基础原理系列:LRU Cache 原理
2016-08-16
1.概述
LRU ,几个方面:
- 算法的基本要求
- 基本思路
- 几个相关实现:
HashMap、LinkedHashMap、ConcurrentHashMap,以及底层实现机制
2.LRU 剖析
LRU:Least Recently Used,最近最少使用。判断最近被使用的时间,目前最远的数据优先被淘汰。
2.1.基本要求
基本要求:
- 一个内存空间:设置缓存空间大小,创建一个空间,空间的大小受传入参数的控制
- 支持通用操作:
get、set,时间复杂度都为O(1) - 支持特殊操作:
set key时,如果空间不足,自动失效最久远的 key,时间复杂度为O(1),实际是覆盖更新
2.2.基本思路
基本思路:
- LRU算法是根据数据的访问历史来进行淘汰的,总会优先淘汰哪些最近未被访问活着访问率低的数据。
- 其实现过程是建立在
链表的基础上的,- 新加入的数据,放在链表的头部,
- 当原来链表中的数据被访问时,该数据也会被移到链表头部,
- 而那些最近未被访问的数据自然就移到了链表的尾部
- 当链表满需要淘汰数据时,就会移除尾部的数据,腾出空间,供新数据插入。
实现过程如图:
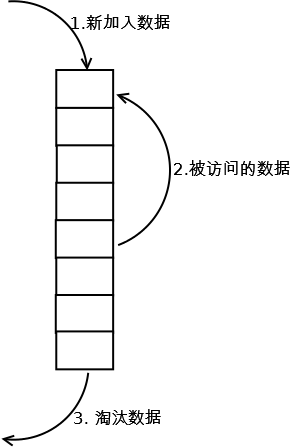
当存在热点数据的时候,命中率很高。
上述基本思路,本质:
- 缓存存储:HashMap 存储,get、set 都是 O(1) 时间复杂度
- 缓存失效:
- 元素之间,采用「链表」形式,双向链表,方便元素调整
- 首尾指针,两端采用指针:尾部指针,缓存满的情况下,优先删除;头部指针,新增元素或新访问原始,插入头部
具体落地实现细节:
- 查找(GET)操作
- 若找到对应节点node,将其从链表中删除,然后,再将其插入到「双向链表表头」
- 返回node的value值
- 根据键值查找hashmap,如果没找到直接返回 null
- 若找到对应节点node,将其从链表中删除,然后,再将其插入到「双向链表表头」
- 插入(SET)操作:
- 根据键值查找hashmap:
- 如果找到,则,直接将该节点移到表头即可
- 如果没有找到,首先判断当前Cache是否已满
- 如果已满,则,删除表尾节点
- 如果未满,则,不用删除节点
- 将新节点插入到表头
- 根据键值查找hashmap:
双向链表的几个操作:
- 中间删除:从其中间,删除元素
- 尾部删除:在尾部,删除元素
- 头部插入:在头部,插入元素
更多细节,参考:LRU算法
几个典型实现:
- 基于 LinkedHashMap 实现
- 基于双向链表 + HashMap 实现
说明:
- 上述 2 种方式,已经在 Algorithm(github)上编写完成。
3.附录
3.1.附录:几个 Map 的底层实现
几个:TODO
- HashMap
- LinkedHashMap
- ConcurrentHashMap
3.2.附录:LRU 基本实现思路
LRU 几种实现思路:
- 时间戳排序方式:时间戳更新,每个 key 维持一个最新访问时间,按照时间升序排列,删除时间最早的数据;需要额外维护时间戳,并且需要排序
- 链表方式:利用链表,最新插入和最新读取的 key,移动到链表头部,从链表尾部开始删数据;数据读写,时间复杂度为
O(n) - 链表 + Map 方式:利用链表,记录元素的访问顺序;利用 Map,存储元素,实现数据读写 O(1) 时间复杂度
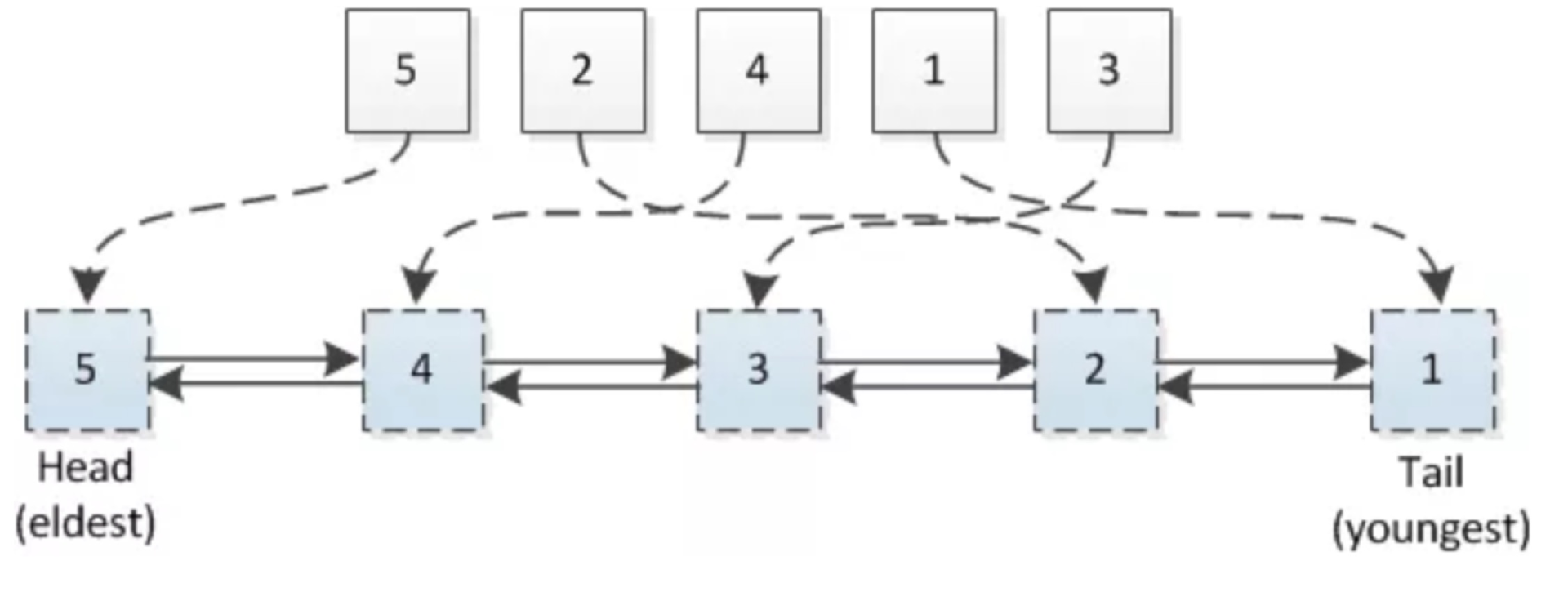
Tips:
- 双向链表,维护元素的增加、删除
- 头部:删除
- 尾部:增加
4.参考资料
原文地址:https://ningg.top/computer-basic-theory-lru-cache-theory/