Java 剖析:基础汇总(1)
2015-02-15
0.概要
整体几个方面:
- Object 和 Class
- Enum 枚举的实现
- String 的实现
- 泛型:底层实现
- 异常处理
- 集合类:HashMap、HashTable、ConcurrentHashMap、LinkedHashMap
- 线程池
1. Object 和 Class
Object 自带的方法:
getClass():获取运行时类clone():完成对象的复制equals():默认判断==,基本类型的值、对象的引用地址,hashCode():获取对象hashcode,方便 HashMap 和 HashTabletoString():对象的字符串表示wait():当前线程,挂起等待notify():唤醒其他在当前对象上等待的一个线程notifyAll():唤醒其他在当前对象上等待的所有线程,此时,多线程并发访问,不一定是线程安全的;
获取 Class 的方法:
- Object.getClass()
- Class.forName(“class 的全限定名”)
- 类名.class
拓展:equals() 方法,重写注意事项
- 要同时重写 hashCode() 方法,equals() 相等的前提,是 hashCode() 方法相等
- 原因:多数场景下,比较两个对象 equals 是否相等之前,会先判断 hashCode() 相等,例如 HashMap
更多细节:
2. Enum 枚举的实现
特性:静态常量,单例,
构造方法是private,内部属性name 和 ordinal 都是final的常量,无法修改
作用:相比于「静态常量」,枚举作为「静态常量类」,优点
- 安全性:类型安全,执行过程中,无法二次赋值 or 创建新的实例
- 语义性强:能够表达丰富语义,内部可以定义
desc等属性,
更多细节:
3. String 的实现
String、StringBuffer、StringBuilder
- 相同点:都是
final class,都不能被继承 - 不同点:
- String,
final char[] value,字符串常量 - StringBuffer、StringBuilder,
char[] value,字符串变量 - StringBuffer 线程安全,StringBuilder 非线程安全
- String,
更多细节:
4. 泛型:底层实现
不用泛型:可以直接用 Object 替代,然后,使用时,类型强制转换
泛型的作用:
- 安全性:在
编译期,进行类型匹配检查 - 可读性:避免手动的强制类型转换,强制类型转换是强制的、自动的,代码可读性好
- 代码重用:安全性和可读性更高
底层实现,细节:
- 类型检查:在
编译期,进行类型检查 - 类型擦除:在
编译期,自动转换为「强制类型转换」,同时,擦除泛型 - 泛型类:泛型类,只会生成一个
class 字节码文件,其中不包含泛型概念,底层是 Object 类型- 一个泛型类:底层是同一个 class 文件,泛型参数底层对应的是 Object 类型
- 调用类:生成的字节码中,
- 编译时,强制类型转换,插入字节码中
- 运行时,进行强制类型转换
更多细节:
5. 异常处理
关于 Error、Exception、RuntimeException:
- 所有类的共同父类:Throwable 类
- Error,不可恢复的错误,OutOfMemoryError、StackOverflowError、NoClassDefFoundError
- Exception,受检异常,需要程序主动捕获,IOException,FileNotFoundException
- RuntimeException,运行时异常,不强制程序捕获,NPE、数组越界 IndexOutOfBoundsException
关于异常处理机制,沉淀一套统一异常处理的经验:
- 对内,异常栈、错误日志
- 对外,用户展示的引导信息,一般需要定制
- 转换:统一异常处理机制 ControllerAdvice、ExceptionHandler,统一进行异常的转换,将「内部异常」转换为「对外提示」同时,记录错误日志
更多细节:
6. 集合类
几个方面:
6.1. HashMap
底层:数组链表
- JDK 1.8 开始,如果「链表长度」>= 8 ,且容量 capacity >= 64,升级为红黑树
- 存储时,key 会进行 2 次 hash,key.hashCode() 和 基于 hashCode 的移位后的异或操作。
- key 为 null 时,存储在「数组首位位置」
扩容:
- 初始容量:16,负载因子:0.75
- 扩容时机:当前 HashMap 中存储的「元素数量」>= 容量 x 负载因子
- 扩容规则:每次扩充为原来的 2 倍
- 扩容细节:重新遍历「数组链表」,并逐个元素,放置到「新的数组链表」中
Hash 冲突时:
- JDK 1.8 开始,在「链表尾部」增加节点
- JDK 1.8 之前,在「链表头部」增加节点
线程安全问题:非线程安全
- JDK 1.8 之前,是「数组链表」+「头部插入元素」
- 扩容:
- 需要重新计算 hash 值、索引位置
- 数组链表中,「单链表内」元素相对顺序,会发生变化,翻转
- 并发扩容链表成环:多线程添加元素,都触发扩容时,会潜在产生「单链表成环」的问题
- 扩容:
- JDK 1.8 之后,是「数组链表」+「尾部插入元素」
- 扩容:
- 不需要重新计算 hash 值, 采用和扩容后容量进行&操作来计算新的索引位置,因为是 2 倍扩容(「当前偏移量」 或者 「oldLen」 + 「当前偏移量」)
- 数组链表中,「单链表内」元素相对顺序,不会发生变化
- 底层存储:引入红黑树,提升查询效率
- 升级为红黑树:单链表长度达到 8(涵盖 8)时,会升级为红黑树存储
- 降级为单向链表:红黑树节点数量小于等于 6(包括 6)时,会降级为单项链表
- 扩容:
更多细节:
- http://ningg.top/java-collection-interface/
- https://blog.csdn.net/qq_33256688/article/details/79938886
- https://www.itcodemonkey.com/article/9697.html
- http://www.importnew.com/22011.html
- https://www.zhihu.com/question/68111032
6.2. HashTable
底层:数组链表
几个细节:
- key 不允许为
null,否则抛出异常 - 定位数组下标时,只进行一次 hash:
key.hashCode(),然后再定位数组下标 - reHash 时,按照
2 x oldCapacity+1进行扩容 - 线程安全,put、get 操作,都添加了
synchronized修饰 - 单链表过长时,不会自动升级为红黑树
6.3. ConcurrentHashMap
概要:JDK1.7 和 JDK 1.8 之间的实现细节,差异非常大
- JDK 1.7:
Segment数组,分段锁,然后,数组链表方式,降低锁的粒度,以此提升并发度 - JDK 1.8:放弃了 Segment 分段锁机制,采用
CAS+synchronized,底层采用数组链表 + 红黑树的存储方式
实现细节:
put(key, value)时,key 也是进行 2 次 hash 操作,跟 HashMap 类似- 并发插入元素 or 更新元素:
- 场景 A:数组对应链表为 null 时,采用
CAS更新,若更新失败,则,自旋进入「场景 A」或「场景 B」 - 场景 B:数组对应链表不为 null 时,针对「数组下链表头元素」加锁
synchronized,然后,遍历链表,并在尾部追加元素 or更新元素
- 场景 A:数组对应链表为 null 时,采用
- 扩容:
更多细节:
- https://www.jianshu.com/p/c0642afe03e0
- https://www.jianshu.com/p/f6730d5784ad
- https://blog.csdn.net/hao_yunfeng/article/details/82535009
6.4. LinkedHashMap
底层原理:
继承 HashMap,同时,内部
Entry节点,包含 2 个指针,构成双向链表
7. 线程池
几个参数:
- 核心线程数
- 最大线程数
- 空闲线程最大存活时间
- 线程排队队列
- 队列拒绝策略
- 线程工厂:生成线程池里的 worker 线程
更多细节:
8. ThreadLocal
ThreadLocal 几点:
- 作用:线程本地变量,线程之间资源隔离,解决线程并发时,资源共享的问题;
- 实现:
- 每个 Thread 都绑定了一个
ThreadLocalMap - ThreadLocal 的 set、get,都是针对 Thread 的
ThreadLocalMap进行的 ThreadLocalMap中,Entry[] table:ThreadLocal作为key,定位到Entry- ThreadLocal 存储的
value作为value - Entry 中,同时存储了
key和value - 数据存储时, Entry 数组,出现Hash,采取
避让(开放寻址)策略,而非数组拉链(开放链路)策略 Entry[]数组,初始长度为 16;大于 threshold 时,2 倍扩容。Entry[]数组中,对key是弱引用(WeakReference),key就是ThreadLocal对象自身- ThreadLocal 变量被回收后,Entry 和 Value 并未被回收;
- ThreadLocalMap 只是用于存储的,供其他地方使用;
- 如果其他地方不再使用这个 ThreadLocal 对象了,由于其为弱引用,因此,其弱引用被自动置为 null,即,key 被置为 null;
- 但,Value 是强引用,仍然没有被回收,存在内存泄露问题;
- Key 由于为弱引用,被置为 null 后,在 ThreadLocal 的 get、set 方法调用时,会消除 key 为 null 对应的 value 的强引用,避免内存泄露;
- 上述弱引用对应的 Entry,什么时候回收?get()、set() 会回收 Entry;
- 内存泄漏问题:如果 ThreadLocal 不再使用了,但一直未调用 get、set 方法,则,内存泄漏;当然,如果线程彻底销毁,对应 ThreadLocal 会被回收,但在此之前,内存泄露;
- 线程池问题:线程一直存活,下一次使用的时候,获取上一次使用时,设置的 threadLocal 变量,建议:使用之前先清理一次 threadLocal 变量;
- 每个 ThreadLocal 都用于存储一个变量,ThreadLocalMap 中,可以存储多个变量
- 每个 Thread 都绑定了一个
ThreadLocal 在内存中的存储关系:
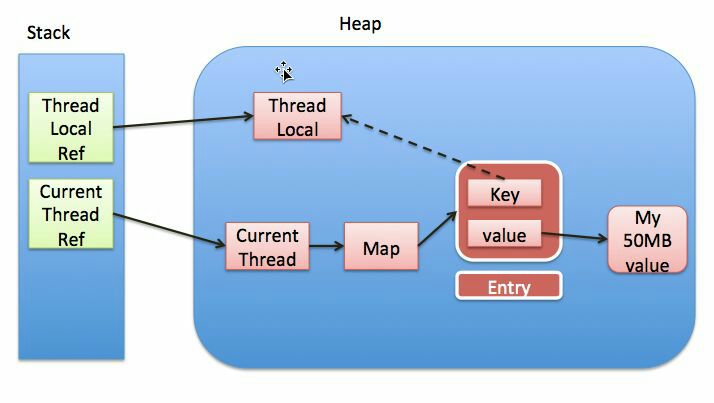
关于强引用(Strong)、软引用(Soft)、弱引用(Weak)、虚引用(Phantom):
- 强引用:我们平时使用的引用,
Object obj = new Object();只要引用存在,GC 时,就不会回收对象; - 软引用:还有一些用,但非必需的对象,系统发生内存溢出之前,会回收软引用指向的对象;
- 弱引用:非必需的对象,每次 GC 时,都会回收弱引用指向的对象;
- 虚引用:不影响对象的生命周期,每次 GC 时,都会回收,虚引用用于在 GC 回收对象时,获取一个系统通知。
更多细节,参考: Java并发:ThreadLocal
9. 多线程
Java 下,多线程协作,常用的 2 个类:
- CountDownLatch:主线程,等待子线程
- CyclicBarrier:子线程之间,相互等待
CountDownLatch 被用于:
- 主线程等待多个子线程执行结束后
- 主线程再执行
因此,具体使用过程中:
- 主线程:定义
CountDownLatch需要等待的子线程个数 - 子线程:调整
CountDownLatch的剩余线程数 - 主线程:
countDownLatch.await()阻塞等待子线程执行结束
使用 CyclicBarrier,多个子线程之间相互等待,具体操作:
- 主线程:定义 CyclicBarrier 需要等待的子线程个数
- 子线程:调用
CyclicBarrier.await()等待其他线程
直译为循环栅栏,通过它可以让一组线程全部到达某个状态后再同时执行,也就是说假如有5个线程协作完成一个任务,那么只有当每个线程都完成了各自的任务(都到达终点),才能继续运行(开始领奖)。循环的意思是当所有等待线程都被释放(也就是所有线程完成各自的任务,整个程序开始继续执行)以后,CyclicBarrier 可以被重用。而上面的 CountDownLatch 只能用一次。
更多细节,参考:Java并发:concurrent 包
原文地址:https://ningg.top/java-basic-summary-01/