ZooKeeper 技术内幕:数据的存储
2016-02-19
Keynote/PPT 下载:
- ZK 技术内幕:数据与存储.pdf (pdf 版)
1. 数据分类
整体分为 3 类:
- 内存数据
- 磁盘数据
- 快照
- 事务日志
下面是 ZooKeeper 启动过程中,3 类数据之间的关系:
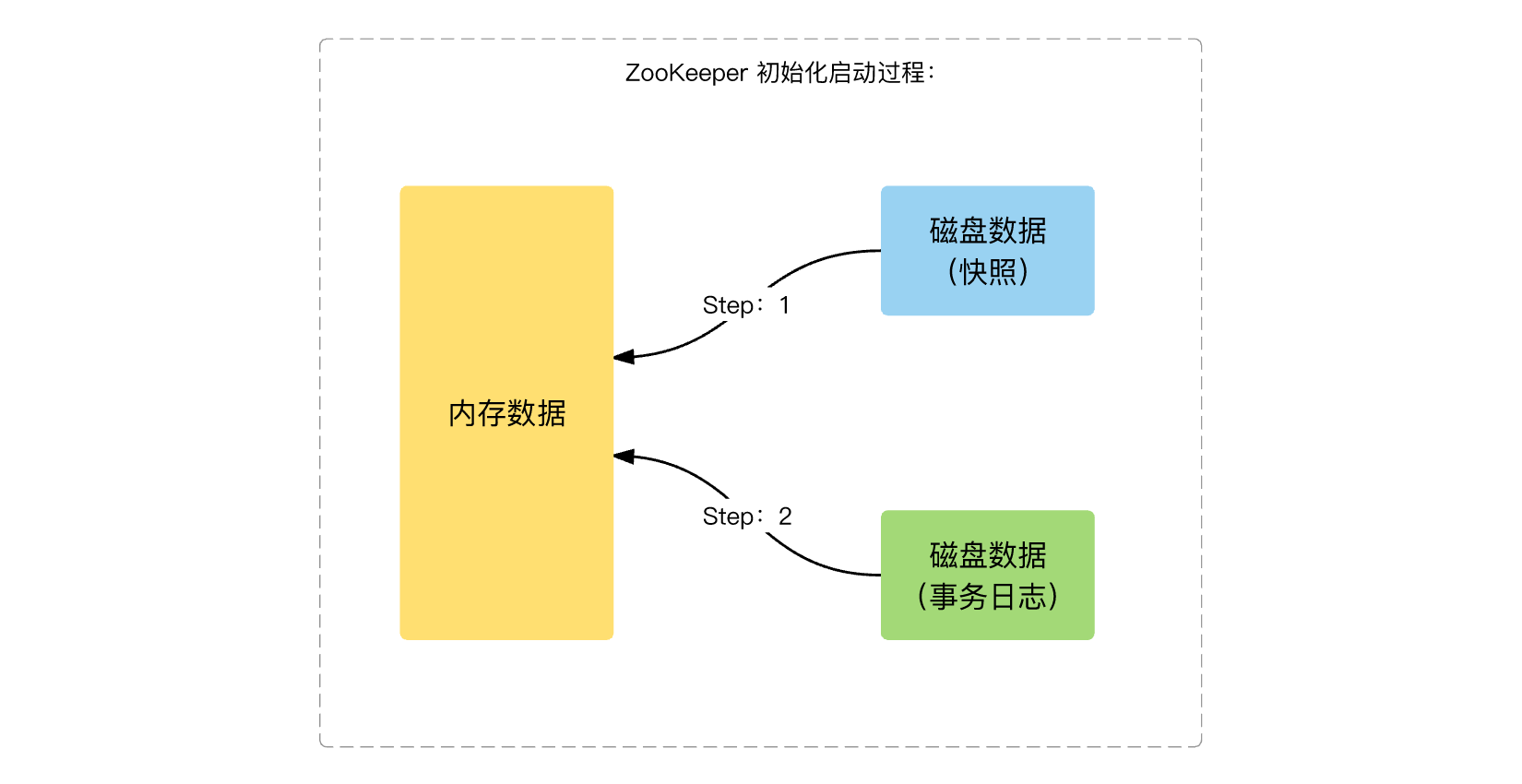
1.1. 内存数据
关键点:
- ZK 的数据模型:
树- 树中单个节点包含的内容:
- 节点数据
- 节点 ACL 信息
- 节点的路径
- 树中单个节点包含的内容:
- 具体实现:DataTree 和 DataNode,见下图
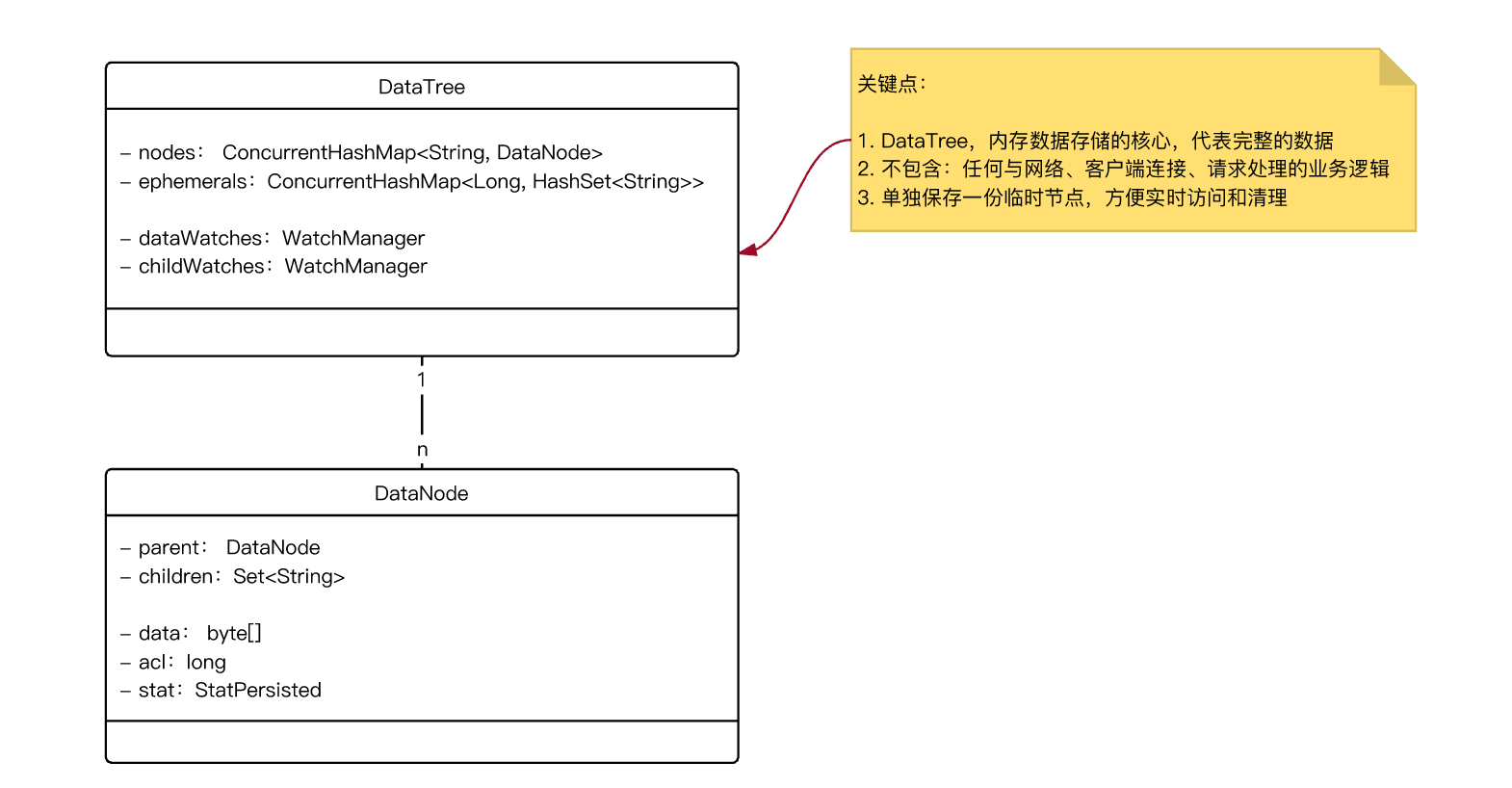
抛出 2 个问题:
- DataTree 中 nodes 是 Map,表示所有的 ZK 节点,那其内部 key 是什么?
- Re:ZNode 的唯一标识
path作为 key
- Re:ZNode 的唯一标识
- ephemerals 是Map,用于存储临时节点,那其内部 key 是什么?value 又是什么?
- Re:临时节点是跟 Session 绑定的,sessionId 作为 key
懂的,都是看过源码的。
1.2. 快照数据
快照数据生成的基本过程:

关键点:
- 异步:异步线程生成快照文件
- Fuzzy 快照:
- 快照文件生成过程中,仍然有新的事务提交,
- 因此,快照文件不是精确到某一时刻的快照文件,而是
模糊的, - 这就要求
事务操作是幂等的,否则产生不一致。
疑问:是否每次生成快照文件,都会认为「事务日志已经写满」,并切换一次事务日志文件?所以,切换事务日志文件的时机,实际是生成快照文件的时机。
1.3. 事务日志
关键点:
- 事务日志频繁 flush 到磁盘,消耗大量磁盘 IO
- 磁盘空间
预分配:事务日志剩余空间 < 4KB 时,将文件大小增加 64 MB 磁盘预分配的目标:减少磁盘 seek 次数- 建议:事务日志,采用
独立磁盘单独存放
疑问:事务日志每次增长 64MB,什么时候切换新的事务日志?
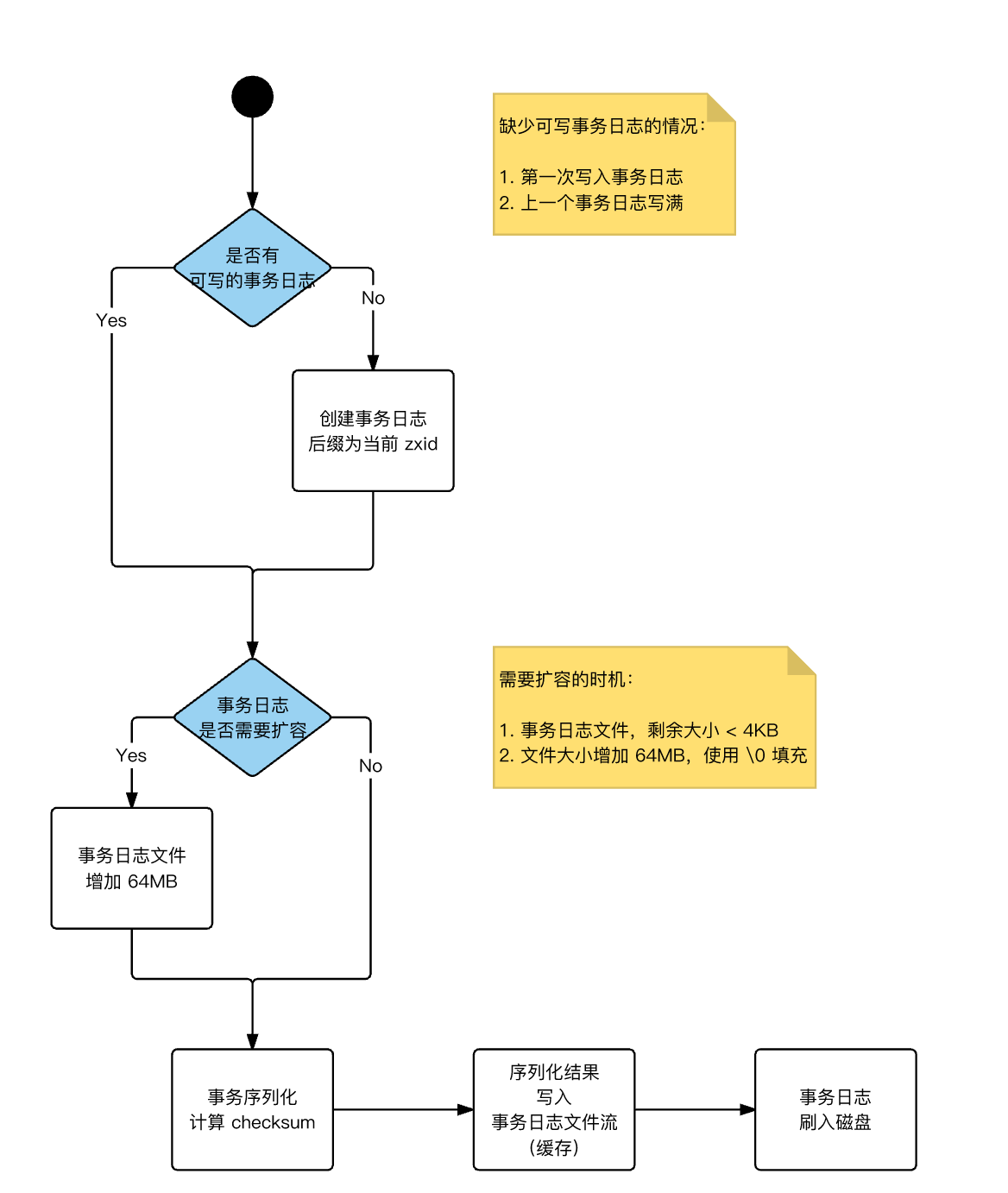
事务序列化:本质是生成一个字节数组
- 包含:事务头、事务体的序列化
- 事务体:会话创建事务、节点创建事务、节点删除事务、节点数据更新事务
日志截断:
- 现象:Learner 的机器上记录的 zxid 比 Leader 机器上的 zxid 大,这是非法状态;
- 原则:只要集群中存在 Leader,所有机器都必须与 Leader 的数据保持同步
- 处理细节:遇到非法状态,Leader 发送 TRUNC 命令给特定机器,要求进行日志截断,Learner 机器收到命令,会删除非法的事务日志
2. 数据相关过程
2.1. 初始化
ZK 服务器启动时,首先会进行数据初始化,将磁盘中数据,加载到内存中,恢复现场。
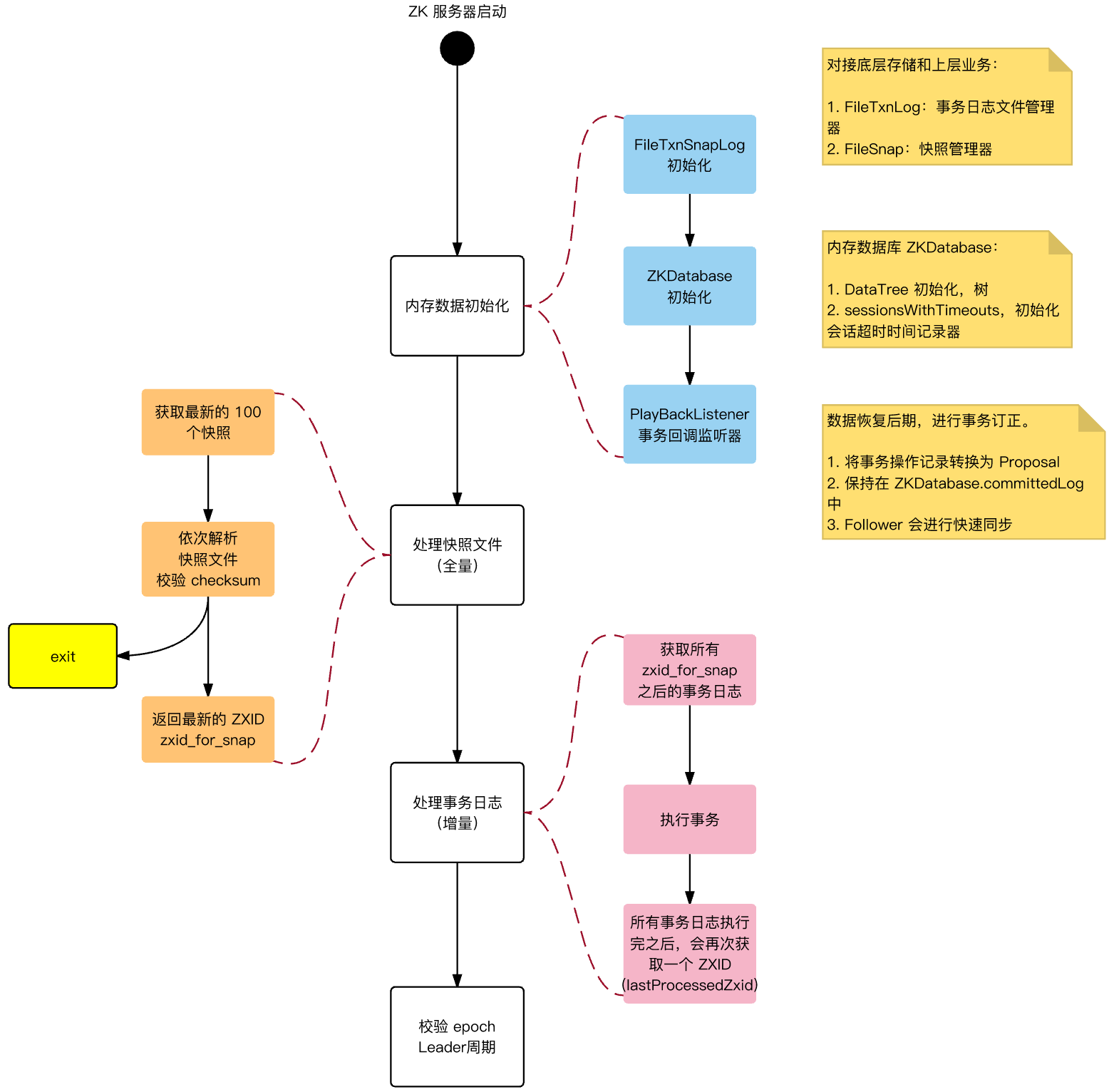
疑问:初始化最后,为什么要校验 Epoch?如何判断校验成功失败?如果失败,如何处理?
2.2. 数据同步
ZK 集群服务器启动之后,会进行 2 个动作:
- 选举 Leader:分配角色
- Learner 向 Leader 服务器注册:数据同步
数据同步,本质:将没有在 Learner 上执行的事务,同步给 Learner。
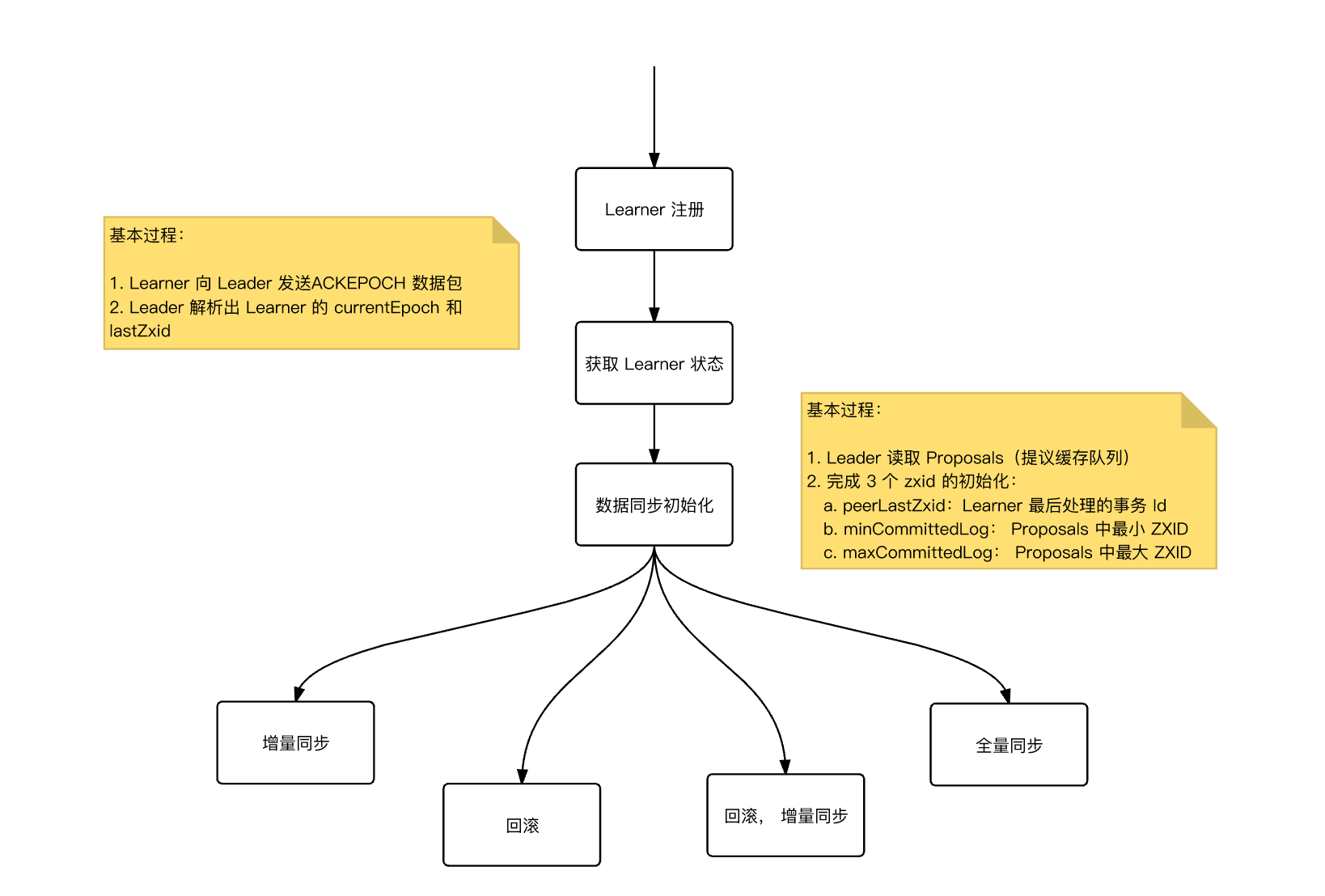
关键点:
- 集群启动后,什么时候能够对外提供服务?需要等所有 Learner 都完成数据同步吗?
- Re:
过半策略:只需要半数 Learner 完成数据同步,Learder 向所有已经完成数据同步的 Learner 发送 UPTODATE 命令,表示集群具备了对外服务能力
- Re:
几种同步:
- 增量同步
- 回滚
- 回滚,增量同步
- 全量同步
下面一张图,能够清晰描述发生上述同步的时机:
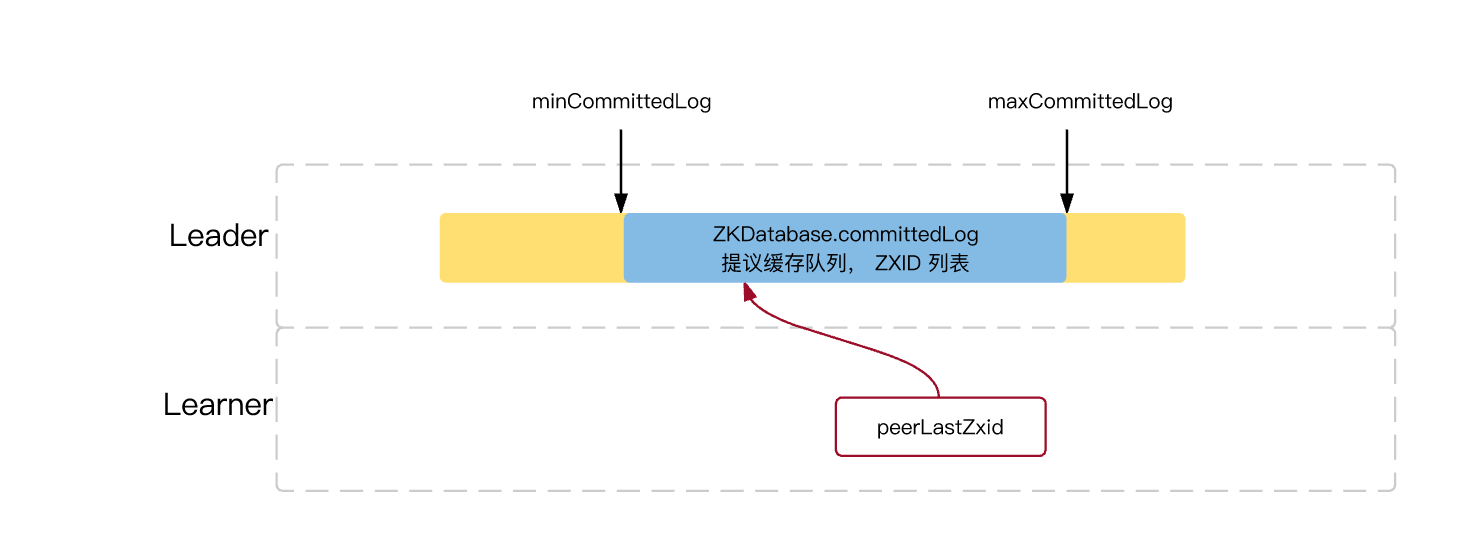
关键点:Learner 上的 zxid 与 Leader Proposals 中 min 和 max 的关系
3. 总结
ZK 的数据与存储中,有几个特别关注点:
内存数据与磁盘数据间的关系:- 内存数据,是真正提供服务的数据
- 磁盘数据,作用:
- 恢复内存数据,恢复现场
- 数据同步:集群内,不同节点间的数据同步(另,内存中的提议缓存队列 proposals)
- 磁盘数据,为什么同时包含:快照、事务日志?出于数据粒度的考虑
- 如果只包含快照,那恢复现场的时候,会有数据丢失,因为生成快照的时间间隔太大,即,快照的粒度太粗了
- 事务日志,针对每条提交的事务都会 flush 到磁盘,因此粒度很细,恢复现场时,能够恢复到事务粒度上
- 快照生成的时机:基于阈值,引入随机因素
- 解决的关键问题:避免所有节点同时 dump snapshot,因为 dump snapshot 耗费大量的 磁盘 IO、CPU,所有节点同时 dump 会严重影响集群的对外服务能力
countLog > snapCount/2 + randRoll,其中:- countLog 为累计执行事务个数
- snapCount 为配置的阈值
- randRoll 为随机因素(取值:0~snapCount/2)
- ZK 的 快照文件是 Fuzzy 快照,不是精确到某一时刻的快照,而是某一时间段内的快照
- ZK 使用「异步线程」生成快照:
- 线程之间共享内存空间,导致 Fuzzy 快照
- 这就要求 ZK 的所有事务操作是幂等的,否则产生数据不一致的问题
- 实际上 ZK 的所有操作都是幂等的
- 类比:Redis 中使用「异步进程」生成快照 RDB(Redis Dump Binary)
- RDB 文件是精确的快照,原因:进程之间内存空间隔离
- 系统内核使用「写时复制」(Copy-On-Write)技术,节省大量内存空间
- ZK 使用「异步线程」生成快照:
参考资料
- 从Paxos到Zookeeper分布式一致性原理与实践 第7章 7.9
- ZooKeeper-Distributed Process Coordination 第2章 2.1.3 & 第4章
原文地址:https://ningg.top/zookeeper-lesson-9-zookeeper-data-and-storage/