java的编码问题:byte、char、string
2013-02-05
关注点
要解决几个问题:
- java中,出现乱码的原因?解决的基本原理?(下面两个是具体问题)
- java中,对字符串String的读取,出现乱码的解决办法?
- java中,对文件File的读写,出现乱码的解决办法?
- 补充知识:
编码:几种编码方式之间的差异:ASCII、UTF-8、GB2312、GBK、ISO8859-1;文件:java下,文件读写,效率和编码;数组:java下,基础类型(char、byte、int)数组的定义和使用
乱码
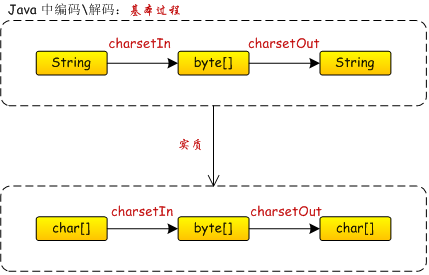
java中,对String进行编码、解码的基本过程,见上图;简要解释一下:
- 编码解码,
String通过charsetIn字符集映射为byte[],然后byte[]再依照charsetOut映射为String的过程; String是char[];- 编码解码,本质是:
char[]通过charsetIn字符集映射为byte[],然后byte[]再依照charsetOut映射为char[]的过程; charset字符集,对应编码方式,通俗说,就是一张映射表,既可以将char映射为byte,也可以将byte映射为char。
编码的基本解释
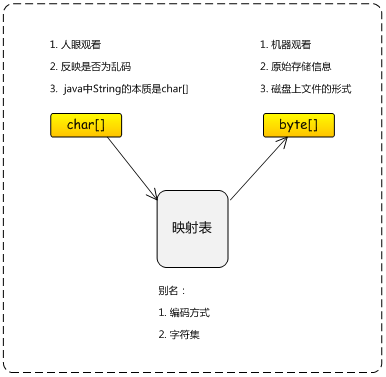
几点:
- 编码方式,字符集,都是针对
byte[]来说的,即,针对机器上存储的原始二进制字节; - 无论什么编码方式,在
char[]上是统一的;
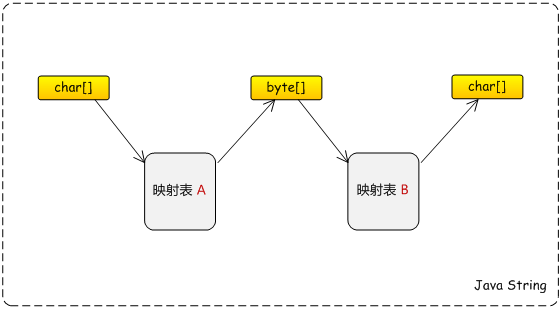
java 中 String 的编解码
java 中 File 的编解码
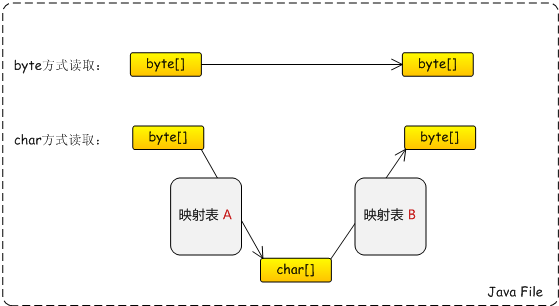
java 读写 file,有两种方式:
- 按照 byte 读取,此为文件的镜像,不涉及文件编码问题;
- 按照 char 读取,此过程中,涉及两处编码字符集:读取文件、写入文件;
何时出现乱码?如何解决?
依照前文分析的编码解码基本过程,产生乱码,本质是输入的char[]与最终输出的char[]不一致,有如下几种:
char在charsetIn字符集中不存在,无法找出对应的byte[],只能强制转换为某个默认的byte[];charsetIn与charsetOut不一致;
因此,解决乱码问题的思路也是清晰的:
- 选用合适的字符集
charsetIn,当然,尽可能大的字符集charsetIn最好,不过,能够满足需求即可; - 保证
charsetIn与charsetOut字符集完全一致;
思考:上数的讨论都是基于原始输入String为正常String,没有携带乱码,但有一种情况:原始String中自身就携带乱码,此时,如何处理?
RE:特别是,针对ASCII中的控制字符(contorl code),例如:^M、^C,此类字符,会产生转码后的换行问题,如何提前对此类字符进行处理?具体需要认真分析此类字符产生的原因,初步分析,两类场景:
- control code:当作普通字符,不进行换行、tab等特殊操作,可以直接替换为特征字符,例如:
^M,替换为Carriage return; - control code:传统用法,都是翻译成其特殊含义对应的操作吗?例如:
^M,就翻译为换行的操作;
疑问:ASCII的control code是如何输入到File中的?可以直接通过键盘输入吗?还有哪些场景?
UPDATE 2015-03-18
中文编码问题:
- 通常读取文件内容,两类:按照byte读取、按照char读取;
- 按照char方式读取会出现乱码;
- char方式在哪个阶段出现乱码?byte转换为char的时候。
- 因此,图片中展示的基本原理,而在实际情况中,是byte–char–byte–char,根据发生地点来划分的?本地的byte–char–byte,然后以byte方式发送出去,对端再将byte–char。
参考下文的示例代码即可。
字符串的编解码
几点:
- 获取
String对应的byte[]:String.getBytes(charset); - 输出
byte[]内容:Arrays.toString(byte[]) - 将
byte[]编码为String:new String(byte[], charset);
测试代码如下:
package com.github.ningg;
import java.io.UnsupportedEncodingException;
import java.util.Arrays;
public class ByteAndString {
public static void main(String[] args) throws UnsupportedEncodingException{
String inputStr = "你好, Hello";
String charset = "UTF-8";
String outputStr = null;
byte[] firstLayerByteArray = null;
// default
firstLayerByteArray = inputStr.getBytes();
outputStr = new String(firstLayerByteArray);
System.out.println("default:");
System.out.println(Arrays.toString(firstLayerByteArray));
System.out.println(outputStr);
System.out.println("-------------");
// UTF-8
charset = "UTF-8";
firstLayerByteArray = inputStr.getBytes(charset);
outputStr = new String(firstLayerByteArray, charset);
System.out.println(charset + ":");
System.out.println(Arrays.toString(firstLayerByteArray));
System.out.println(outputStr);
System.out.println("-------------");
// GBK
charset = "GBK";
firstLayerByteArray = inputStr.getBytes(charset);
outputStr = new String(firstLayerByteArray, charset);
System.out.println(charset + ":");
System.out.println(Arrays.toString(firstLayerByteArray));
System.out.println(outputStr);
System.out.println("-------------");
// GB2312
charset = "GB2312";
firstLayerByteArray = inputStr.getBytes(charset);
outputStr = new String(firstLayerByteArray, charset);
System.out.println(charset + ":");
System.out.println(Arrays.toString(firstLayerByteArray));
System.out.println(outputStr);
System.out.println("-------------");
// ISO-8859-1
charset = "ISO-8859-1";
firstLayerByteArray = inputStr.getBytes(charset);
outputStr = new String(firstLayerByteArray, charset);
System.out.println(charset + ":");
System.out.println(Arrays.toString(firstLayerByteArray));
System.out.println(outputStr);
System.out.println("-------------");
}
}
输出内容,如下:
default:
[-28, -67, -96, -27, -91, -67, 44, 32, 72, 101, 108, 108, 111]
你好, Hello
-------------
UTF-8:
[-28, -67, -96, -27, -91, -67, 44, 32, 72, 101, 108, 108, 111]
你好, Hello
-------------
GBK:
[-60, -29, -70, -61, 44, 32, 72, 101, 108, 108, 111]
你好, Hello
-------------
GB2312:
[-60, -29, -70, -61, 44, 32, 72, 101, 108, 108, 111]
你好, Hello
-------------
ISO-8859-1:
[63, 63, 44, 32, 72, 101, 108, 108, 111]
??, Hello
-------------
备注:之前写过,一个java中数组的博文,可以参考一下;
文件内容的编解码
下面示例代码,简要说明,以某一指定charsetIn读取文件,再以指定charsetOut写入文件即可;完整示例代码如下:
package com.github.ningg;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
public class FileAndCharset {
public static void main(String[] args) throws IOException {
String srcFile = "E:/1.log";
String destFile = "E:/1utf8.log";
String charsetIn = "GBK";
String charsetOut = "UTF-8";
FileInputStream fileInputStream = new FileInputStream(srcFile);
FileOutputStream fileOutputStream = new FileOutputStream(destFile);
InputStreamReader inputStreamReader = new InputStreamReader(fileInputStream, charsetIn);
OutputStreamWriter outputStreamWriter = new OutputStreamWriter(fileOutputStream, charsetOut);
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
BufferedWriter bufferedWriter = new BufferedWriter(outputStreamWriter);
String singleLine = null;
while( (singleLine = bufferedReader.readLine()) != null ){
bufferedWriter.write(singleLine);
bufferedWriter.newLine();
}
bufferedWriter.flush();
bufferedWriter.close();
bufferedReader.close();
}
}
备注:之前写过一篇Java读写File的博客,可以参考一下。
编码方式
思考:几个小疑问:
- 什么是字符集(charset)?是一个char与byte之间的映射表吗?
- 定长码、变长码;
- 存储编码、传输编码;
几种编码方式之间的联系:
ASCII
ASCII:American Standard Code for Information Interchange(信息交换,美国标准码);简单说几点:
US-ASCII:原始的ASCII
- 1963年
- 7-bit(128个字符)
- letters、numerals、symbols、device control code
- fixed-length
但是,计算机中一个byte有8bit,因此,就打起了剩余1-bit的主意:
- ISO 8859,针对8-bit ASCII extensions部分,定义的规范;
- ISO 8859-1,又称,
ISO Latin 1,针对西欧常用语言(Western European Language)的拓展; - ISO 8859-2,东欧常用语言(Eastern European Language)的扩展;
一个byte,8 bit,并不能满足所有character encodings的需要,因此出现了multi-byte character encodings,整体上两类:
- Extended ASCII:多字节编码时,ASCII已经表示的字符,仍用ASCII的8-bit表示:
- 保留
0x00-0x7F来标识原始的ASCII; - 启用
0x80--0xFF来标识多字节的字符; - 典型代表:UTF-8
- 保留
- 非 Extended ASCII:不保留单字节的ASCII表示;
GB2312
整体上说一下GB2312、GBK、GB18030几种编码之间的关系:
- GB2312,固定码,2 byte:
- 简体汉字
- 原有的拉丁字母、数字、符号,编码进去,称为
全角; - 原有US-ASCII(7 bit)的拉丁字母、数字、符号,称为
半角;
- GBK
- 繁体字
- 生僻字
- 当前软件,支持GBK的较多,而相对GB18030更为普及
- GB18030
- 少数民族字符
- 生僻字
备注:GB,Guojia Biaozhun(国标);
几点:
- GB2312,为GBK、GB18030的子集;
- GBK\GB18030,相对于GB2312,在罕见字、繁体字上,有增强;
- GB2312,包含
6763个中文字符; - GB2312,对应一个
94x94的表格,每个空格(codepoint),都是two-byte(2 bytes); EUC-CN(Extended Unix Code),GB2312标准的常用实现,同时兼容ASCII(0x00-0X7F,最高位为0);- 1st byte:
0xA1-0xF7;(最高位为1) - 2nd byte:
0xA1-0xFE;
- 1st byte:
疑问:EUC,官网提到,其是ISO-2022标准的实现,多字节编码,最大可包含G0`G1\G2\G3,4个字节;其中G0通常兼容ISO-646标准(US-ASCII`),但GB2312为 2 byte的定长字符集,这可如何是好?
RE:
- charset,字符集,标识char与byte之间的映射关系;
- GB2312标准,ISO-2022标准,是标准,而不是char与byte之间映射的字符集;
- GB2312标准,只说明了原理:用2byte标识,而没有设定每个char对应的byte一定要为多少,具体实现方式可以调整;
- ISO-2022标准,说明原理:最多可以利用 4 byte来标识字符;
EUC-CN(Extended Unix Code),是具体实现,满足GB2312和ISO-2022两个标准;(有时,EUC-CN为GB18030标准和ISO-2022标准的具体实现)
相对于UTF-8,GB2312效率更高,几点:
- 没有保留bits,用于标识 3 byte 或 4 byte;
- 没有保留bit,用于detect tailing bytes;(什么含义?需要检测末尾byte吗?之前Huffman coding,变长编码,不需要额外的字节,来标识tailing bytes)
思考:
- GB2312中包含ASCII中已经包含的英文字符吗?
- GB2312标准中,不包含ASCII;但其实现方式:EUC-CN,除了支持GB2312(2 byte)之外,还兼容ASCII(1 byte);
- 若包含ASCII的英文字符,那英文字符占几个字节?
- EUC-CN:实现GB2312的字符,字节高位为
1;ASCII的字符,字节高位为0; - EUC-CN:为变长编码,既包含 2 byte的GB2312字符,也包含 1 byte的ASCII字符;
- EUC-CN:实现GB2312的字符,字节高位为
建议:推荐使用大字符集,GBK、GB18030;
GBK
几点:
- GBK:Guojia Biaozhun Kuozhan;
- 简体中文、繁体中文;
- 字符集:
- GB2312
- ASCII
GB18030
几点:
- 同时兼容
GB2312和GBK两个标准; - 是Unicode的一种?支持简体字、繁体字;
- Unicode Transformation Format(an encoding of all Unicode code points);
- 字符集:
- ASCII
- GB2312
- GBK
- 具体编码实现:
- 1 byte
- 2 byte
- 4 byte
更多阅读:
Unicode
几点:
- 目标:通用字符集;
- 包含100,000+的字符;
- 前256个字符,保留给ISO-8859-1,基本的拉丁字母(西欧语系的字母);(基本的拉丁字母用途太广泛)
- 具体实现:
- UTF-8
- UTF-16
- UTF-32
UTF-8
几点:
- 基于Unicode标准的一个具体实现方式;
- 完全兼容
ISO-8859-1编码方式;(第一字节,兼容ASCII) - 变长码,每个字符使用1-3个byte编码,并利用首位
0或1进行识别; - Unicode的实现方式称为
Unicode转换格式(Unicode Transformation Format,简称UTF) - 补充:UTF-8编码方式,中文占 3 byte;
具体:
- 128个US-ASCII字符只需一个字节编码(Unicode范围由U+0000至U+007F)。
- 带有附加符号的拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文、叙利亚文及它拿字母则需要两个字节编码(Unicode范围由U+0080至U+07FF)。
- 其他基本多文种平面(BMP)中的字符(这包含了大部分常用字)使用三个字节编码(Unicode范围由U+0800至U+FFFF)。
- 其他极少使用的 Unicode 辅助平面的字符使用四至六字节编码(Unicode范围由U+10000至U+1FFFFF使用四字节,Unicode范围由U+200000至U+3FFFFFF使用五字节,Unicode范围由U+4000000至U+7FFFFFFF使用六字节)
网络上数据编码的演进趋势:(网络上传输的byte,是char通过哪种字符集映射过来的?)
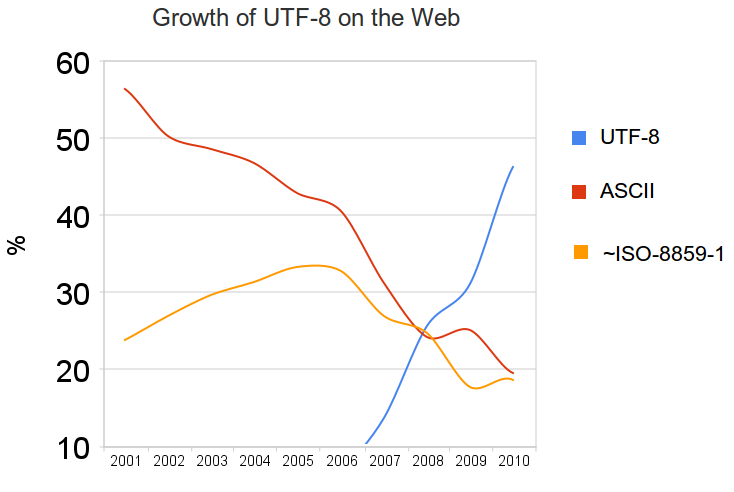
附录
Huffman coding
Huffman coding,霍夫曼编码:
- 基本原则:符号的编码长度,按照符号出现概率大小,逆向排序;
- 最优二叉树:带权路径长度最小的二叉树;
- 常用语数据压缩,无损耗压缩,是一致性编码(“熵编码”);
- 具体操作:按概率大小排序,最小的两个概率相加,迭代到总概率
1;
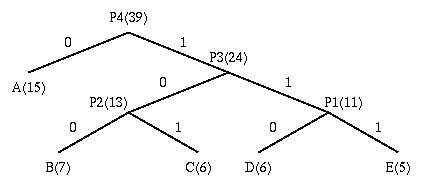
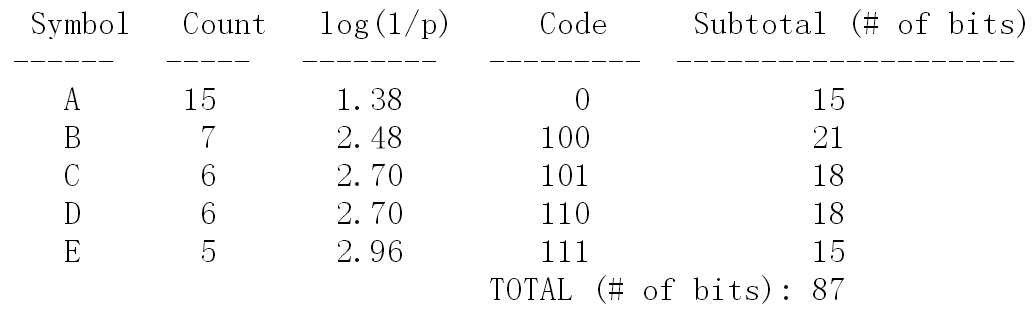
更多阅读,参考Huffman coding。
字母体系
世界三大字母体系:
- 拉丁字母
- 斯拉夫字母
- 阿拉伯字母
拉丁字母(下图):

备注:中国的汉语拼音方案,也是以拉丁字母为基础的。
斯拉夫字母(下图):

阿拉伯字母(下图):

utf_unicode_ci和utf8_general_ci
在数据库系统MySQL中有多种字符集,其中utf8_unicode_ci和utf8_general_ci是最常用的,但是utf8_general_ci对某些语言的支持有一些小问题,如果可以接受,那最好使用utf8_general_ci,因为它速度快。否则,请使用较为精确的utf8_unicode_ci,不过速度会慢一些。
多语言无差错,首选“utf_unicode_ci”。
全角 & 半角
信息交换用汉字编码字符集·基本集对应的是GB2312,其中也指定了拉丁字母(英文字母)对应的 2 byte编码,这个只有在全角情况下,才输入GB2312字符集中的拉丁字母,而半角时,输入的为ASCII下的拉丁字母编码;
备注:上述查询文档中,字符对应的二进制表示时,借助工具UltraEdit中的十六进制模式。
关于全角`半角`,几点:
- 输入汉字,全角、半角,没有区别,对应的GB2312编码完全一致,2 byte;
- 输入英文字母、符号、数字,有区别:
- 全角:使用GB2312中对应的编码,占用 2 byte;
- 半角:使用ASCII中编码,占用 1 byte;
- 补充:全角存在的意义是,方便显示的整齐和美观;
参考来源
- ASCII wiki
- Extended ASCII wiki
- Character Encoding wiki
- Extended Unix Code wiki
- Huffman coding
- Unicode wiki
- UTF-8 wiki
- Unicode wiki(中文)
- ISO-8859-1 wiki(中文)
- UTF-8 wiki(中文)
- 信息交换用汉字编码字符集·基本集
- 字符编码笔记:ASCII,Unicode和UTF-8
推荐:此次编码相关的中文wiki内容;
原文地址:https://ningg.top/java-encode-byte-char-string/