实验平台:设计--分桶
2017-07-04
实验平台,具体落地过程,涉及到一些通用问题,当前 blog 将进行详细的讨论:
分流路由策略(分桶)
分桶的作用?
- 流量的组织粒度:最小粒度为一个分桶;
- 均匀分布:分桶的算法,要足够分散,避免数据倾斜;
- 作用:是基础设施,支撑流量动态伸缩,借助
shuffle实现流量的完全正交,同时,借助伪 shuffle支持用户积累效应的实验;
分桶的实现细节:
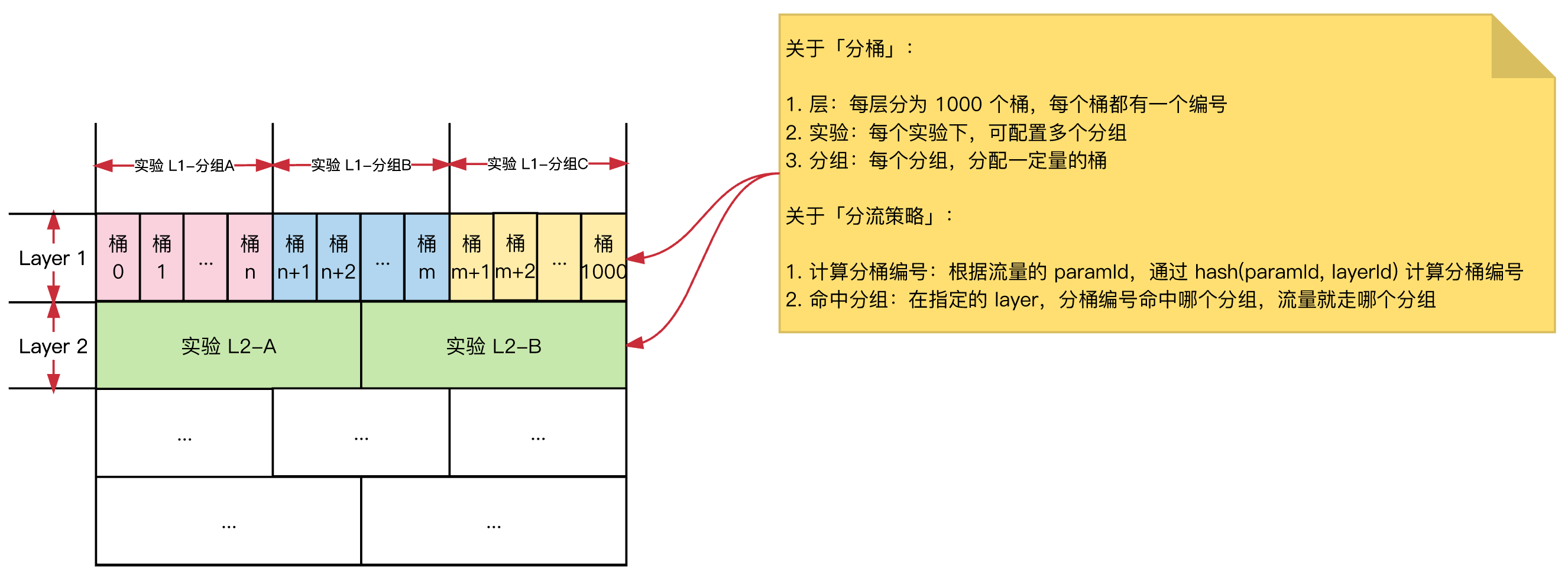
从应用角度,几个考虑点:
- 同一个 userId,在不同的访问时间,是否命中相同的实验和分组?
- 用户体验的一致性
针对所有的流量,常见分流路由策略:
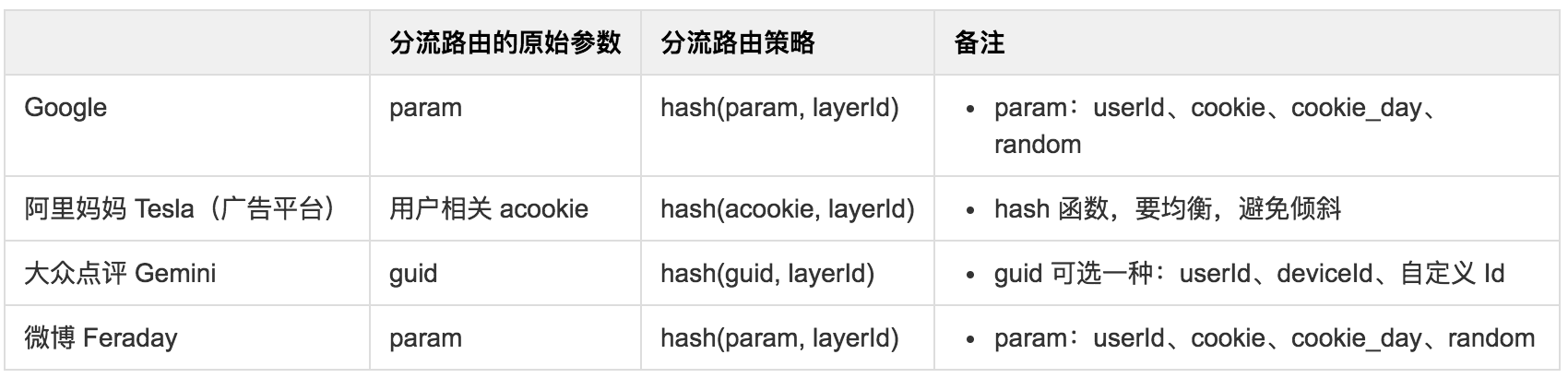
分流路由参数介绍:
- 流量完全随机:random
- 最简单的分流方式,流量随机命中各个实验和分组;
- 用户标识id 的哈希:hash(userId)
- 同一个用户会一直命中同一实验,从而保证了用户体验的一致性;
- 对同一用户具有累积效应的策略的实验需求;
- 用户标识id+日期的哈希:hash(userId_day)
- 流量划分在跨时间维度上更为均匀;
- 用户请求,跨时间区间时,用户体验不一致;
- 用户id尾号划分:userId 尾号
- 常用、很简单的分流方式,保证了用户体验的一致性;(用户的累计效应)
- 可能会由于尾号分布的不均匀性而造成流量分布的不够均匀,影响实验的可对比性;
- 一种折衷方案是,根据用户标识 id「中间若干位」来进行流量的划分;
Note:
- 白名单机制:指定如果用户命中指定的实验和分组;
常用 Hash 算法:
- MD5 + Modulo:先 MD5 再取余
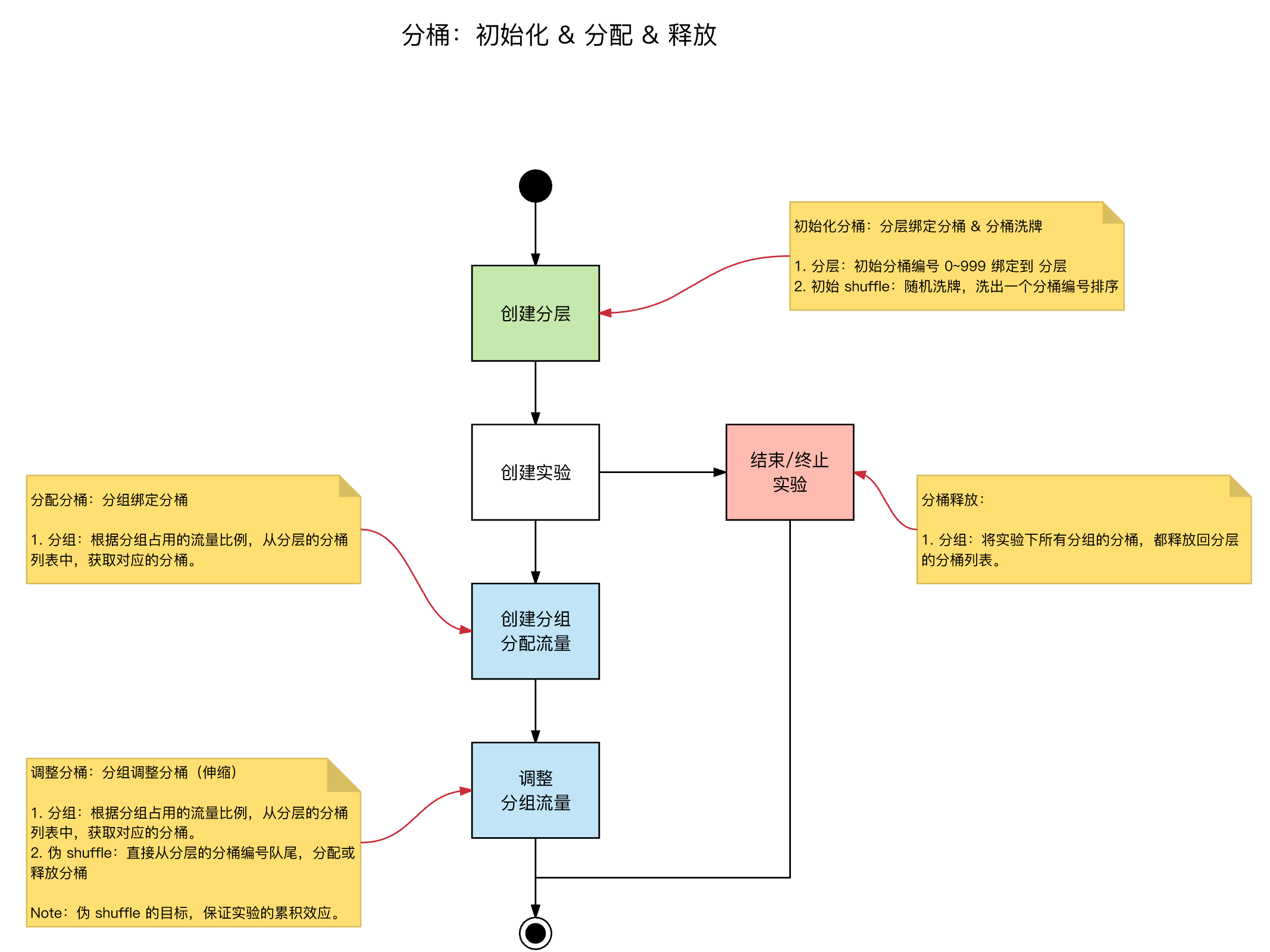
分桶实现细节
分桶的初始化、分配、调整、释放,都是在 Experiment Server 侧进行,核心过程,参考下文示意图:
在 Experiment Client 侧,「使用分桶」的示意图:
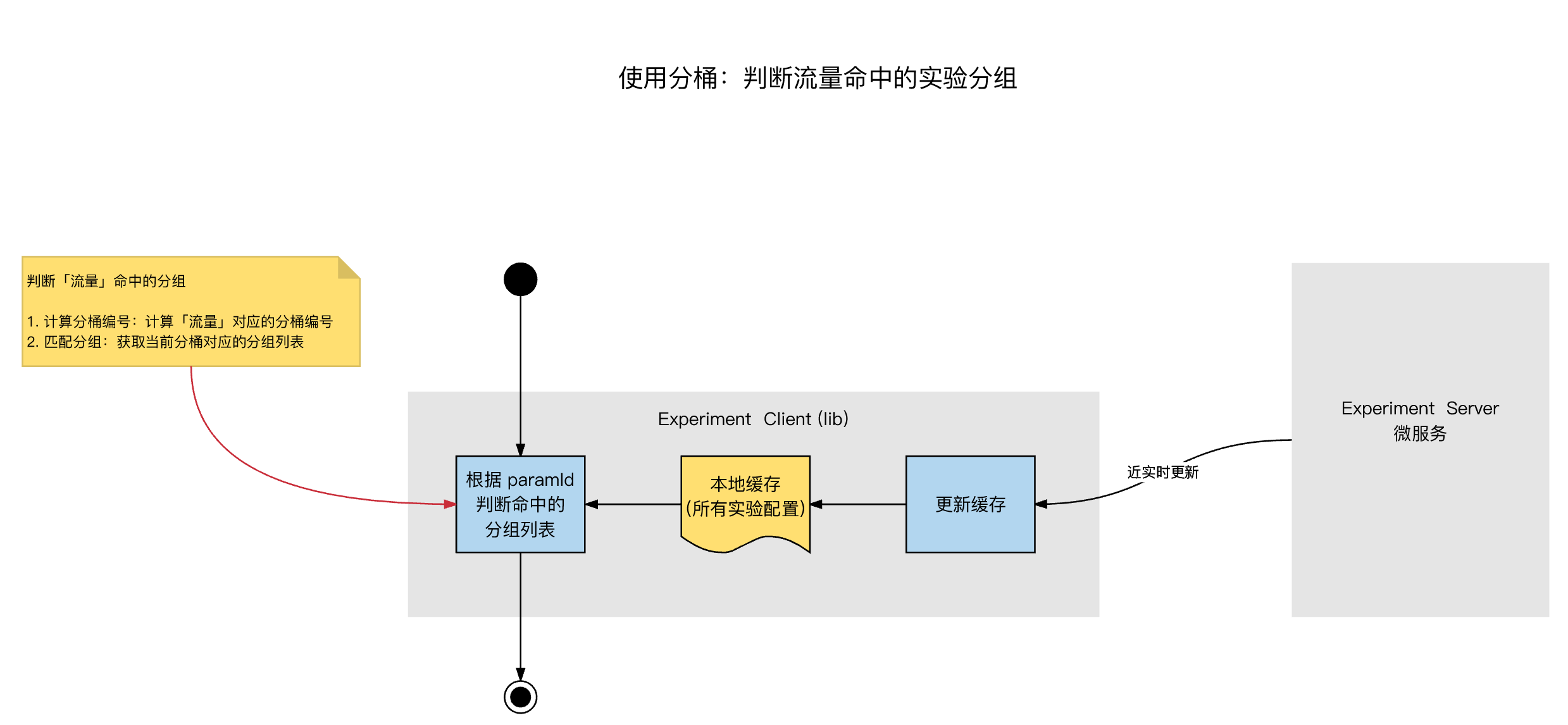
分层 & 分桶的核心算法(判断流量命中哪个分桶):
/**
* 分流策略(计算流量对应分桶的编号)
*
* @param paramId 参数Id: 流量的标识
* @param layerId 分层Id
* @return 流量对应分桶编号.
*/
public static int getBucketNo(String paramId, Integer layerId) {
// 计算 MD5
String destKey = (StringUtils.isNotBlank(paramId) ? paramId : "") + String.valueOf(layerId);
String md5Hex = DigestUtils.md5Hex(destKey);
long hash = Long.parseUnsignedLong(md5Hex.substring(md5Hex.length() - 16, md5Hex.length() - 1), 16);
if (hash < 0) {
hash = hash * (-1);
}
// 取模
return (int) (hash % BUCKET_TOTAL_NUM);
}
参考资料
- 阿里妈妈大规模在线分层实验实践
- 超越AB-Test,算法参数化与Google实验架构
- 大众点评并行 AB 测试框架 Gemini
- Experiments at Airbnb
- 微博广告分层实验平台(Faraday)架构实践
- Overlapping Experiment Infrastructure- More, Better, Faster Experimentation.pdf
原文地址:https://ningg.top/experiment-series-flow-router/