大型网站架构:高可用
2015-07-03
1. 概要
目标:如何判断网站的可用性?如何提升可用性?
几个问题:
- 指标:哪些指标,可以衡量系统的可用性?
- 监控:如何测量这些指标?常用思路和工具?
- 改进:提升系统可用性,常用的措施?这些措施是如何提升可用性指标的呢?
2. 指标
指标:
- 可用性指标:系统可用时间/系统运行时间
- CaseStudy:针对重大的故障,要进行 case study 分析和故障评级,解决通用可用性指标无法衡量不同重要程度服务的弊端。
2.1. 可用性指标
可用性指标:系统可用时间/系统运行时间
- 上面采用时间来描述,测量起来有难度,因此
退化为服务次数 - 可用性指标 = 调用成功的次数/所有调用的次数
Note:
- 这个可用性指标,是通用的指标,能够满足通用的业务需求;
- 具体业务场景下,不同服务的重要程度不同,把所有的服务混为一谈,进行平均计算,无法反应真实情况;
- 一般解决办法,服务分级,针对同一级服务归类统计。
可用性指标的物理意义:
| 级别 | 描述 | 表示 | 物理含义:年度停机时间 |
|---|---|---|---|
| 2个9 | 基本可用性 | 99% | 100 h |
| 3个9 | 较高可用性 | 99.9% | 10 h |
| 4个9 | 自动恢复可用性 | 99.99% | 1 h (53 mins) |
| 5个9 | 极高可用性 | 99.999% | 5 min |
2.2. CaseStudy & 故障分级
常见的故障分级表示:

3. 监控
没有监控的系统,不允许上线。
没有监控,就如同遛狗不拴绳,狗迟早会丢。
关于监控:
- 监控的哪些数据?
- 监控的实际意义是什么?
3.1. 监控前:数据采集
监控各种东西,都要求进行数据采集,一般,从 3 个层次,采集数据:
- 用户层:用户行为,来源,地理位置,客户端版本
- 应用层:应用吞吐量
- 系统层:系统负载
3.1.1. 用户层
一般收集的数据涵盖:
- 操作系统
- 浏览器版本
- IP 地址
- 页面访问路径
- 页面停留时间
这些数据,用于分析:网站的 PV/UV,用户行为,个性化推荐等。
常用思路:
- 服务器端:后端埋点、Web 的 log 日志
- 客户端:前端埋点
3.1.2. 应用层
应用的吞吐量、响应时间;
缓存的命中率、等待处理的任务数等;
3.1.3. 系统层
系统负载、内存、网络、磁盘 IO 等
3.2. 监控后:管理
有了监控的数据,就可以进行:
- 系统性能评估:流量预估等
- 集群规模伸缩性预测
- 风险预警
- 自动负载调整
- 失效转移
最大化利用系统资源。
4. 改进
4.1. 系统拆分
系统拆分,主要思路 2 种:
- 水平分层:按照功能分层,应用层、服务层、数据层,每层的特性不同,可用性要求不同,优化措施也有差异;
- 垂直分割:按照业务拆分,多个业务子系统;
一般系统会综合上述 2 种思路进行,保证系统高可用时,主要从水平分层的维度说明。

高可用的思路:
- 应用层、服务层:
- 负载均衡:服务正常的时候,进行负载均衡
- 失效转移:单个应用节点/服务节点发生故障时,自动进行转移
- 数据层:
- 冗余备份:数据服务正常时,进行冗余备份
- 失效转移:单个数据服务节点发生故障时,自动进行转移
磁盘的问题:高强度、频繁读写的普通硬盘,损坏的概率很大,一般一年一次。
Note:
系统高可用,一般:
- 应用层、服务层:
负载均衡+失效转移- 数据层:
冗余备份+失效转移
4.2. 分层高可用
系统水平分层之后,各个层之间具有一定的独立性:
- 应用层:具体业务逻辑
- 服务层:可复用的服务
- 数据层:数据存储与访问
4.2.1. 应用层
高可用的基本过程:
- 负载均衡:通过负载均衡服务器,将应用集群组合起来,一起对外服务
- 心跳检测:负载均衡服务器,通过心跳检测,监控各个应用服务器的运行情况,如果服务器不可用,则从集群列表中剔除
- 失效转移:单个服务节点不能正常工作时,自动剔除
负载均衡的软件和硬件,都提供「失效转移」功能。
思考:心跳检测,有一个时间间隔,这个间隔内,如果应用不可用,则,仍然会导致应用可用性降低?
定期心跳检测:间隔时间内,导致系统可用性降低事件触发心跳检测:单次单节点应用不可用时,触发一次心跳检测
fallback 机制:单节点应用不可用时,自动切换到 fallback 指定的机器上,failover (失效转移)
TODO:
- 分析 Nginx 中 fallback 机制原理 & 使用
Session 管理的应用服务集群:
- 无状态应用,负载均衡很简单
- Session 管理需要单独抽离
- Session 最基础的功能:通过 Session ID 来识别用户的登陆状态和身份, Session ID 会设置一个有效时间
- Servlet 容器(服务器),一般已经继承了 Session 管理功能
应用集群的 Session 管理:
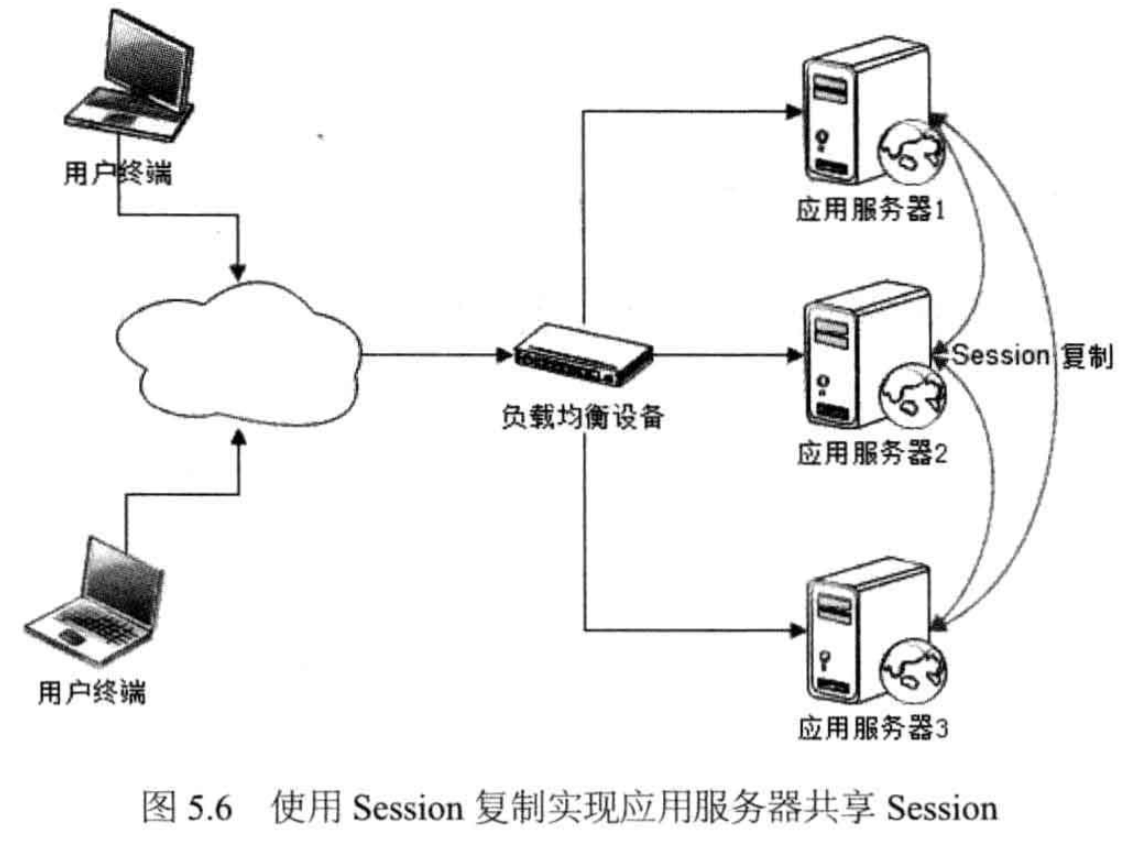
- Session 复制:所有的机器都复制一份 Session
- 优点:方案简单、本机读取 Session 速度快
- 劣势:适用小规模集群,针对大规模集群,Session 的同步复制会耗费大量服务器和网络资源,极端情况下,大量用户并发访问时,Session 占用内存过多,应用崩溃。
- 现状:大型网站架构,很少使用此方案
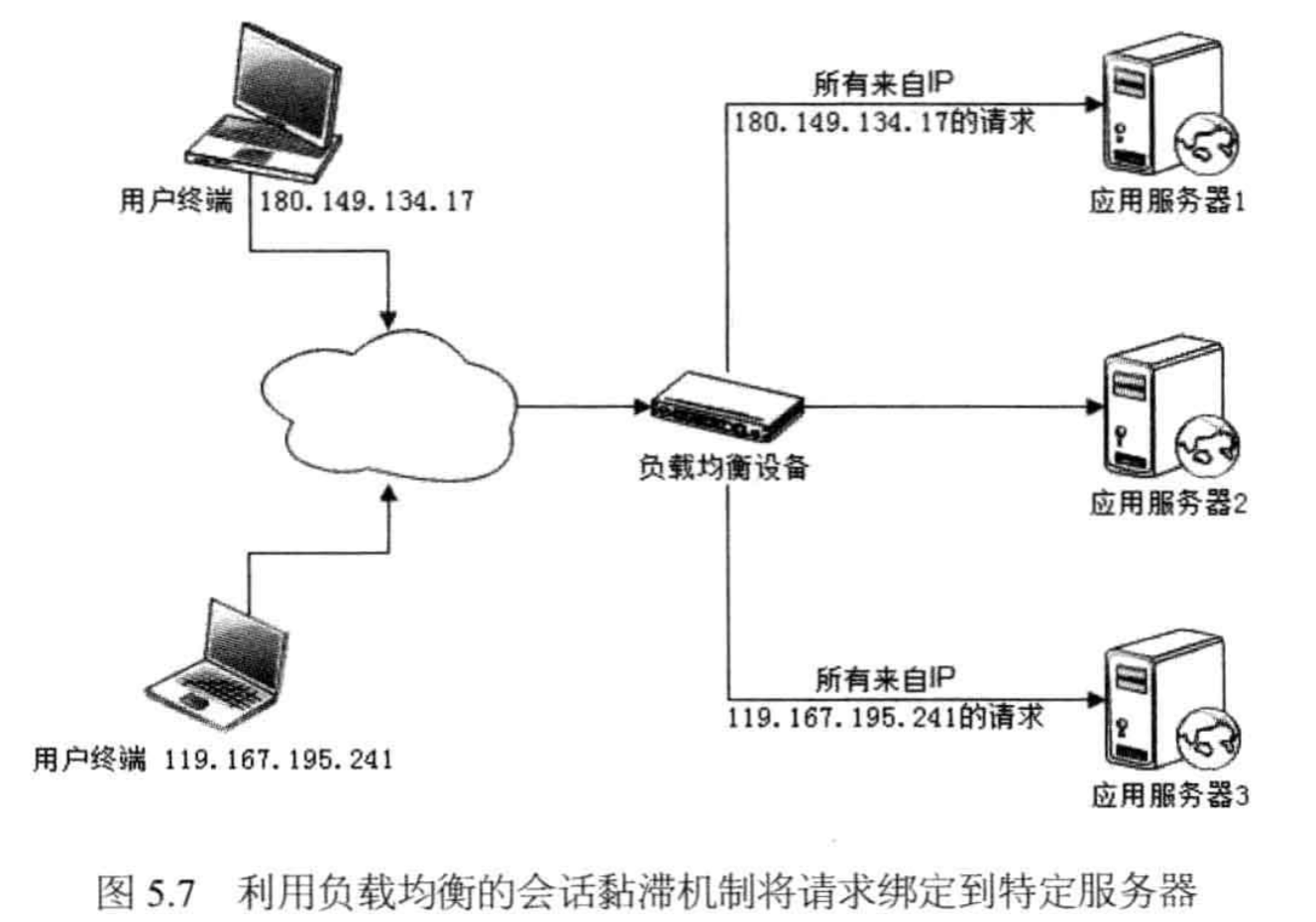
- Session 绑定:将同一个客户端来源的请求,映射到同一个应用节点上,称为「会话黏滞」
- 要点:客户端的唯一标识,一般使用「源IP 地址」,或者,服务后台产生后,存放到 Cookie 中
- 优点:方案简单、本地读取 Session 速度快
- 劣势:不符合高可用的要求,单台服务器宕机,会丢失一部分用户的登陆状态和信息
- 现状:大部分负载均衡服务器,都提供源地址负载均衡算法,但很少应用到现实场景
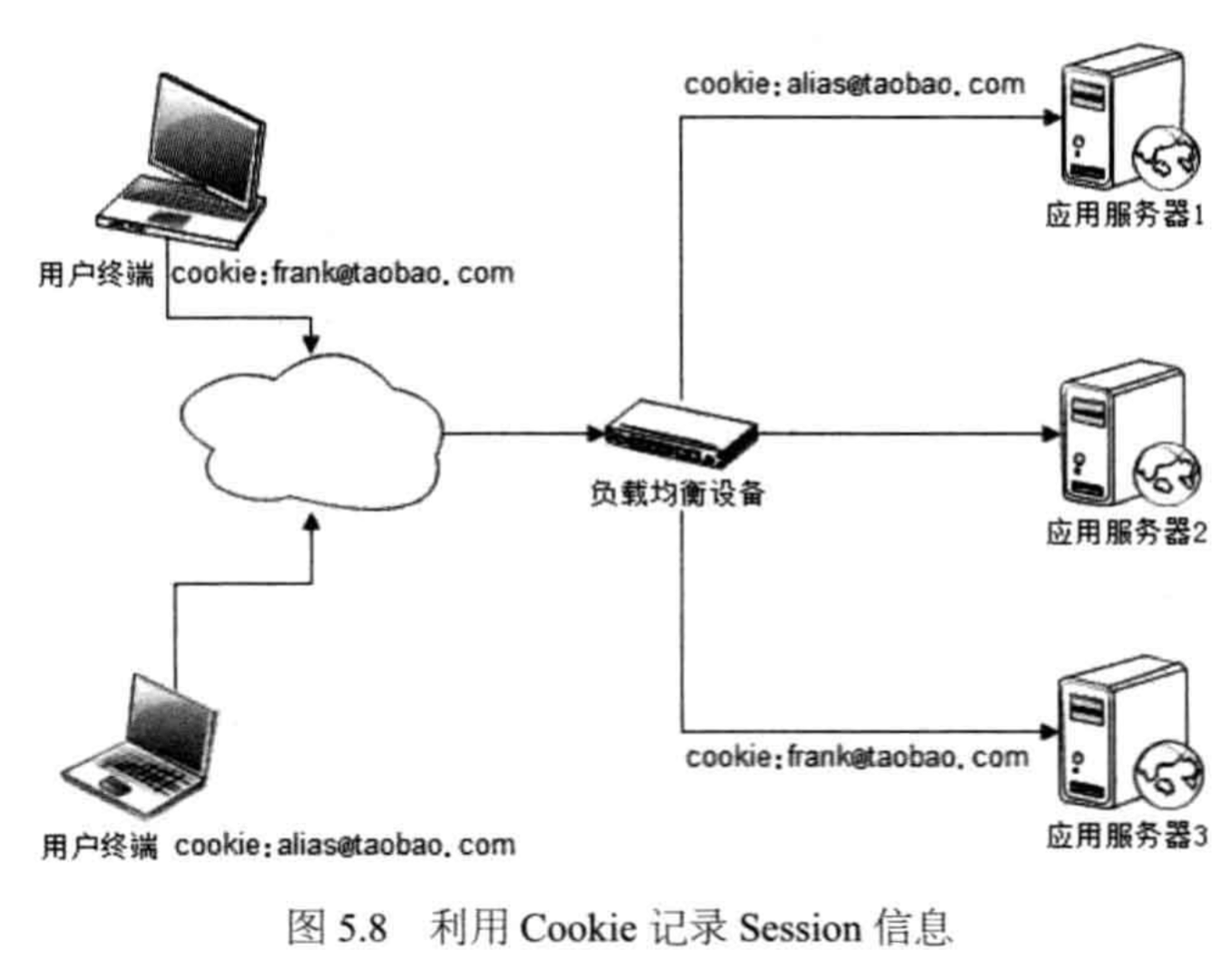
- Cookie 记录 Session 信息:将 Session 中的信息,记录在 Cookie 中,即,将服务端 Session 中的信息,记录在 Client 的 Cookie 中
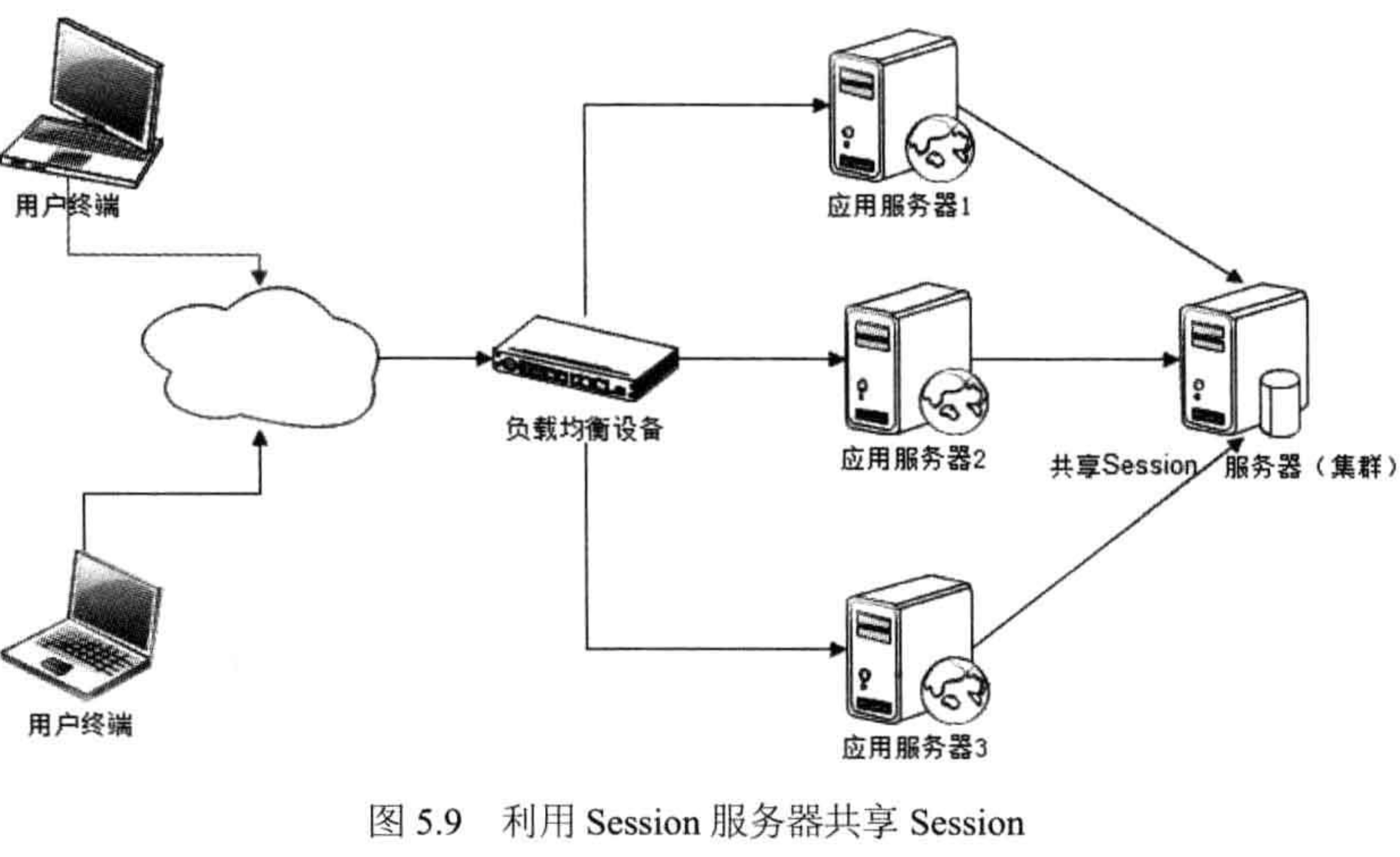
- 独立的 Session 服务器(集群):本质,将应用服务器的状态分离,分为,有状态的 Session 服务器和无状态的应用服务器
- 要点:应用服务器的状态分离,状态信息放到独立的 Session 服务器上
- 优点:高可用、高可靠、可伸缩性好
- 劣势:需要独立的服务器,性需要 RPC 调用
- 现状:适用业务场景对 Session 管理要求比较高,比如,利用 Session 服务器集成单点登录(SSO)、用户服务等
具体图示:
4.3. 服务层
服务层,一般是「可复用的服务模块」,这些服务:
- 独立部署
- 无状态
因此,服务层高可用策略:负载均衡 + 失效转移。
此外,还有一些常用策略,用来实现服务层的高可用:
- 分级管理:
- 在硬件上,核心服务和应用,单独部署物理机,比如,订单、支付服务等
- 在软件上,高优先级的服务,部署在不同的虚拟机或者单独的线程,避免连锁反应
- 超时设置:
- 用户请求,长时间得不到响应,仍然会占用资源
- 超时的原因:服务器宕机、线程死锁等
- 设置超时时间,如果超时,则抛出异常,中止执行,应用程序根据业务场景,判断是否:失败重试(failcache)还是转移到另一台服务器(failover)
- 异步调用:
- 对于可以延迟执行的任务,就延迟执行
- 不需要及时响应的任务,可以通过 MQ 异步执行;例如,用户注册成功的邮件通知
- 备注:下列场景特别注意
- 获取用户信息类场景
- 必须服务调用成功才能进行下一步操作:连续操作的依赖性
- 服务降级:访问高峰期,服务可能因为高并发的访问而引发负载飙升,甚至宕机
- 降级策略:拒绝服务、关闭服务
- 拒绝服务:
- 拒绝低优先级的调用,以此减少服务调用并发数,确保核心服务
- 随机拒绝部分用户请求,实现削峰
- 关闭服务:关闭部分不重要的服务,以此节约系统开销,例如,淘宝双十一系统最繁忙时段,关闭评价和确认收货的服务
- 拒绝服务:
- 降级策略:拒绝服务、关闭服务
- 幂等性设计:系统多次调用,获取相同的执行结果
- 幂等设计的必要性:服务调用失败后,failover 或者 failcache,再次发起服务调用时,「服务的重复调用」是无法避免的
Note:
服务层,高可用的策略:
分级、超时、异步、服务降级、幂等。
分布式服务框架:常用框架
4.4. 数据层
数据层高可用,整体策略:冗余备份 + 失效转移
- 冗余备份:数据存储多个副本,任意副本的丢失,都不会导致数据永远丢失
- 失效转移:某一个数据副本不可用时,切换到可用的副本上
数据层:
- 缓存层:不要求高可用,但是要求高性能和可扩展性
- 持久化存储层
4.4.1. CAP 原理
分布式领域 CAP 理论:
- Consistency,一致性:数据一致更新,所有数据变动都是同步的
- Availability,可用性:读和写操作都能成功
- Partition tolerance,可靠性:分区容错,出现网络故障导致分布式节点间不能通信时,系统仍能提供服务
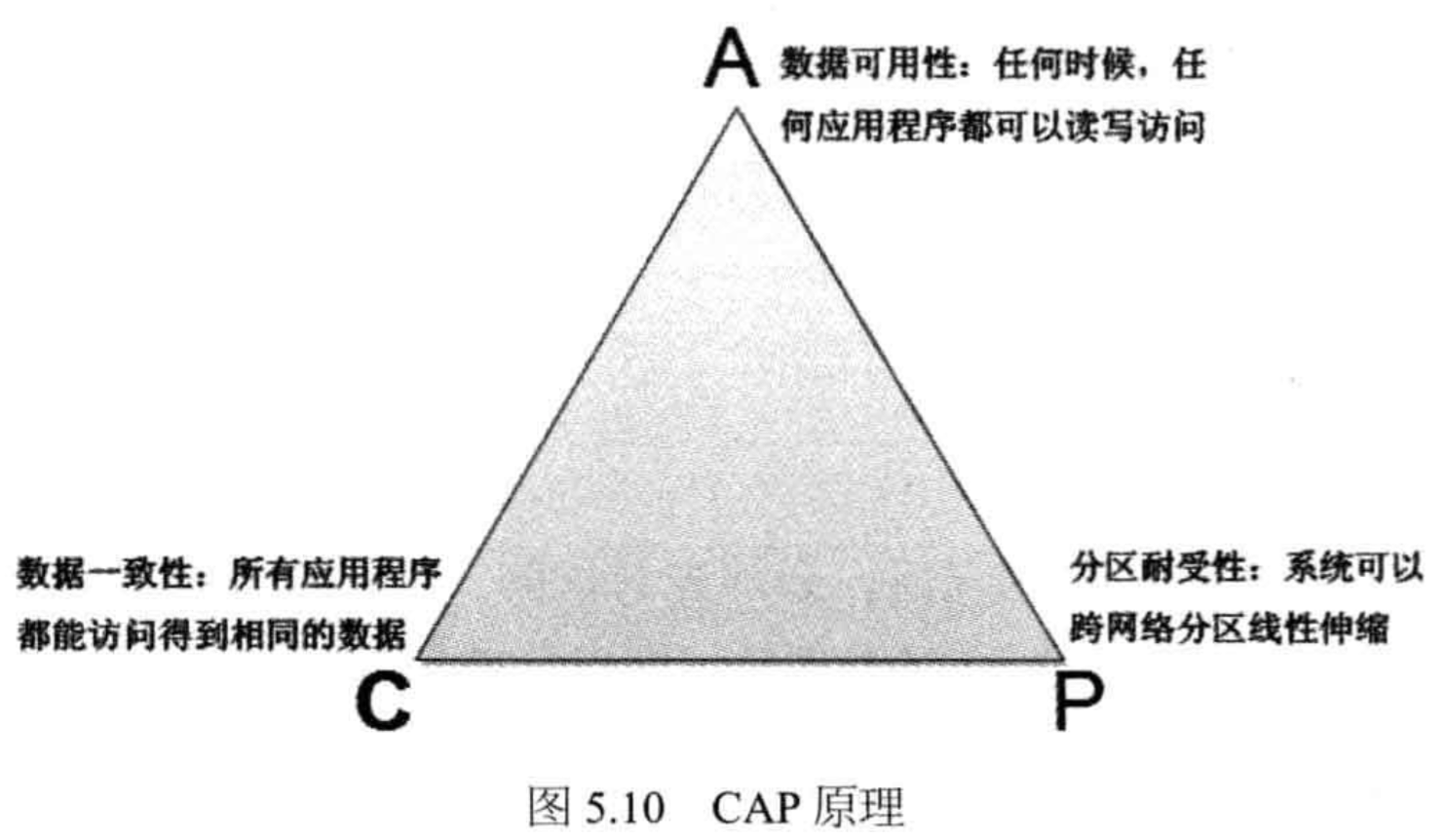
定理:任何分布式系统,只可能同时满足两点,无法三者兼顾。架构师应该在CAP上做好取舍。
一个DB服务搭建在两个机房(北京,广州),两个DB实例同时提供写入和读取,不同方案下,出现网络故障时,均无法同时保证CAP:
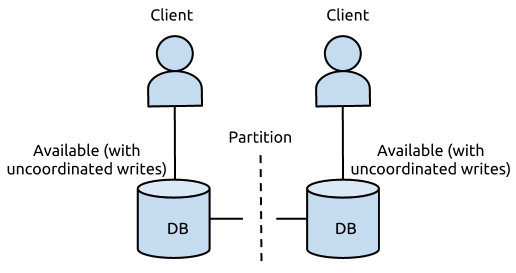
1. 假设DB的更新操作是同时写北京和广州的DB都成功才返回成功
同步更新,数据强一致,无法满足分区耐受性,可满足CA原则:
- C 即我的任何一个写入,更新操作成功并返回客户端完成后,分布式的所有节点在同一时间的数据完全一致;
- A 即我的读写操作都能够成功;
- 但是当出现网络故障时,我不能同时保证CAP,即P条件无法满足
2. 假设DB的更新操作是只写本地机房成功就返回,通过 binlog 回放方式同步至侧边机房
异步更新,数据最终一致,无法满足数据一致性,可满足 AP 原则:
- 保证了在出现网络故障时,双边机房都是可以提供服务的,且读写操作都能成功,意味着他满足了AP ;
- 但是它不满足C,因为更新操作返回成功后,双边机房的DB看到的数据会存在短暂不一致,且在网络故障时,不一致的时间差会很大(仅能保证最终一致性)
3. 假设DB的更新操作是同时写北京和广州的DB都成功才返回成功且网络故障时提供降级服务
服务降级:
- 降级服务,如停止写入,只提供读取功能,这样能保证数据是一致的,且网络故障时能提供服务,满足CP原则,但是他无法满足可用性原则
4.4.2. 数据一致性
数据一致性,包含下面几类:
- 强一致:多个数据副本中,数据始终是一致的,一般数据同步更新
- 用户一致:多个数据副本的数据,可能是不一致的,但终端用户访问时,通过纠错和校验机制,保证返回给用户的是一致且正确的数据
- 最终一致:物理存储的多个数据副本,不是一致的,用户的多次访问数据也是不一致的,但经过一段时间(通常比较短的时间)系统的自我恢复和修正,数据会达到最终一致
4.4.3. 数据备份
数据备份,常见有几类:
- 冷备份:定期复制一次数据
- 特点:简单、廉价,成本和技术难度低
- 数据一致性:不能保证,连数据最终一致性都不能保证
- 数据可用性:不能保证,因为从冷备中恢复数据也需要较长的时间
- 热备份:实时备份数据
- 异步热备:成功写入一份数据,其他副本,进行异步更新
- 同步热备:成功写入所有副本数据
4.4.4. 失效转移
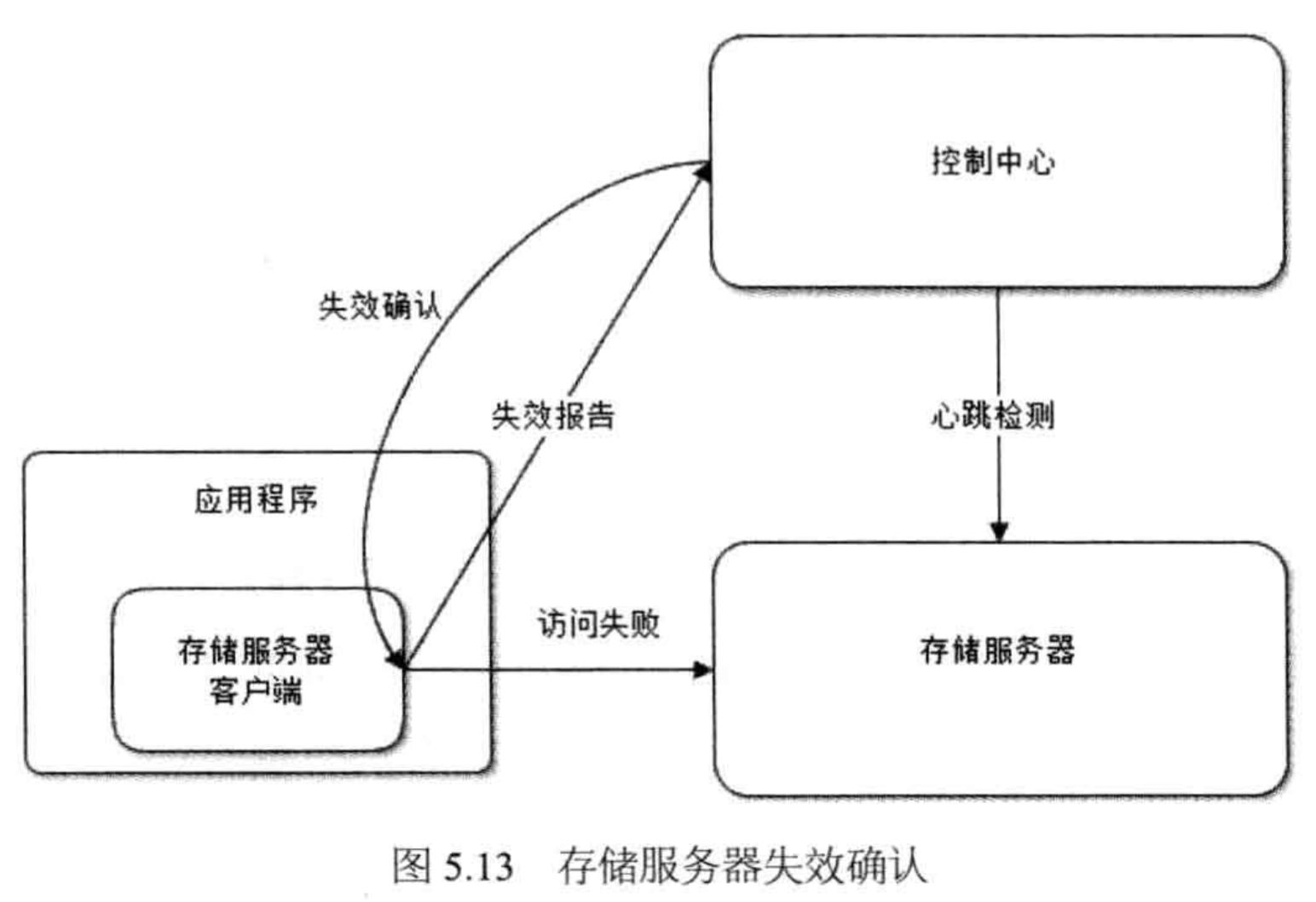
失效转移的基本步骤:
- 失效确认:控制中心,确认 Master 失效
- 访问转移:启用备份,替代 Master
- 数据恢复:将副本个数,恢复到系统设定值
失效确认,一般,2 种方式:
- 调用方的失效报告:控制中心,收到失效报告后,仍会发起一次心跳检测,因为失效转移的成本比较大,要尽可能避免误判
- 控制中心的心跳检测
5. 流程的高可用
上面从软件、硬件、系统架构上,讨论了网站的高可用,实际上,有很多流程上也可以优化,来提高网站的可用性。
5.1. 自动化测试
增加新功能时,对原来功能也要进行测试,这一部分的人工测试,时间、成本以及覆盖率都难以接受。引入自动化测试,覆盖之前的功能点,对于新增功能点,采用人工测试手段,保证质量。
5.2. 无损发布
无损发布,先把流量切走,再发布系统,避免发布期间,系统不可用:
- Nginx:切走部分流量
- 健康检查:health check,确保应用启动成功
- Nginx 也提供 health check 功能,但无法上报异常
- 一般是:curl URL,在 web server 上,直接测试,如果失败,则直接灰姑娘,不需要依赖 Nginx
5.3. 灰度发布
每次发布一部分机器。
5.4. 自动发布
自动化系统(脚本),完成一系列的发布操作,避免人工的错误。
6. 参考资料
- 《大型网站技术架构:核心原理与案例分析》第5章 万无一失:网站的高可用架构
原文地址:https://ningg.top/large-scale-web-app-tech-2/