Docker 系列:核心原理和实现(2)
2018-06-25
1. 概要
特别说明:这篇是在公司内部组织的 Docker 技术专题中,讨论分享的文章,我进行了局部调整。原文作者是我带的一个 94 年的小青年(兰迪),非常有潜力。
容器技术,主要关注下面几点:
- 安全
- 隔离
- 资源控制
Docker 作为容器的一种典型实现,也围绕上述几个方面在进行。具体实现上,使用了 Unix 内核提供的一些技术,四个方面:
- 命名空间(Namespace):资源隔离、用户隔离
- 控制组(Control Group):资源配额
- 联合文件系统(Union Filesystem):镜像文件的差量分发
- 网络 (Network):多种方案的对比,需要考虑
网络效率、适用场景
下文将进行详细介绍。
2. 命名空间(Namespace)
Linux Namespace 是内核级别的资源隔离方法,不同 namespace 之间,各自拥有的资源,相互没有影响,调整任何一个 namespace,都不会影响其他 namespace.
目前 Linux 内核实现了七种不同的 namespaces:
| 命名空间 | 系统调用参数(标记位) | Linux 内核版本 |
|---|---|---|
| Mount namespaces | CLONE_NEWNS |
Linux 2.4.19 |
| UTS namespaces | CLONE_NEWUTS |
Linux 2.6.19 |
| IPC namespaces | CLONE_NEWIPC |
Linux 2.6.19 |
| PID namespaces | CLONE_NEWPID |
Linux 2.6.24 |
| Network namespaces | CLONE_NEWNET |
Linux 2.6.29 |
| User namespaces | CLONE_NEWUSER |
Linux 3.8 |
| Cgroup | CLONE_NEWCGROUP |
Linux 4.6 |
补充说明:
- 其中 cgroup namespace 为新提出的,暂时没有在 Docker 中使用
- 每个命名空间,是
单个资源的命名空间,隔离对应资源 - 命名空间的
唯一标识,整型数字
在 Linux 系统,执行下述命令,查看当前进程所属的命名空间:
# 查看当前进程所属的命名空间:
# $$ 在 shell 场景下,会自动识别为当前进程的 pid
ls -l /proc/$$/ns
加入 or 退出一个命名空间,可以直接使用 Linux 提供的系统调用。
Linux 提供了三个 API 用来创建进程,并使其加入或脱离某个 Namespace:
#clone() :创建进程并把它放入一个 namespace,当前进程保持不变
#-flags:传入 namespace 对应参数
int clone(int (*child_func)(void *), void *child_stack
, int flags, void *arg);
#setns(): 将当前进程加入某 namespace 中
#-fd:指向/proc/[pid]/ns/目录里相应namespace对应的文件,表示要加入哪个namespace
#-nstype:指定namespace的类型
int setns(int fd, int nstype);
#unshare():使当前进程退出当前的 namespace,加入新指定的 namespace 中
#-flags:指定一个或者多个上面的CLONE_NEW*
int unshare(int flags);
2.1. Mount namespaces
作用:用来隔离文件系统的挂载点,不同的 Mount namespace 拥有独立的挂载点信息,不相互影响,有利于构建容器或者用户自己的文件目录。
当前进程所在mount namespace里的所有挂载信息,可以在 /proc/[pid]/mounts、/proc/[pid]/mountinfo和/proc/[pid]/mountstats里面找到。
ls -l /proc/$$/ns
补充说明:
- Mount namespace,是第一个加入 Linux 内核的命名空间,因此,叫做
CLONE_NEWNS参数,而没有叫做CLONE_NEWMOUNT - 新的mount namespace是在调用系统函数
clone()的时候指定CLONE_NEWS,或者调用unshare()的时候被创建; - 当一个新的mount namespace被创建的时候,它会从调用方的mount namespace中复制mount point列表;
- 可以在每个namespace中通过
mount()/unmount()独立的添加和删除mount points; - 默认情况下,mount point的变更仅对进程所在的namespace中的进程可见;
基于 mount namespace 的隔离性,为了实现一定程度的共享,在 Linux 2.6.15 中,引入 shared subtree 技术:
- 允许在
mount namespace之间自动,受控地传播mount和unmount事件; - 用途举例:将光盘安装在一个mount namespace中,可以在所有其他namespace中触发该磁盘的安装
- 本质使用了 2 个技术:
- Peer groups(
对等组):对等组是一组mount points,它们将挂载和卸载事件相互传播; - propagation type(
传播类型):在此mount point下创建和删除的mount point是否传播到其他mount point;针对每个挂载点,单独指定propagation type;
- Peer groups(
更多细节,参考 mount namespace和shared subtrees
2.2. UTS namespaces
作用:用来隔离系统的「主机名 hostname」以及「NIS 域名」。
补充: NIS 域名,集中控制「用户登录账号」相关信息的服务,细节参考 Linux Namespace : UTS
具体:
- 这两种资源可以通过 sethostname 和 setdomainname 函数来设置;
- 通过 uname, gethostname 和 getdomainname 函数来获取;
UTS namespace 不存在嵌套关系,即不存在一个namespace是另一个namespace的父namespace。
内核中的实现:
- 在老版本的 Linux 中,UTS 的相关信息保存在一个
全局变量中,所有进程都共享这个全局变量。 - 在新版本中,在每个
进程对应的结构体task_struct中,增加了一个 nsproxy 字段,保存相关信息。不同 UTS namespace 中的进程,指针指向的结构体不同,从而达到了隔离 UTS 信息的目的。
2.3. IPC namespaces
「进程间通信 Inter-Process Communication)」就是在不同进程间传播和交换信息,主要目的是为了数据传输、共享数据、通知、资源共享和进程控制,有以下几种方式:
- 管道:pipe 匿名管道、s_pipe 流管道和FIFO 命名管道
- 信号 Signal
- 消息队列
- 共享内存
- 信号量
- 套接字 Socket
IPC namespaces 是用来隔离 System V IPC objects 和 POSIX message queues。其中System V IPC objects包含Message queues、Semaphore sets和Shared memory segments。
对于其他的IPC方式:
- 信号和 pid 密切相关,信号的隔离由 pid 决定。
- 匿名管道只能在父子进程间通讯,不需要隔离,命名管道的隔离由文件系统决定。
- socket和协议栈相关,隔离由 network namespace 决定。
IPC namespaces同样不存在嵌套关系。
2.4. PID namespaces
PID namespaces用来隔离进程的ID空间,使得不同 PID namespace 里的进程ID可以重复且相互之间不影响,最初是为了解决容器的热迁移的问题。
PID namespace可以嵌套,也就是说有父子关系,在当前namespace里面创建的所有新的namespace都是当前namespace的子namespace。父namespace里面可以看到所有子孙后代namespace里的进程信息,而子namespace里看不到祖先或者兄弟namespace里的进程信息。目前PID namespace最多可以嵌套32层,由内核中的宏MAX_PID_NS_LEVEL来定义。
Linux下的每个进程都有一个对应的/proc/PID目录,该目录包含了大量的有关当前进程的信息。 对一个PID namespace而言,/proc目录只包含当前namespace和它所有子孙后代namespace里的进程的信息。
在Linux系统中,进程ID从1开始往后不断增加,并且不能重复(当然进程退出后,ID会被回收再利用),进程ID为1的进程是内核启动的第一个应用层进程,一般是init进程(现在采用systemd的系统第一个进程是systemd),具有特殊意义,当系统中一个进程的父进程退出时,内核会指定init进程成为这个进程的新父进程,而当init进程退出时,系统也将退出。
除了在「init进程」里指定了handler的信号外,内核会帮「init进程」屏蔽掉其他任何信号,这样可以防止其他进程不小心 kill 掉「init进程」导致系统挂掉。不过有了PID namespace后,可以通过在父namespace中发送SIGKILL或者SIGSTOP信号来终止子namespace中的ID为1的进程。
由于ID为1的进程的特殊性,所以每个PID namespace的第一个进程的ID都是1。当这个进程运行停止后,内核将会给这个namespace里的所有其他进程发送SIGKILL信号,致使其他所有进程都停止,于是namespace被销毁掉。
# 可以查看当前 PID namespace 的 pid
readlink /proc/self/ns/pid
PID namespace嵌套:
- 调用unshare或者setns函数后,当前进程的namespace不会发生变化,不会加入到新的namespace,而它的子进程会加入到新的namespace。也就是说进程属于哪个namespace是在进程创建的时候决定的,并且以后再也无法更改。
- 在一个PID namespace里的进程,它的父进程可能不在当前namespace中,而是在外面的namespace里面(这里外面的namespace指当前namespace的祖先namespace),这类进程的ppid都是0。比如新namespace里面的第一个进程,他的父进程就在外面的namespace里。通过setns的方式加入到新namespace中的进程的父进程也在外面的namespace中。
- 可以在祖先namespace中看到子namespace的所有进程信息,且可以发信号给子namespace的进程,但进程在不同namespace中的PID是不一样的。
2.5. Network namespace
network namespace 用来隔离网络设备, IP地址, 端口等。每个 namespace 将会有自己独立的网络栈,路由表,防火墙规则,socket等。
3. Control Groups
通过「Linux Namespace」可以隔离容器和宿主机间的文件系统、pid等系统资源,但是无法进行物理资源如 CPU和内存 的隔离。如果多个容器间无法隔离 CPU 资源,一个容器频繁占用CPU,会影响其他容器的执行效率和性能。
CGroups 是 Linux 内核提供的一种可以限制、记录、隔离进程组(process groups)所使用的物理资源(如CPU、网络带宽等)的机制。
CGroups 的相关概念:
- 任务 task:任务对应系统的一个进程。
- 控制组 control group:进行资源控制的单位。
- 层级 hierarchy:控制组具有层级关系,子控制组继承父控制组的配置。
- 子系统 subsystem:一个子系统对应一个资源控制器。子系统必须附加到一个层级上才会起作用,整个层级都受到这个子系统的控制。
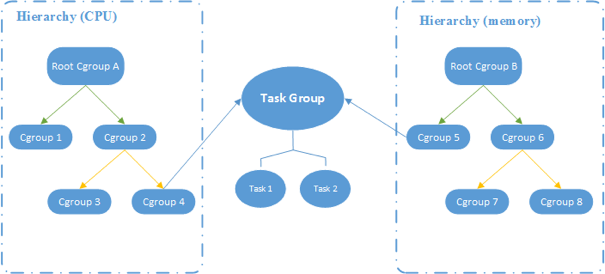
在 CGroups中:
- 第一次挂载一颗和指定 subsystem 关联的cgroup树时,会创建一颗新的 cgroup 树,当再一次用同样的参数挂载时,会重用现有的cgroup树,也即两个挂载点看到的内容是一样的。
- 挂载一颗 cgroup 树时,可以指定多个subsystem与之关联,但一个subsystem只能关联到一颗 cgroup 树,所以系统内最多有 12 颗 cgroup 树。
- control group 是受到资源控制的单位,而 subsystem 是实际控制资源分配的单位。
- 如果 cgroup 树不和任何 subsystem 相连,那么只是将进程分组。
Linux 使用文件系统来实现 CGroup。
目前 Linux 支持 12 种 subsystem:
- cpu 用来限制cgroup的CPU使用率。
- cpuacct 统计cgroup的CPU的使用率。
- cpuset 绑定cgroup到指定CPUs和NUMA节点。
- memory 统计和限制cgroup的内存的使用率,包括process memory, kernel memory, 和swap。
- devices 限制cgroup创建(mknod)和访问设备的权限。
- freezer suspend和restore一个cgroup中的所有进程。
- net_cls 将一个cgroup中进程创建的所有网络包加上一个classid标记,用于tc和iptables。 只对发出去的网络包生效,对收到的网络包不起作用。
- blkio 限制cgroup访问块设备的IO速度。
- perf_event 对cgroup进行性能监控
- net_prio针对每个网络接口设置cgroup的访问优先级。
- hugetlb限制cgroup的huge pages的使用量。
- pids 限制一个cgroup及其子孙cgroup中的总进程数。
4. Union File System
UnionFS 就是将不同物理位置下的文件合并到一个目录下。
Docker 提供了多种可选的驱动,如:AUFS、devicemapper、overlay2、zfs 和 vfs 等,其中 AUFS 是 Docker 的默认驱动,在新版本的 Docker 中 overlay2 替代了 AUFS。
各个 Linux 发行版本对存储驱动的支持如下:
| Linux distribution | Recommended storage drivers |
|---|---|
| Docker CE on Ubuntu | aufs, devicemapper, overlay2 (Ubuntu 14.04.4 or later, 16.04 or later), overlay, zfs, vfs |
| Docker CE on Debian | aufs, devicemapper, overlay2 (Debian Stretch), overlay, vfs |
| Docker CE on CentOS | devicemapper, vfs |
| Docker CE on Fedora | devicemapper, overlay2 (Fedora 26 or later, experimental), overlay (experimental), vfs |
可以通过命令查看当前使用的驱动:
docker info | grep Storage
Linux mount 命令支持将一个或者多个文件目录挂载到制定加载点,通过本地路径的方式去访问,但是所有的修改会保存在本地,不会影响被挂载的文件目录。
UnionFS 实质就是将多个物理文件进行 mount,应用主要体现在「镜像」和「容器」上。
可以通过在 docker daemon 中添加命令来指定使用的存储驱动:
--storage-driver=<name>
或者在 /etc/default/docker 文件中通过 DOCKER_OPTS 指定。
4.1. AUFS
AUFS (Advanced Multi-layered unification filesytem)是 Docker 默认的 UnionFS 存储驱动,实质就是将多个文件目录合并成一个,构建过程如下:
- 默认情况下,最上层的目录为读写层,只能有一个;下面可以有一个或者多个只读层
- 读文件:从最上面一个开始往下逐层去找,打开第一个找到的文件,读取其中的内容
- 写文件:
- 如果在最上层找到了该文件,直接打开
- 否则,从上往下开始查找,找到文件后,把文件复制到最上层,然后再打开这个 copy(所以,如果要读写的文件很大,这个过程耗时会很久)
- 删除文件:在最上层创建一个 whiteout 隐藏文件,.wh.
,就是在原来的文件名字前面加上 .wh.
AUFS 的内容都保存在 :
/var/lib/docker/aufs
➜ tree -L 1 /var/lib/docker/aufs
/var/lib/docker/aufs
├── diff
├── layers
└── mnt
其中:
- diff:镜像每一层的内容,每个文件夹代表一个层(由原始镜像+修改内容组成)
- layers:镜像层根据被 union 的顺序形成一个 stack,每一层的ID按顺序存储进一个文件里
- mnt:镜像或者容器的最终挂载点 mountpoints,我们最后看到的样子
通过命令,查看镜像构建的层信息:
docker inspect ubuntu:16.04
...
"RootFS": {
"Type": "layers",
"Layers": [
"sha256:014cf8bfcb2d50b7b519c4714ac716cda5b660eae34189593ad880dc72ba4526",
"sha256:832a3ae4ac84380da78e33fa0f5a6e1336686f7655efbddbcd50dbf88d05d267",
"sha256:e89b70d287954a6af78ef1ddb9478926ec0796ba9ac05519c8cc9343b779ace3"
]
},
...
如果被 union 的文件目录发生改变,mount 的目录是否会发生改变?通过指定 udba 参数来控制:
udba=none: AUFS不会同步原始目录的变动,执行速度更快,但是会有数据出错的问题。udba=reval: AUFS会检测原始目录的修改,并同步到 mount 目录。udba=notify: AUFS会为所有被 union 的目录注册 inotify 参数,通过该参数来监控文件目录是否被修改
AUFS的问题:
因为 aufs 的代码过于冗余,Linux 没有将它加入内核中,只有 ubuntu 的发行版本默认支持 aufs,在 centOs 中就没有提供支持,因此不能保证移植行。
4.2. devicemapper
由于 AUFS 没有被加入内核,很多其他发行版本的 Linux 不支持 AUFS,红帽公司和 Docker 团队联手开发了 devicemapper。
devicemapper 基于 Linux 的 Device Mapper 框架,由于Device Mapper 技术是在块(block)层面而非文件层面,所以Docker Engine的devicemapper存储驱动使用的是块设备来存储数据而非文件系统。
devicemapper 有两种配置模式:loop-lvm 和 direct-lvm,其中 loop-lvm (默认模式)是官方为了让用户马上可以使用的精简模式,最大使用空间只有 107GB,实际生产环境不建议使用。
4.3. OverlayFS
OverlayFS是和AUFS相似的联合文件系统(union filesystem),它有如下特点:
- 设计简洁
- 3.18 版本开始已经并入 Linux 内核
- 可能更快
docker 的 overlay 存储驱动利OverlayFS的一些特征来构建以及管理镜像和容器的磁盘结构。
docker1.12后推出的 overlay2 在inode的利用方面比ovelay更有效,overlay2要求内核版本大于等于4.0。
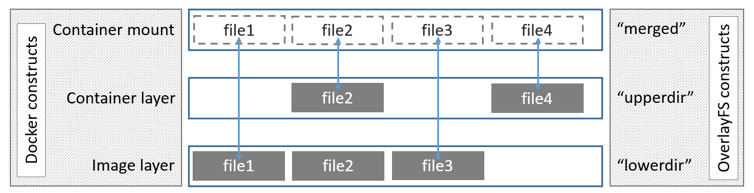
Overlay 在主机上用到2个目录,这2个目录被看成是 overlay 的层。「 upperdir」为容器层、「lowerdir」为镜像层使用联合挂载技术将它们挂载在「统一目录merged」下。
当容器层和镜像层拥有相同的文件时,容器层的文件可见,隐藏了镜像层相同的文件。
Overlay 只使用2层,意味着多层镜像不会被实现为多个OverlayFS层。每个镜像被实现为自己的目录, 这个目录在路径 /var/lib/docker/overlay 下。文件地址被用来索引和低层共享的数据,节省了空间。当创建一个容器时,overlay 驱动连接代表镜像层顶层的目录(只读)和一个代表容器层的新目录(读写)。
5. 网络
网络分为 2 个部分讨论:
- CNM 网络模型
- 网络模式
5.1. CNM网络模型
Docker 通过独立拆分出来的 libnetwork实现的,为应用给出一个能够提供一致的编程接口和网络层抽象的容器网络模型 :Container Network Model, CNM 网络模型,如图所示:
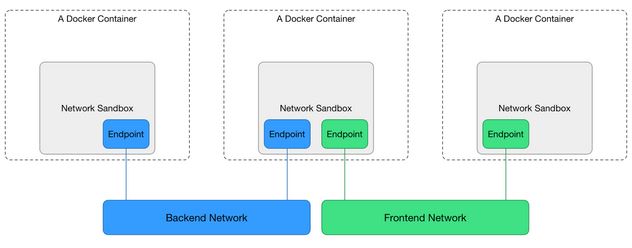
CNM模型有三个组件:
- Sandbox(沙盒):每个沙盒包含一个容器网络栈(network stack)的配置,配置包括:容器的网口、路由表和DNS设置等。
- Endpoint(端点):通过Endpoint,沙盒可以被加入到一个Network里。
- Network(网络):一组能相互直接通信的Endpoints。
Docker 通过「linux namespace」实现了 Sandbox,来隔绝网络资源,通过「虚拟的以太网网卡接口」实现了 Endpoint,通过「Docker0 Bridge」实现了 Network。
$ ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc mq master bond1 state UP mode DEFAULT group default qlen 1000
link/ether 6c:92:bf:27:4c:cd brd ff:ff:ff:ff:ff:ff
3: eth1: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc mq master bond1 state UP mode DEFAULT group default qlen 1000
link/ether 6c:92:bf:27:4c:cd brd ff:ff:ff:ff:ff:ff
4: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN mode DEFAULT group default
link/ipip 0.0.0.0 brd 0.0.0.0
5: bond0: <BROADCAST,MULTICAST,MASTER> mtu 1500 qdisc noop state DOWN mode DEFAULT group default
link/ether a6:23:28:87:18:46 brd ff:ff:ff:ff:ff:ff
6: bond1: <BROADCAST,MULTICAST,MASTER,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 6c:92:bf:27:4c:cd brd ff:ff:ff:ff:ff:ff
7: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default
link/ether 02:42:b9:d9:4f:7b brd ff:ff:ff:ff:ff:ff
8: cbr0: <BROADCAST,MULTICAST,PROMISC,UP,LOWER_UP> mtu 1500 qdisc htb state UP mode DEFAULT group default
link/ether 0a:58:0a:1e:bc:81 brd ff:ff:ff:ff:ff:ff
526: veth73fc4d03@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master cbr0 state UP mode DEFAULT group default
link/ether 26:27:b5:33:89:0d brd ff:ff:ff:ff:ff:ff link-netnsid 2
579: veth5eaf0c3d@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master cbr0 state UP mode DEFAULT group default
link/ether 36:de:bf:72:f7:9a brd ff:ff:ff:ff:ff:ff link-netnsid 19
600: veth90b74b20@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master cbr0 state UP mode DEFAULT group default
link/ether ce:a8:68:d3:e1:f0 brd ff:ff:ff:ff:ff:ff link-netnsid 36
613: veth994285fb@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master cbr0 state UP mode DEFAULT group default
link/ether 52:c5:22:7f:c1:0d brd ff:ff:ff:ff:ff:ff link-netnsid 23
614: veth1526c362@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master cbr0 state UP mode DEFAULT group default
link/ether d6:3b:eb:6e:b1:ca brd ff:ff:ff:ff:ff:ff link-netnsid 26
383: veth74050a8f@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master cbr0 state UP mode DEFAULT group default
link/ether fa:88:96:18:7e:fc brd ff:ff:ff:ff:ff:ff link-netnsid 6
662: veth46a74c03@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master cbr0 state UP mode DEFAULT group default
link/ether 06:48:fd:f0:30:53 brd ff:ff:ff:ff:ff:ff link-netnsid 31
5.2. 网络模式
Docker 通过命名空间实现了与宿主机器的网络隔离,每一个容器都有单独的网络命名空间。
Docker 提供了五种网络模式:Bridge、Host、Container、None和 User-Defined ,其中 Bridge 是 Docker 默认的网络模式。
5.2.1. Bridge
Bridge 模式下,Docker 守护进程创建了一个虚拟的以太网桥「Docker0」,所有容器通过「Docker0」与宿主机相连,形成一个物理网络。=》SandBox
每个容器在创建时会生成一对「虚拟的以太网网卡接口」,其中一个保存在容器上,叫「eth0」,另一个「veth」接口放在网桥中,两个接口一一对应。=》Endpoint
Docker 守护进程为每个容器都分配了 IP地址和子网掩码,每创建一个容器会通过「iptables」配置一条新的路由规则进行数据转发,实现了容器与宿主机网络的互联。=》Network
通过命令 brctl show 查看当前网桥的接口:
$ brctl show
bridge name bridge id STP enabled interfaces
cbr0 8000.0a580a1ebc81 no veth01470cc9
veth12363ea7
veth12b7d7c9
veth1504ce20
veth1526c362
veth3fdc00b9
veth40393ffc
veth41b81688
veth44df3bd6
veth46a74c03
veth49bb07de
veth5eaf0c3d
veth6848c2ba
veth6b688a39
veth73fc4d03
veth74050a8f
veth90b74b20
veth994285fb
veth9fb1d2c2
vethc3b28378
vethc43e27cb
vethd057cae0
vethe3368ab2
vethe66b69a8
docker0 8000.0242b9d94f7b no
5.2.2. Host
Host 模式下禁用了容器的网络隔离,容器共享了宿主机的网络命名空间,和宿主机拥有同样的 IP 地址,公用宿主机的端口。该模式下不需要做网络地址转发,减少了开销,速度较快,但是直接暴露在公共网络中,具有安全隐患,且不能再使用宿主局已经占用的端口。
通过命令指定
docker run --network=host
5.2.3. Container
Container 模式下,创建的容器直接使用一个已存在容器的网络配置,ip 信息和网络端口等所有网络相关的信息都是共享的。但是两个容器的存储和计算资源还是隔离的。
kubernetes 应用了该种模式。
通过命令指定:
docker run --net=container:[name]
5.2.4. None
None 模式下,容器关闭了网络功能,每个容器有自己的 Network namespace 但是没有做任何配置。适用于以下两种情况:
容器不需要网络
希望自定义容器的网络功能
通过命令指定:
docker run --net=none
5.2.5. user-defined
user-defined 模式下,容器可以应用 Docker 提供的五种网络驱动:bridge、host、overlay、macvlan、none、third-party network plugins。
6. 参考资料
原文地址:https://ningg.top/docker-series-02-core-tech-and-implementation-supplement/