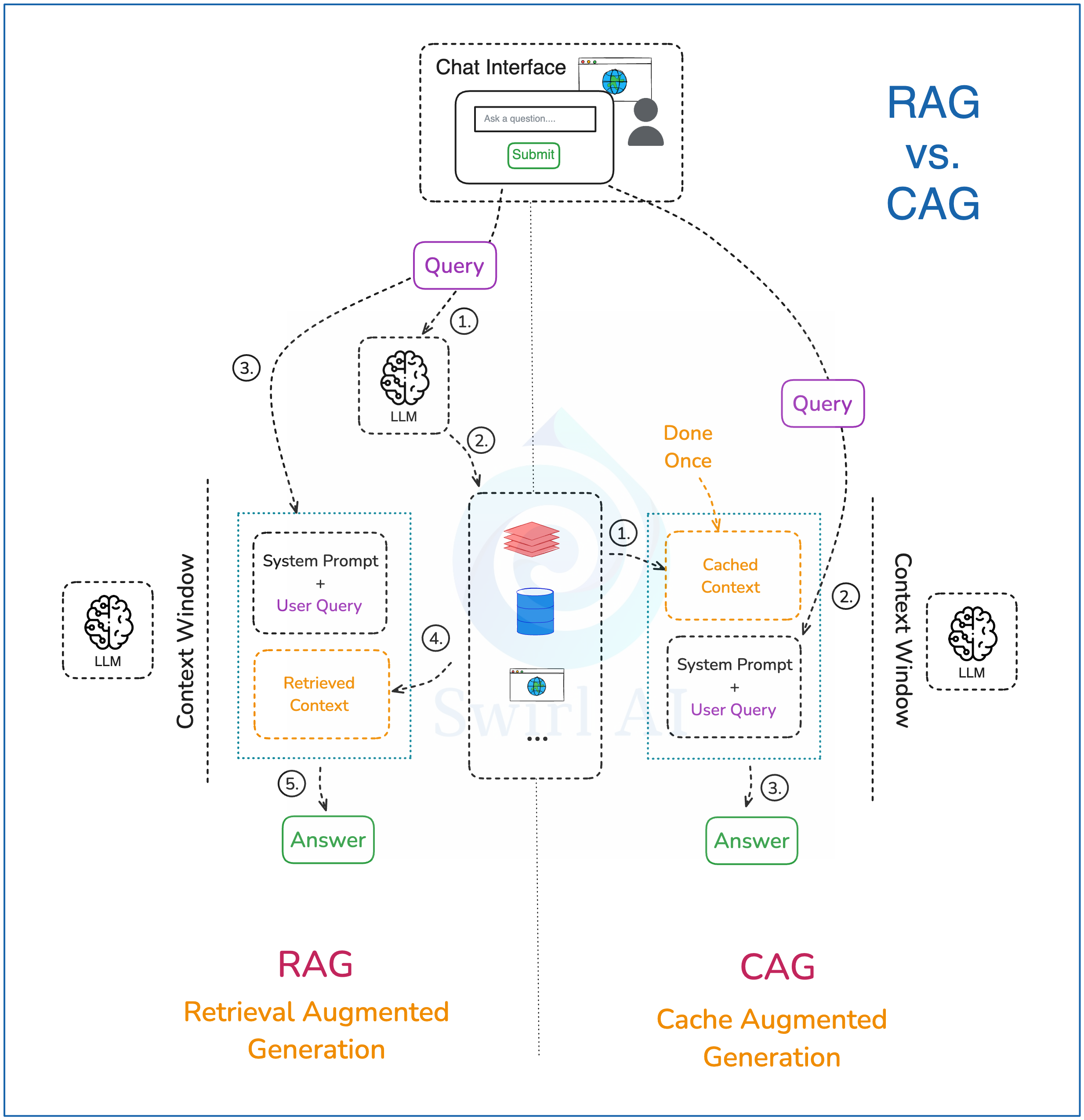
1)将所有外部上下文预计算至 LLM 的 KV 缓存中,并存入内存。该过程仅需执行一次,后续步骤可重复调用初始缓存而无需重新计算。
2)向 LLM 输入包含用户查询(user query)的系统提示词,同时提供如何使用缓存上下文的指令。
3)将 LLM 生成的答案返回用户。完成后清除缓存中的临时生成内容,仅保留最初缓存的上下文,使 LLM 准备好进行下一次生成。
CAG 承诺,通过将所有上下文存储在 KV 缓存中(而非每次生成时只检索部分数据),实现更精准的检索。现实如何?
- CAG 无法解决因上下文极长而导致的不准确问题。
- CAG 在数据安全方面存在诸多局限性。
- 对大型组织而言,将整个内部知识库加载到缓存近乎不可能。
- 缓存会失去动态更新能力,添加新数据非常困难。
事实上,自从多数 LLM 提供商引入提示词缓存(Prompt Caching)技术后,我们已在使用的正是 CAG 的一种变体。我们的做法可以说是 CAG 与 RAG 的融合,具体实施过程如下:
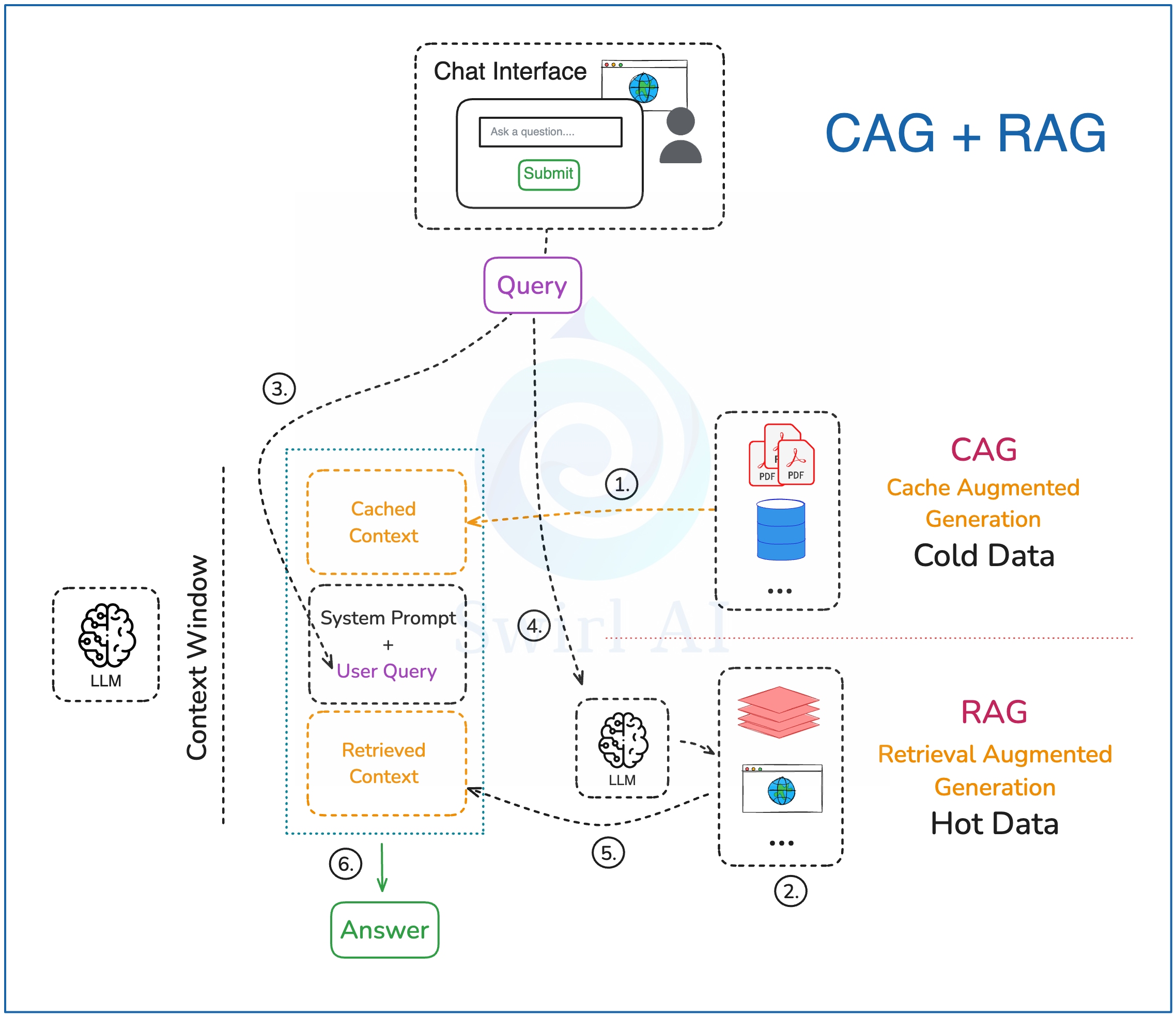
5.1.数据预处理
1)在缓存增强生成(CAG)中,我们仅使用极少变化的数据源。除了要求数据更新频率低外,我们还应该考虑哪些数据源最常被相关查询命中。确定这些信息后,我们才会将所有选定的数据预计算至 LLM 的 KV 缓存中,并将其缓存在内存中。此过程仅需执行一次,后续步骤可多次运行而无需重新计算初始缓存。
2)对于 RAG,如有必要,可将向量嵌入预计算并存入兼容的数据库中,供后续步骤 4 检索。有时对于 RAG 来说,只需更简单的数据类型,常规数据库即可满足需求。
5.2.查询路径
3)构建一个提示词,需包含用户查询及系统提示词,明确指导大语言模型如何利用缓存的上下文(cached context)及外部检索到的上下文信息。
4)将用户查询转化为向量嵌入,用于通过向量数据库进行语义搜索,并从上下文存储中检索相关数据。若无需语义搜索,则查询其他来源(如实时数据库或互联网)。
5)将步骤 4 中获取的外部上下文信息整合至最终的提示词中,以增强回答质量。
6)向用户返回最终生成的答案。
接下来,我们将探讨最新的技术发展方向 —— Agentic RAG。
6. Agentic RAG
Agentic RAG 新增了两个核心组件,试图降低应对复杂用户查询时的结果不一致性。
- 数据源路由(Data Source Routing)。
- 答案验证与修正(Reflection)。
现在,让我们来探究其工作机制。
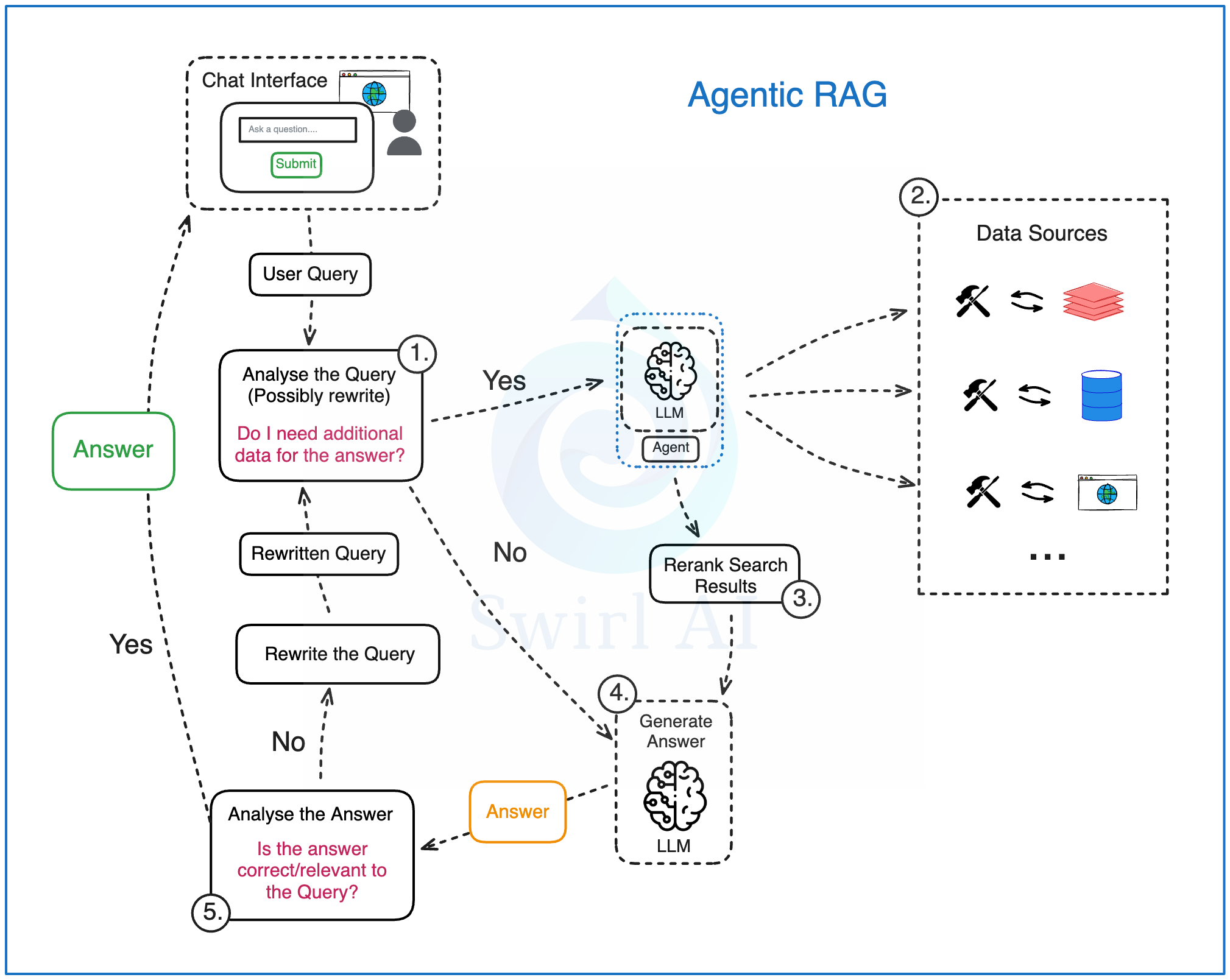
1)分析用户查询:将原始用户查询传递给基于大语言模型的智能体进行分析。在此阶段:
a. 原始查询可能会被改写(有时需多次改写),最终生成单个或多个查询传递至后续流程。
b. 智能体判断是否需要额外数据源来回答查询。这是体现其自主决策能力的第一环节。
2)如果需要其他数据,则触发检索步骤,此时进行数据源路由(Data Source Routing)。 系统中可预置一个或多个数据集,智能体被赋予自主权来选择适用于当前查询的具体数据源。举几个例子:
a. 实时用户数据(如用户当前位置等实时信息)。
b. 用户可能感兴趣的内部文档。
c. 网络公开数据。
d. …
3)一旦从潜在的多个数据源检索到数据,我们就会像在常规 RAG 中一样对其进行重排序。 这也是一个关键步骤,因为利用不同存储技术的多个数据源都可整合至此 RAG 系统中。检索过程的复杂性可被封装在提供给智能体的工具背后。
4)尝试直接通过大语言模型生成答案(或生成多个答案,或生成一组操作指令)。 此过程可在第一轮完成,或在答案验证与修正(Reflection)环节后进行。
5)对生成的答案进行分析、总结,并评估其正确性和相关性:
a. 若智能体判定答案已足够完善,则返回给用户。
b. 若智能体认为答案有待改进,则尝试改写用户查询并重复这个生成循环(generation loop)。此处体现了常规 RAG 与 Agentic RAG 的第二大差异。
近期 Anthropic 的开源项目 MCP,将为 Agentic RAG 的开发提供强劲助力。
7. 总结 (Wrapping up)
至此,我们回顾了现代检索增强生成(RAG)架构的演进历程。RAG 技术并未消亡,也不会在短期内消失。 我相信其架构在未来一段时间内仍将持续演进。学习这些架构并了解何时使用何种方案,将是一项有价值的投资。
一般来说,方案越简单越好,因为增加系统复杂性会带来新的挑战。 一些新出现的挑战包括:
- 对端到端系统进行评估的困难。
- 多次调用大语言模型导致的端到端延迟增加。
- 运营成本的增加。
- …
关联资料
原文地址:https://ningg.top/ai-series-rag-evolution-arch/