Flume 1.5.0.1 User Guide:introduction
2014-10-17
Introduction
Overview
Apache Flume is a distributed, reliable, and available system for efficiently collecting, aggregating and moving large amounts of log data from many different sources to a centralized data store.
The use of Apache Flume is not only restricted to log data aggregation. Since data sources are customizable, Flume can be used to transport massive quantities of event data including but not limited to network traffic data, social-media-generated data, email messages and pretty much any data source possible.(数据源:网络流量数据、社交媒体产生的数据、email数据、其他数据,Flume都能收集)
Apache Flume is a top level project at the Apache Software Foundation.
There are currently two release code lines available, versions 0.9.x and 1.x.
Documentation for the 0.9.x track is available at the Flume 0.9.x User Guide.
This documentation applies to the 1.4.x track.
New and existing users are encouraged to use the 1.x releases so as to leverage the performance improvements and configuration flexibilities available in the latest architecture.(推荐使用Flume 1.x版本:性能有改善、配置方便,使用了最新架构)
System Requirements
- Java Runtime Environment - Java 1.6 or later (Java 1.7 Recommended) (运行环境:JRE 1.6+,推荐JRE1.7)
- Memory - Sufficient memory for configurations used by sources, channels or sinks
- Disk Space - Sufficient disk space for configurations used by channels or sinks
- Directory Permissions - Read/Write permissions for directories used by agent (agent需要R/W权限)
Architecture
Data flow model
A Flume event is defined as a unit of data flow having a byte payload and an optional set of string attributes. A Flume agent is a (JVM) process that hosts the components through which events flow from an external source to the next destination (hop).(Flume Event是a unit of data flow having a byte payload 和几个属性集合;Flume Agent是JVM进程,将events flow从一端送到另一端)
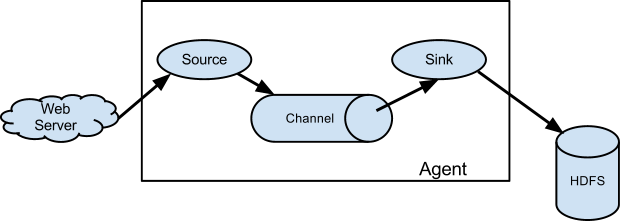
A Flume source consumes events delivered to it by an external source like a web server. The external source sends events to Flume in a format that is recognized by the target Flume source. For example, an Avro Flume source can be used to receive Avro events from Avro clients or other Flume agents in the flow that send events from an Avro sink. A similar flow can be defined using a Thrift Flume Source to receive events from a Thrift Sink or a Flume Thrift Rpc Client or Thrift clients written in any language generated from the Flume thrift protocol.When a Flume source receives an event, it stores it into one or more channels. The channel is a passive store that keeps the event until it’s consumed by a Flume sink. The file channel is one example – it is backed by the local filesystem. The sink removes the event from the channel and puts it into an external repository like HDFS (via Flume HDFS sink) or forwards it to the Flume source of the next Flume agent (next hop) in the flow. The source and sink within the given agent run asynchronously with the events staged in the channel.(Source,接收外部data source的数据;Channel,被动接收Source的数据;Sink主动从Channel读取数据,并将其传递出去;利用Channel机制,Source、Sink实现异步处理)
Complex flows
Flume allows a user to build multi-hop flows where events travel through multiple agents before reaching the final destination. It also allows fan-in and fan-out flows, contextual routing and backup routes (fail-over) for failed hops.(Flume内flows支持fan-in、fan-out——多入多出,contextual touting和backup routes(fail-over))
notes(ningg):contextual routing 和 backup routes的含义?
Reliability
The events are staged in a channel on each agent. The events are then delivered to the next agent or terminal repository (like HDFS) in the flow. The events are removed from a channel only after they are stored in the channel of next agent or in the terminal repository. This is a how the single-hop message delivery semantics in Flume provide end-to-end reliability of the flow.(single-hop message delivery semantics:Channel中的event仅在被成功处理之后,才从Channel中删掉。)
Flume uses a transactional approach to guarantee the reliable delivery of the events. The sources and sinks encapsulate in a transaction the storage/retrieval, respectively, of the events placed in or provided by a transaction provided by the channel. This ensures that the set of events are reliably passed from point to point in the flow. In the case of a multi-hop flow, the sink from the previous hop and the source from the next hop both have their transactions running to ensure that the data is safely stored in the channel of the next hop.(multi-hop:)
notes(ningg):Flume如何保证事物操作?没看懂
Recoverability
The events are staged in the channel, which manages recovery from failure. Flume supports a durable file channel which is backed by the local file system. There’s also a memory channel which simply stores the events in an in-memory queue, which is faster but any events still left in the memory channel when an agent process dies can’t be recovered.(Channel需保证崩溃后,能恢复events,具体:本地FS上保存durable file channel,另,占用一个in-memory queue,Channel进程崩溃后,能加快恢复速度;但,如果agent进程崩溃,将导致内存泄漏:无法回收这一内存)
Setup
Setting up an agent
Flume agent configuration is stored in a local configuration file. This is a text file that follows the Java properties file format. Configurations for one or more agents can be specified in the same configuration file. The configuration file includes properties of each source, sink and channel in an agent and how they are wired together to form data flows.(Agent利用config file设置:source、channel、sink的属性,以及不同Agent之间前后联系)
Configuring individual components
Each component (source, sink or channel) in the flow has a name, type, and set of properties that are specific to the type and instantiation. For example, an Avro source needs a hostname (or IP address) and a port number to receive data from. A memory channel can have max queue size (“capacity”), and an HDFS sink needs to know the file system URI, path to create files, frequency of file rotation (“hdfs.rollInterval”) etc. All such attributes of a component needs to be set in the properties file of the hosting Flume agent.(设置Component的属性)
Wiring the pieces together
The agent needs to know what individual components to load and how they are connected in order to constitute the flow. This is done by listing the names of each of the sources, sinks and channels in the agent, and then specifying the connecting channel for each sink and source. For example, an agent flows events from an Avro source called avroWeb to HDFS sink hdfs-cluster1 via a file channel called file-channel. The configuration file will contain names of these components and file-channel as a shared channel for both avroWeb source and hdfs-cluster1 sink.(设置不同agent构成的topologies)
Starting an agent
An agent is started using a shell script called flume-ng which is located in the bin directory of the Flume distribution. You need to specify the agent name, the config directory, and the config file on the command line:(启动agent,需要指定参数:agent name、config dir、config file。)
$ bin/flume-ng agent -n $agent_name -c conf -f conf/flume-conf.properties.template
Now the agent will start running source and sinks configured in the given properties file.
A simple example
Here, we give an example configuration file, describing a single-node Flume deployment. This configuration lets a user generate events and subsequently logs them to the console.(场景:single-node模式,user产生events并且将其输出到控制台)
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
This configuration defines a single agent named a1. a1 has a source that listens for data on port 44444, a channel that buffers event data in memory, and a sink that logs event data to the console. The configuration file names the various components, then describes their types and configuration parameters. A given configuration file might define several named agents; when a given Flume process is launched a flag is passed telling it which named agent to manifest.(一个配置文件中,可设定多个agents,Flume进程启动时,会指定agent运行)
notes(ningg):配置文件中,具体参数配置:

Given this configuration file, we can start Flume as follows:
$ bin/flume-ng agent --conf conf --conf-file example.conf --name a1 -Dflume.root.logger=INFO,console
Note that in a full deployment we would typically include one more option: --conf=<conf-dir>. The <conf-dir> directory would include a shell script flume-env.sh and potentially a log4j properties file. In this example, we pass a Java option to force Flume to log to the console and we go without a custom environment script.(实际开发场景下,通过--conf=<conf-dir>传入<conf-dir>,通常这一目录下应包含flume-env.sh文件和log4j的配置文件)
From a separate terminal, we can then telnet port 44444 and send Flume an event:
$ telnet localhost 44444
Trying 127.0.0.1...
Connected to localhost.localdomain (127.0.0.1).
Escape character is '^]'.
Hello world! <ENTER>
OK
The original Flume terminal will output the event in a log message.
12/06/19 15:32:19 INFO source.NetcatSource: Source starting
12/06/19 15:32:19 INFO source.NetcatSource: Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:44444]
12/06/19 15:32:34 INFO sink.LoggerSink: Event: { headers:{} body: 48 65 6C 6C 6F 20 77 6F 72 6C 64 21 0D Hello world!. }
Congratulations - you’ve successfully configured and deployed a Flume agent! Subsequent sections cover agent configuration in much more detail.
notes(ningg):telnet通过命令行方式,能够发送字符?那么能与服务器交互吗?telnet命令方式下,典型应用场景有哪些?
Installing third-party plugins
Flume has a fully plugin-based architecture. While Flume ships with many out-of-the-box sources, channels, sinks, serializers, and the like, many implementations exist which ship separately from Flume.
While it has always been possible to include custom Flume components by adding their jars to the FLUME_CLASSPATH variable in the flume-env.sh file, Flume now supports a special directory called plugins.d which automatically picks up plugins that are packaged in a specific format. This allows for easier management of plugin packaging issues as well as simpler debugging and troubleshooting of several classes of issues, especially library dependency conflicts.(在flume-env.sh中向FLUME_CLASSPATH中添加plugin的位置;另一种方式,向plugins.d目录下添加plugin,即可自动安装。)
The plugins.d directory
The plugins.d directory is located at $FLUME_HOME/plugins.d. At startup time, the flume-ng start script looks in the plugins.d directory for plugins that conform to the below format and includes them in proper paths when starting up java.(系统其中前,自动预处理plugins.d下的plugin)
Directory layout for plugins
Each plugin (subdirectory) within plugins.d can have up to three sub-directories:
- lib - the plugin’s jar(s)
- libext - the plugin’s dependency jar(s)
- native - any required native libraries, such as .so files
Example of two plugins within the plugins.d directory:(plugins.d目录下,plugin的目录结构如下)
plugins.d/
plugins.d/custom-source-1/
plugins.d/custom-source-1/lib/my-source.jar
plugins.d/custom-source-1/libext/spring-core-2.5.6.jar
plugins.d/custom-source-2/
plugins.d/custom-source-2/lib/custom.jar
plugins.d/custom-source-2/native/gettext.so
Data ingestion
Flume supports a number of mechanisms to ingest data from external sources.(从外部 sources 获取数据,Flume有多种方式)
RPC
An Avro client included in the Flume distribution can send a given file to Flume Avro source using avro RPC mechanism:
$ bin/flume-ng avro-client -H localhost -p 41414 -F /usr/logs/log.10
The above command will send the contents of /usr/logs/log.10 to to the Flume source listening on that ports.
notes(ningg):什么含义?以Avro方式,向localhost:41414发送文件?仅仅是Data Source?有一个单独的Flume Source在localhost:41414监听?
Executing commands
There’s an exec source that executes a given command and consumes the output. A single ‘line’ of output ie. text followed by carriage return (\r) or line feed (\n) or both together.(exec source,执行command并将output按行发送至Channel)
Note: Flume does not support tail as a source. One can wrap the tail command in an exec source to stream the file.(无法直接使用tail,需要包装在exec source中。)
Network streams
Flume supports the following mechanisms to read data from popular log stream types, such as:(下述方式支持从log system中读取stream)
- Avro
- Thrift
- Syslog
- Netcat
notes(ningg):上面都是什么呐?
Setting multi-agent flow

In order to flow the data across multiple agents or hops, the sink of the previous agent and source of the current hop need to be avro type with the sink pointing to the hostname (or IP address) and port of the source.(multiple agents时,previous agent中sink、current agent中source都应为avro类型,对应到相同的IP:port)
Consolidation
A very common scenario in log collection is a large number of log producing clients sending data to a few consumer agents that are attached to the storage subsystem. For example, logs collected from hundreds of web servers sent to a dozen of agents that write to HDFS cluster.(一个常见场景:大量client收集数据,写入一个集中系统)

This can be achieved in Flume by configuring a number of first tier agents with an avro sink, all pointing to an avro source of single agent (Again you could use the thrift sources/sinks/clients in such a scenario). This source on the second tier agent consolidates the received events into a single channel which is consumed by a sink to its final destination.(解决办法:为每个client分配一个agent,再第二层,使用一个agent进行合并,然后写入最后的集中存储系统;不适用single-agent中的multi-sources,因为multi-sources,要求sources必须与channel在同一物理机器上,即,一个agent必须在一个物理机器上)
Multiplexing the flow
Flume supports multiplexing the event flow to one or more destinations. This is achieved by defining a flow multiplexer that can replicate or selectively route an event to one or more channels.(对agent扩展,定义多个channel,实现fan-out)
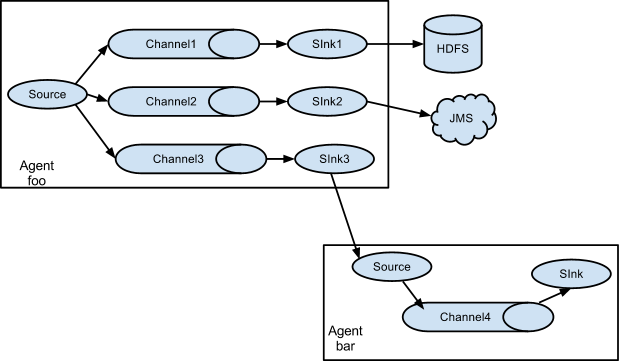
The above example shows a source from agent “foo” fanning out the flow to three different channels. This fan out can be replicating or multiplexing. In case of replicating flow, each event is sent to all three channels. For the multiplexing case, an event is delivered to a subset of available channels when an event’s attribute matches a preconfigured value. For example, if an event attribute called “txnType” is set to “customer”, then it should go to channel1 and channel3, if it’s “vendor” then it should go to channel2, otherwise channel3. The mapping can be set in the agent’s configuration file.(两种fan-out方式,replicating\multiplexing,即,复制和多路复用;replicating,输入复制到每个channel中一份;multiplexing,输入仅复制到匹配的channel中,相当于channel前加了个filter)
Configuration
As mentioned in the earlier section, Flume agent configuration is read from a file that resembles a Java property file format with hierarchical property settings.(hierarchical property settings?)
Defining the flow
To define the flow within a single agent, you need to link the sources and sinks via a channel. (定义single-agent内的flow时,几点:)
- 列出agent对应的sources、sinks、channels;
- 指定与source对应的channels,指定与sink对应的channel;
- 一个source可对应多个channel,一个sink只能对应一个channel;
The format is as follows:
# list the sources, sinks and channels for the agent
<Agent>.sources = <Source>
<Agent>.sinks = <Sink>
<Agent>.channels = <Channel1> <Channel2>
# set channel for source
<Agent>.sources.<Source>.channels = <Channel1> <Channel2> ...
# set channel for sink
<Agent>.sinks.<Sink>.channel = <Channel1>
notes(ningg):source绑定channels、sink绑定channel。疑问:单个agent中source只能有一个吗?如果single-agent中有多个source,那么是否也可以实现fan-in?
For example, an agent named agent_foo is reading data from an external avro client and sending it to HDFS via a memory channel. The config file weblog.config could look like:
# list the sources, sinks and channels for the agent
agent_foo.sources = avro-appserver-src-1
agent_foo.sinks = hdfs-sink-1
agent_foo.channels = mem-channel-1
# set channel for source
agent_foo.sources.avro-appserver-src-1.channels = mem-channel-1
# set channel for sink
agent_foo.sinks.hdfs-sink-1.channel = mem-channel-1
This will make the events flow from avro-AppSrv-source to hdfs-Cluster1-sink through the memory channel mem-channel-1. When the agent is started with the weblog.config as its config file, it will instantiate that flow.
Configuring individual components
After defining the flow, you need to set properties of each source, sink and channel. This is done in the same hierarchical namespace fashion where you set the component type and other values for the properties specific to each component:
# properties for sources
<Agent>.sources.<Source>.<someProperty> = <someValue>
# properties for channels
<Agent>.channels.<Channel>.<someProperty> = <someValue>
# properties for sinks
<Agent>.sources.<Sink>.<someProperty> = <someValue>
The property type needs to be set for each component for Flume to understand what kind of object it needs to be. Each source, sink and channel type has its own set of properties required for it to function as intended. All those need to be set as needed. In the previous example, we have a flow from avro-AppSrv-source to hdfs-Cluster1-sink through the memory channel mem-channel-1. Here’s an example that shows configuration of each of those components:(不同的组件有不同的property,但都有type属性)
agent_foo.sources = avro-AppSrv-source
agent_foo.sinks = hdfs-Cluster1-sink
agent_foo.channels = mem-channel-1
# set channel for sources, sinks
# properties of avro-AppSrv-source
agent_foo.sources.avro-AppSrv-source.type = avro
agent_foo.sources.avro-AppSrv-source.bind = localhost
agent_foo.sources.avro-AppSrv-source.port = 10000
# properties of mem-channel-1
agent_foo.channels.mem-channel-1.type = memory
agent_foo.channels.mem-channel-1.capacity = 1000
agent_foo.channels.mem-channel-1.transactionCapacity = 100
# properties of hdfs-Cluster1-sink
agent_foo.sinks.hdfs-Cluster1-sink.type = hdfs
agent_foo.sinks.hdfs-Cluster1-sink.hdfs.path = hdfs://namenode/flume/webdata
#...
Adding multiple flows in an agent
A single Flume agent can contain several independent flows. You can list multiple sources, sinks and channels in a config. These components can be linked to form multiple flows:
# list the sources, sinks and channels for the agent
<Agent>.sources = <Source1> <Source2>
<Agent>.sinks = <Sink1> <Sink2>
<Agent>.channels = <Channel1> <Channel2>
notes(ningg):关于single-agent说几点:
- 可包含多个sources、sinks、channels;
- 定义多个sources时,
source1和source2间,空格 - sink与channel一一对应吗?
- 可包含多个相互独立的flow;
疑问:source、channel、sink之间对应关系?1:1?1:n?n:1?n:n?
Then you can link the sources and sinks to their corresponding channels (for sources) of channel (for sinks) to setup two different flows. For example, if you need to setup two flows in an agent, one going from an external avro client to external HDFS and another from output of a tail to avro sink, then here’s a config to do that:
# list the sources, sinks and channels in the agent
agent_foo.sources = avro-AppSrv-source1 exec-tail-source2
agent_foo.sinks = hdfs-Cluster1-sink1 avro-forward-sink2
agent_foo.channels = mem-channel-1 file-channel-2
# flow #1 configuration
agent_foo.sources.avro-AppSrv-source1.channels = mem-channel-1
agent_foo.sinks.hdfs-Cluster1-sink1.channel = mem-channel-1
# flow #2 configuration
agent_foo.sources.exec-tail-source2.channels = file-channel-2
agent_foo.sinks.avro-forward-sink2.channel = file-channel-2
Configuring a multi agent flow
To setup a multi-tier flow, you need to have an avro/thrift sink of first hop pointing to avro/thrift source of the next hop. This will result in the first Flume agent forwarding events to the next Flume agent. For example, if you are periodically sending files (1 file per event) using avro client to a local Flume agent, then this local agent can forward it to another agent that has the mounted for storage.(multi-agent之间通过avro、thrift方式进行连接,通过IP:port来交互)
Weblog agent config:
# list sources, sinks and channels in the agent
agent_foo.sources = avro-AppSrv-source
agent_foo.sinks = avro-forward-sink
agent_foo.channels = file-channel
# define the flow
agent_foo.sources.avro-AppSrv-source.channels = file-channel
agent_foo.sinks.avro-forward-sink.channel = file-channel
# avro sink properties
agent_foo.sinks.avro-forward-sink.type = avro
agent_foo.sinks.avro-forward-sink.hostname = 10.1.1.100
agent_foo.sinks.avro-forward-sink.port = 10000
# configure other pieces
#...
HDFS agent config:
# list sources, sinks and channels in the agent
agent_foo.sources = avro-collection-source
agent_foo.sinks = hdfs-sink
agent_foo.channels = mem-channel
# define the flow
agent_foo.sources.avro-collection-source.channels = mem-channel
agent_foo.sinks.hdfs-sink.channel = mem-channel
# avro sink properties
agent_foo.sources.avro-collection-source.type = avro
agent_foo.sources.avro-collection-source.bind = 10.1.1.100
agent_foo.sources.avro-collection-source.port = 10000
# configure other pieces
#...
Here we link the avro-forward-sink from the weblog agent to the avro-collection-source of the hdfs agent. This will result in the events coming from the external appserver source eventually getting stored in HDFS.
Fan out flow
As discussed in previous section, Flume supports fanning out the flow from one source to multiple channels. There are two modes of fan out, replicating and multiplexing. In the replicating flow, the event is sent to all the configured channels. In case of multiplexing, the event is sent to only a subset of qualifying channels. To fan out the flow, one needs to specify a list of channels for a source and the policy for the fanning it out. This is done by adding a channel “selector” that can be replicating or multiplexing. Then further specify the selection rules if it’s a multiplexer. If you don’t specify a selector, then by default it’s replicating:(fan-out,两种实现方式:replicating、multiplexing;replicating,发送给所有channel;multiplexing,发送给满足条件的channel。具体,设置selector,并指定规则;默认是replicating)
# List the sources, sinks and channels for the agent
<Agent>.sources = <Source1>
<Agent>.sinks = <Sink1> <Sink2>
<Agent>.channels = <Channel1> <Channel2>
# set list of channels for source (separated by space)
<Agent>.sources.<Source1>.channels = <Channel1> <Channel2>
# set channel for sinks
<Agent>.sinks.<Sink1>.channel = <Channel1>
<Agent>.sinks.<Sink2>.channel = <Channel2>
# set selector.type = replicating
<Agent>.sources.<Source1>.selector.type = replicating
The multiplexing select has a further set of properties to bifurcate the flow. This requires specifying a mapping of an event attribute to a set for channel. The selector checks for each configured attribute in the event header. If it matches the specified value, then that event is sent to all the channels mapped to that value. If there’s no match, then the event is sent to set of channels configured as default:(multiplexing方式时,设置header属性,根据header取值不同,分发到相应的channel;都不匹配的,分发到default)
notes(ningg):header的值,是谁设置的?在哪设置的?难道是event中自带的?
# Mapping for multiplexing selector
<Agent>.sources.<Source1>.selector.type = multiplexing
<Agent>.sources.<Source1>.selector.header = <someHeader>
<Agent>.sources.<Source1>.selector.mapping.<Value1> = <Channel1>
<Agent>.sources.<Source1>.selector.mapping.<Value2> = <Channel1> <Channel2>
<Agent>.sources.<Source1>.selector.mapping.<Value3> = <Channel2>
#...
<Agent>.sources.<Source1>.selector.default = <Channel2>
The mapping allows overlapping the channels for each value.(不同header取值对应的channel,可以重复)
The following example has a single flow that multiplexed to two paths. The agent named agent_foo has a single avro source and two channels linked to two sinks:
# list the sources, sinks and channels in the agent
agent_foo.sources = avro-AppSrv-source1
agent_foo.sinks = hdfs-Cluster1-sink1 avro-forward-sink2
agent_foo.channels = mem-channel-1 file-channel-2
# set channels for source
agent_foo.sources.avro-AppSrv-source1.channels = mem-channel-1 file-channel-2
# set channel for sinks
agent_foo.sinks.hdfs-Cluster1-sink1.channel = mem-channel-1
agent_foo.sinks.avro-forward-sink2.channel = file-channel-2
# channel selector configuration
agent_foo.sources.avro-AppSrv-source1.selector.type = multiplexing
agent_foo.sources.avro-AppSrv-source1.selector.header = State
agent_foo.sources.avro-AppSrv-source1.selector.mapping.CA = mem-channel-1
agent_foo.sources.avro-AppSrv-source1.selector.mapping.AZ = file-channel-2
agent_foo.sources.avro-AppSrv-source1.selector.mapping.NY = mem-channel-1 file-channel-2
agent_foo.sources.avro-AppSrv-source1.selector.default = mem-channel-1
The selector checks for a header called “State”. If the value is “CA” then its sent to mem-channel-1, if its “AZ” then it goes to file-channel-2 or if its “NY” then both. If the “State” header is not set or doesn’t match any of the three, then it goes to mem-channel-1 which is designated as ‘default’.
The selector also supports optional channels. To specify optional channels for a header, the config parameter ‘optional’ is used in the following way:
notes(ningg):optional channels,要解决什么问题?RE:仅当required channel中event运行失败,才有可能涉及optional channel。
# channel selector configuration
agent_foo.sources.avro-AppSrv-source1.selector.type = multiplexing
agent_foo.sources.avro-AppSrv-source1.selector.header = State
agent_foo.sources.avro-AppSrv-source1.selector.mapping.CA = mem-channel-1
agent_foo.sources.avro-AppSrv-source1.selector.mapping.AZ = file-channel-2
agent_foo.sources.avro-AppSrv-source1.selector.mapping.NY = mem-channel-1 file-channel-2
agent_foo.sources.avro-AppSrv-source1.selector.optional.CA = mem-channel-1 file-channel-2
agent_foo.sources.avro-AppSrv-source1.selector.mapping.AZ = file-channel-2
agent_foo.sources.avro-AppSrv-source1.selector.default = mem-channel-1
The selector will attempt to write to the required channels first and will fail the transaction if even one of these channels fails to consume the events. The transaction is reattempted on all of the channels. Once all required channels have consumed the events, then the selector will attempt to write to the optional channels. A failure by any of the optional channels to consume the event is simply ignored and not retried.(运行异常的事务,会尝试在所有required channels中重新运行,如果重新运行成功,则将event写入optional channels内。)
notes(ningg):transaction、event是怎么划分的?到底什么是transaction?
If there is an overlap between the optional channels and required channels for a specific header, the channel is considered to be required, and a failure in the channel will cause the entire set of required channels to be retried. For instance, in the above example, for the header “CA” mem-channel-1 is considered to be a required channel even though it is marked both as required and optional, and a failure to write to this channel will cause that event to be retried on all channels configured for the selector.(如果一个channel既是required channel,又是optional channel,则强制认定channel为required channel)
Note that if a header does not have any required channels, then the event will be written to the default channels and will be attempted to be written to the optional channels for that header. Specifying optional channels will still cause the event to be written to the default channels, if no required channels are specified. If no channels are designated as default and there are no required, the selector will attempt to write the events to the optional channels. Any failures are simply ignored in that case.(如果event,没有任何对应的required channel,则尝试写入default channel,并且尝试写入对应的optional channel;如果没有default channel,则,也会写入optional channel中。)
参考来源
原文地址:https://ningg.top/flume-user-guide/