MySQL 最佳实践:常见问题汇总(2)
2014-10-18
几个最朴素的问题
几个方面:
- 数据存储:
- 数据结构
- 索引:
- 为什么需要索引?如何评价索引?如何优化索引?
- 索引原理:索引怎么实现的?
- 事务:
- 事务如何实现:日志
- 事务隔离级别:MVCC 控制
- 集群:主从结构(主从复制的)
常见的问题
常见的问题:
- MySQL 复制的基本过程?
- 加锁的过程:加锁加在哪个地方?
- 是否在「索引文件」上加锁?
- 如果走了「辅助索引」,是否会同时在「辅助索引」和「聚集索引/聚簇索引」
- 事务如何实现?多少种日志?事务隔离级别
- 事务的 ACID 分别实现方式
- 索引
- 索引选择性、索引区分度:不重复行的占比
- Explain:
- 可用的索引、使用的索引、预估扫描的行数
- Extra 中 Using Index(不走聚簇索引)、Using Where(走聚簇索引,优化器需要回表查询)
- 数据存储:
- B 树 – B+树,没有 B-树,但是 B 树,经常显示为:
B-Tree,有人读作B- 树,是误读 - B 树,中间节点存放了数据,导致层数增加; B+ 树 层数更少,每一个节点都是一个页,减少了磁盘IO的次数;
- B 树 – B+树,没有 B-树,但是 B 树,经常显示为:
- 日志:
- Slave 上,是否有 bin Log?
- Master 上,bin log 是否有 commit?事务之间是否是交叉的?
- bin log 日志的格式:适用场景、复制过程中的优劣
- statement
- 存储引擎:对比多种引擎
- MyISAM:不支持事务、表锁,索引都是
非聚簇索引 - InnoDB:支持事务、行锁,主索引是
聚簇索引
- MyISAM:不支持事务、表锁,索引都是
- MVCC:过程
- 多事务并发执行过程中,每个事务都会对应一个数据版本(snapshot),不同 snapshot 之间,拉链连接;
- 不同的事务,只能看到版本对应的 snapshot 数据
- MVCC 跟 锁之间的关系
- ACID的实现:
- 原子性:undo log,日志方式,实现事务回滚
- 隔离性:MVCC,多版本并发控制
- char、varchar
- char:定长,最后
空格补齐 - varchar:变长,开头一个字节,记录字符长度,实际存储空间是:字符长度 + 1
- char:定长,最后
- 唯一性索引
- 唯一性索引,是如何实现的
- null 字段,是否可以作 unique key
典型问题剖析
集群:主从复制过程
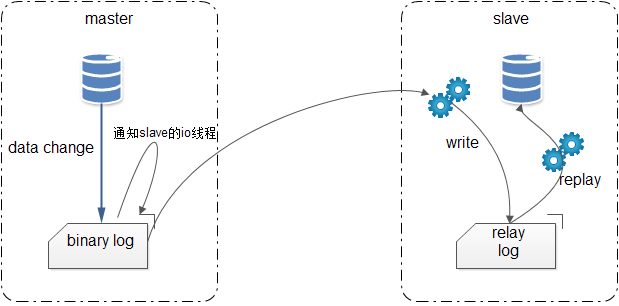
整体上:异步、单线程
细节上,注意 2 个日志文件:Master 上的 bin log、Slave 上的 relay log
MySQL 主从复制的过程:
- Master:Master 上,事务提交后,会写入
bin log - 异步复制:异步线程,将 Master 上
bin log新增的内容,同步到 Slave,并写入到 Slave 的relay log中; - Slave:Slave 上,线程监听
relay log的变化,并在 Slave 上,replay(重放)事务;
扩展:
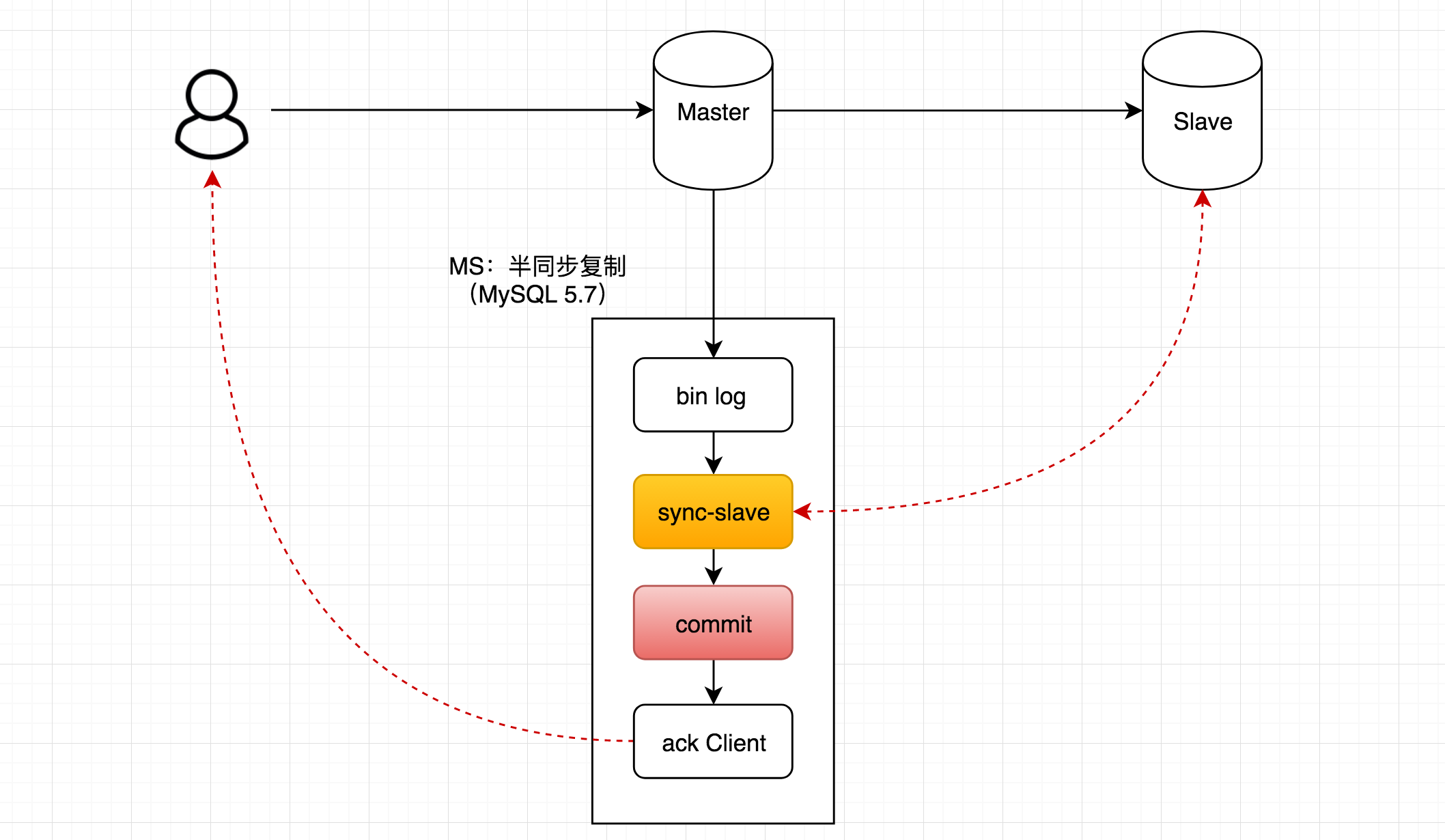
- MySQL 5.5+:引入
半同步复制(semi-sync),解决异步复制场景下,事务提交后, Master 宕机,事务丢失的问题(插件形式支持)半同步复制:至少有一个 Slave 完成复制,Master 才会确认执行成功- Master:安装插件,开启
半同步,同时,设置超时时间 - Slave:安装插件,开启
半同步
- MySQL 5.6+:引入
多线程的异步复制,改善复制的性能;多线程的异步复制:只支持数据库(Database)粒度的并发复制,- 解释:
不同数据库的事务操作,能够并发使用多线程,复制到 Slave,同一个数据库内,执行的事务,只能单线程复制;
- MySQL 5.7+:提供
半同步复制的备选方案- 之前
半同步复制的隐患:事务已经同步到 Slave,但 Master 在向 Client 返回成功之前,Master 宕机,此时,Client 会向 Slave 重新提交事务请求,重复提交;问题本质原因:Master 事务提交之后,再向 Slave 同步事务。 半同步复制新增备选方案:类似 2PC,即,Master 事务写入bin log,先同步到 Slave,收到至少一个 Slave 的响应后,再在 Master 上提交事务- 第一阶段:Master 依赖
bin log向 Slave 复制事务操作 - 第二阶段:Master 收到至少一个 Slave 响应后,
提交事务
- 第一阶段:Master 依赖
- 之前
集群:主从延时
主从延时:MySQL 的 MS 结构,采用异步复制,因此,Master 上提交的事务,Slave 同步到后,会有延时,这段时间内,Slave 跟 Master 的数据不一致,一般是 ms 级别。
主从延时的时间:Master 和 Slave 上事务提交的时间的时间差值。
具体分析:延时时间的构成:
- Master 上,事务在
bin log中排队时间;(生产者-消费者模型) 网络传输时间- Slave 上,事务
执行时间;
主要解决:
- Master 上
排队时间:业务上,减少多线程写的概率 - Slave 上事务
执行时间:业务上,拆解大事务,变为小事务
详细分析,看这里:MySQL 技术内幕:主从同步和主从延时
基础:字段类型
几个典型问题:
char(10)和varchar(10)的区别int(11)中11数字的含义
Re:分开来说
char(10)是定长的,varchar(10)是变长的char(10)字符不足 10 个,则,填充空格补齐;varchar(10)字符最长为 10,则,char(10)和varchar(10),字符超过长度约束,都会自动截断
int(10),始终是4 字节,最大值为 21 亿,其中10只控制展示样式:前向补零。
基础:日志
MySQL 的日志,分为几类:

简单说几类日志:
- 启动日志:
启动、终止,以及运行过程中的错误日志 - 通用查询日志:记录 MySQL 上,所有
Select 查询语句,不到万不得已,不要开启 - 慢查询日志:执行时间操过阈值的
Select 查询语句,借助工具mysqldumpslow命令分析 top n - 二进制日志:集群同步,只包含变更数据的
事务操作,不包含简单的查询操作- bin log:事务执行过程/状态
- relay log:事务执行过程/状态
- 引擎日志:事务执行过程
- undo log:事务操作,原子性;记录
数据变更前的状态。 - redo log:事务操作,持久性;记录
数据变更后的状态。(在 commit 之前, flush 到磁盘)
- undo log:事务操作,原子性;记录
MySQL 的 InnoDB 存储引擎,支持事务,而且支持主从同步复制,整个过程中,涉及多个日志:
bin log:精确恢复数据状态(timestamp),支持 MS 的主从同步复制relay log:Slave 上,支持主从同步复制undo log:数据变更前,先记录变更前数据到 undo log,为了防止 undo log 丢失,每次都需要 flush 到磁盘,大量的磁盘 IO,效率低;redo log:数据变更后,flush 到磁盘上之前,先将变更后数据记录到 redo log 中,事务提交之前,先把 redo log 刷新到磁盘上;
基础:bin log 日志
MySQL 的 bin log 的日志格式,有 3 种:
- statement:事务 SQL,Slave 同步之后,会重新执行 SQL,达到跟 Master 一致的数据
- row:记录每行被修改的内容
- mixed:statement 和 row 自动切换
几种 bin log 日志格式的优劣:
- statement:事务SQL
- 优点:bin log 的数据量小,节省磁盘资源,主从复制过程中,也节省了网络 IO 资源
- 缺点:bin log 中,除了记录原始的 SQL,还需要记录每一行 SQL 执行的上下文信息,保证 Slave 上能够精确的重放;MySQL 版本演进很快,SQL 比较复杂时(
last_insert_id()),主从复制出现 bug;
- row:每行数据变更内容
- 优点:主从复制精确,稳定、问题少
- 缺点:bin log 数据量大,耗费磁盘资源、网络IO资源
- mixed:根据 SQL,自动选择 statement 还是 row。
基础:锁的实现
场景:
MySQL中InnoDB引擎的行锁是通过加在什么上完成(或称实现)的?为什么是这样子的?
Re:
- InnoDB 的
行锁是添加在主索引上的; - 原因:InnoDB 的
主索引是聚簇索引,索引文件跟数据文件存放在一起,所有需要读取具体数据内容的操作,都需要经过主索引,即,主索引是唯一的数据访问入口。
基础:数据结构
B+ 树中:平衡的多路查找树
- 整体上时间复杂度,相对平衡二叉查找树,有一点优化(因为是多路查找树)
- 树高度降低
- 中间节点,二分查找
- 更多的是:中间节点,只存储索引字段,不存储数据信息,一个页(Page)内,可以存储更多的索引信息,每次页的读取,都需要一次磁盘 IO,使用 B+ 树,减少磁盘 IO 次数,节省时间。(磁盘 ms 级别)
实践:MySQL 状态异常
背景:
mysql数据库cpu飙升到500%
关键要定位问题、解决问题,具体:
- 定位进程:top (下文假设定位到了 MySQL)
- 查看 MySQL 当前执行的线程,以及状态:
show processlist,执行时长、等待锁的状态 - 其次,分析慢查询日志
实践:Explain 分析 SQL
explain 命令,分析 SQL 语句的执行计划,具体参数:
- Table:表名
- Possible_keys:可以利用的索引
- Key:索引优化器,最终选择使用的索引
- Key_len:索引键长度 (前缀匹配)
- Rows:根据系统统计信息,估计的需要扫描的行数
- Extra:补充字段
- using Index:只依赖索引文件,不需要
回表查询,例如,COUNT - using Where:需要读取具体的数据,需要
回表查询
- using Index:只依赖索引文件,不需要
更多细节参考: MySQL的 explain
实践:大字段处理
背景:
表中有大字段FieldX(例如:text类型),且字段 FieldX 不会经常更新,以读为为主
思考:拆成子表,还是继续放一起?
Re:拆成子表 + lazy-load 方式
原因:
B+树的叶子节点对应一个页- 每个页包含的数据行越多,效率越高
lazy-load方式,需要的时候,才去读取大字段
详说:
- 磁盘 IO 单位:
页(Page),其中包含多行 (InnoDB 逻辑页 16KB) 页与行数的关系:行越长,一个页能存放的行数越少;(B+树的叶子节点包含的数据行数)页的访问时机:访问一个页中的任何一行,哪怕一个字段,也要整个页IO 读出来- 大字段的业务场景受限:只有部分场景需要读取,因此,拆为
子表+lazy-load方式,需要的时候,才去读取; - 不需要读取大字段场景:拆出大字段,减少了磁盘 IO 的次数,提升效率
实践:SELECT 语句写法
背景:
2种写法
SELECT *和SELECT 全部字段有何优缺点
- 前者要解析
数据字典,后者不需要 - 结果
输出顺序:前者与建表列顺序相同,后者按指定字段顺序。 - 表
字段改名,前者不需要修改,后者需要改 - 后者的
可读性比前者要高
实践:日期字段,是否适合创建索引
MySQL 中日期类型字段有:
- datetime:8字节,日期、时间
- timestamp:4字节,日期、实践
- date:3字节,日期
- time:3字节,时间
对于日期字段,索引的使用需要特别注意:
- 日期字段,使用函数时,索引无效,会全表扫描,例如:
SUBSTR(WorkDate,1,7) = 'YYYY-MM'DATE_FORMAT(WorkDate,'%Y%m') = 'YYYYMM'
- 使用
=,会使用索引 - 使用
BETWEEN...AND...,会使用索引
因此,日期字段,创建索引时,要特别注意 SQL 优化。
更多索引使用情况,参考:如何提高查询速度
实践:唯一性索引
关于 MySQL 中的唯一性索引,2 个典型疑问:
- 实现机制:唯一性索引,是如何实现的?
- null 字段:是否可以作为唯一性索引?
唯一性索引,实现机制:
- 本质都是 B+Tree,只是节点增加额外标记,不允许重复.
null 字段:唯一性索引,是允许多个 null 值存在的。
- null 值:null 表示不确定的语义,表示任意值,null 值之间,不相等,但可以作为判断条件
- 存储引擎:所有的存储引擎,唯一性索引,都允许多 null 值存在。
具体说明:
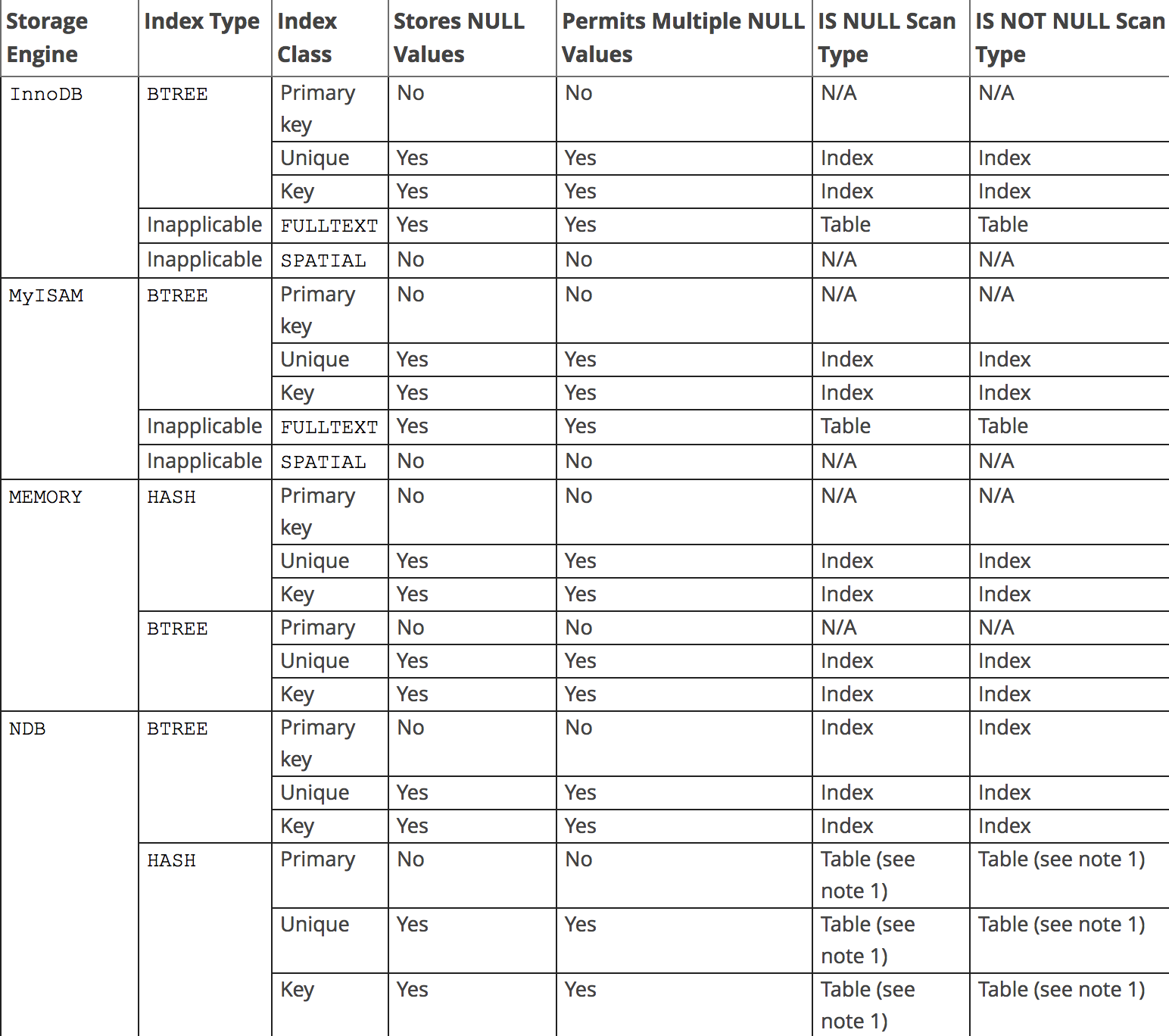
更多细节,参考:
参考资料
TODO:
- 高性能 MySQL
TODO:
- search:搜索前几个知识点,比如:zk、redis、Kafka
原文地址:https://ningg.top/mysql-best-practice-tips-collection-2/