Apache Kafka 0.10 技术内幕:MQ 的价值
2016-03-14
目标
上一篇提到,Kafka 定位是:流式数据的平台,其中一个典型作用是:MQ(Message Queue,消息队列)。
开始介绍 Kafka 之前,先介绍一下 MQ 的作用:
- 系统没有 MQ 能不能运行?
- 引入 MQ,对系统有哪些好处?
- 引入 MQ,有哪些成本?
Note:Kafka 只是 MQ 的一种典型实现,还有很多的 MQ 方案,会单独整理一个不同 MQ 之间的对比。
MQ 的作用
典型场景
先看一个典型场景:
场景:收集不同机器上的日志,送入 Storm 流式处理引擎,进行准实时的分析。
不引入 MQ 时,最简单的方式:
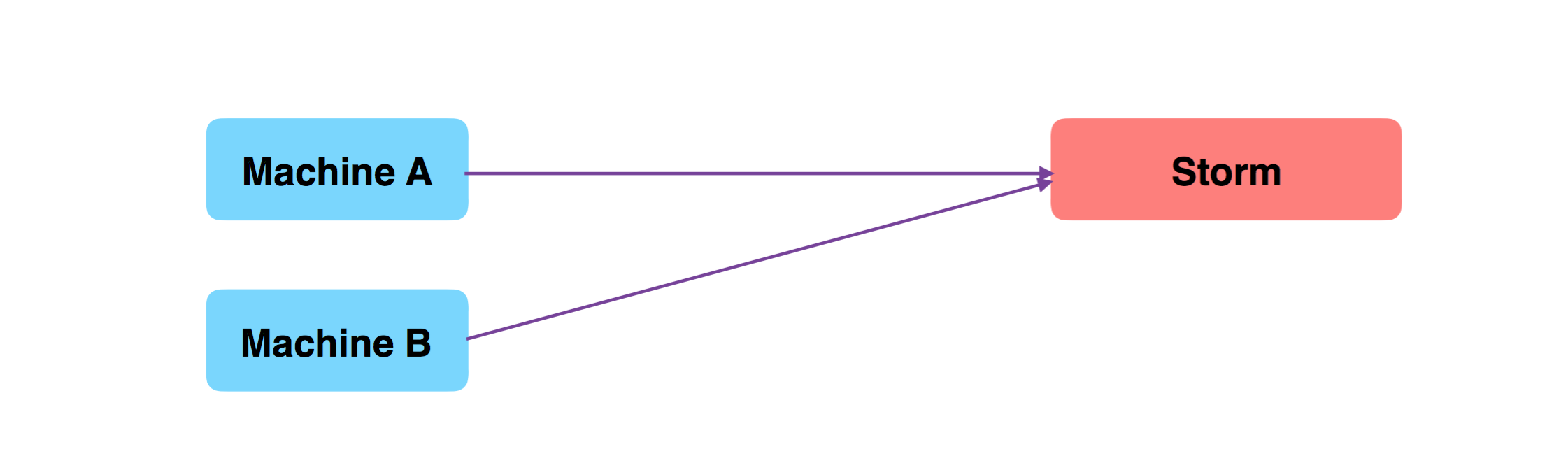
现在,因为业务需要,考虑将原始收集的数据,也存储一份到 HDFS 中,因此,需要变更所有 Machine 上的 Agent,将日志文件同时送入 HDFS 一份,效果如下图:
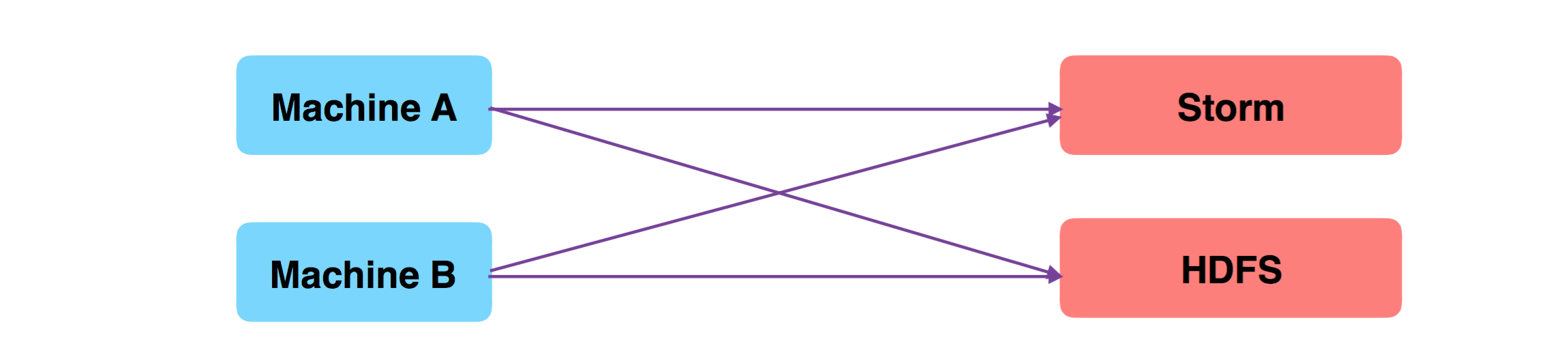
现在,因为业务需要,考虑将收集的数据经过 ETL 之后,快速送入 Spark Streaming 流式引擎,进行模型的挖掘和预研,我们又要调整所有 Machine 上的 Agent,将日志送入 Spark Streaming 一份,效果如下图:
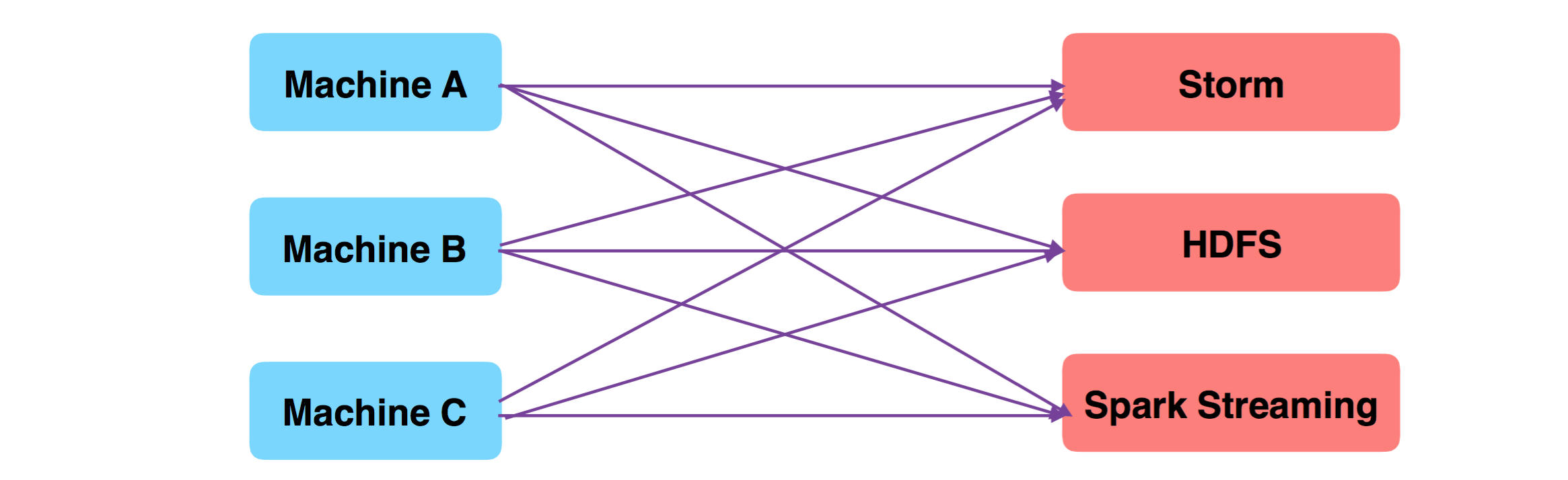
上面问题,就是系统的扩展性很差:
- 每次有新的业务变更,都需要调整所有 Machine 的 Agent;
- 如果 Sparking Streaming 预研结束了,需要停止 Machine Agent 向 Sparking Stream 发送数据,就有需要调整所有 Machine Agent;
- 如果 Machine 的数量非常多,1k+,那调整的工作量就无法忍受;
上面问题的本质原因:
数据
生产者(Producer)跟数据消费者(Consumer)之间耦合度高。
Consumer的变更,会影响ProducerProducer的变更,会影响Consumer
MQ 的作用
使用 MQ 实现:数据生产者(Producer)跟数据消费者(Consumer)之间解耦。
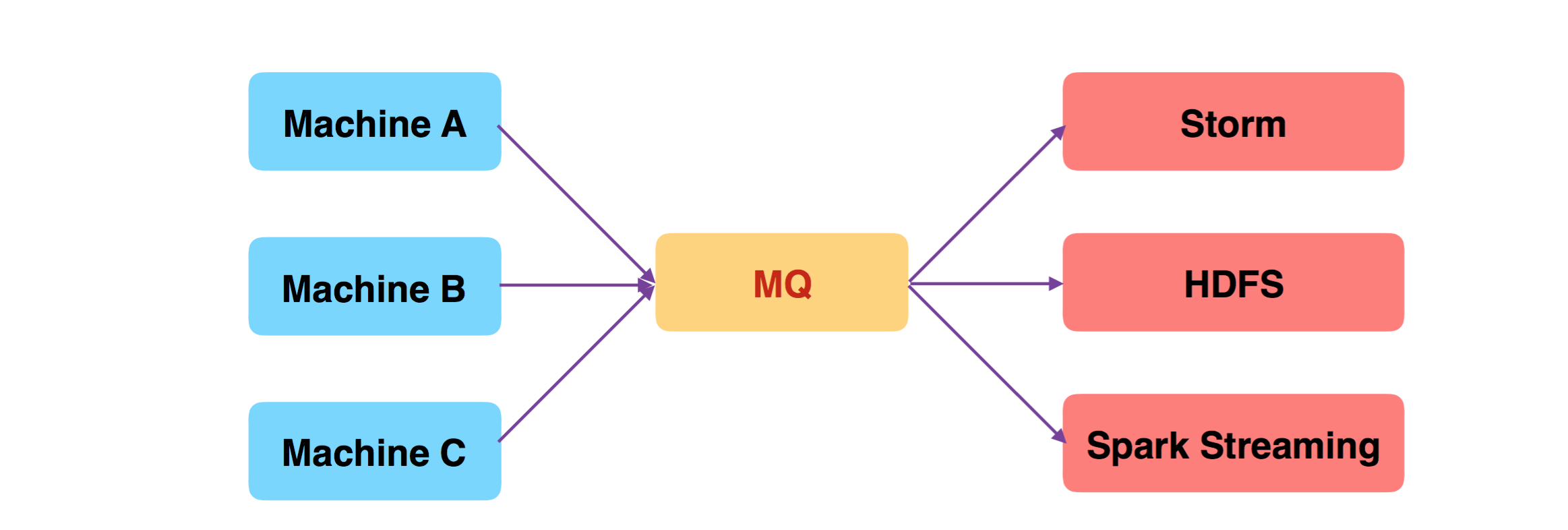
解耦带来的好处:系统具有良好的可扩展性和可靠性。
- 新增或删除 Producer 和 Consumer 对现有系统的影响很小;
- Consumer 宕机重启后,仍能够不丢失数据;(MQ 中缓存了数据)
此外,MQ 还用于解决下述问题:
- 平滑突发峰值:系统突发处理能力不足,平均处理能力可以,MQ 平滑突发峰值
- 异步任务:耗时的任务
更多 MQ 的使用场景,参考:Top 10 Uses For A Message Queue (Note: 其中 10 类 MQ 典型应用场景,有一些是重叠的)。
小结一下:
MQ 的作用:
- 通过解耦 Producer 和 Consumer,提升系统的可扩展性和可靠性
- 平滑突发峰值
- 异步任务
参考资料
- Kafka 官网
- Top 10 Uses For A Message Queue
- Kafka a Distributed Messaging System for Log Processing
- Learning Apache Kafka(2nd Edition)
- Kafka 设计解析-郭俊
原文地址:https://ningg.top/apache-kafka-10-mq-value/