Pig解析中文文档
2014-05-09
Pig处理文档时,LOAD和STORE默认数据是UTF-8编码格式(参考来源?官方文档/源码)。因此,包含中文字符的数据文档,应以UTF-8格式存储;相应的包含中文字符的pig脚本,也应以UTF-8格式存储。
本文简介:
- 中文文档如何转码,特别是
Linux下利用iconv命令转码时的注意事项; - 使用
SecuryCRT/putty客户端连接服务器时,中文文档显示乱码的解决办法; - Pig脚本解析中文文档的步骤;
将文档存储为UTF-8格式
在windows下,可以使用notepad++来进行文档转码:
Encoding–Convert to UTF-8 without BOM,则当前文档转换为UTF-8编码方式。
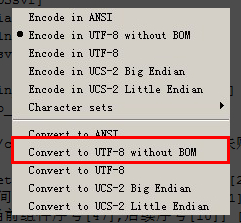
(思考:文档编码格式转换的原理?在linux下有没有类似的转换工具/命令?)
补充:
Linux下使用iconv可以进行编码格式转换,具体操作如下:
查看文档编码方式:
file –i origin.txt

对文档转码:
// 下面命令中 origin.txt.utf8为输出文件。
iconv –f ISO-8859-1 –t UTF-8 < origin.txt > origin.txt.utf8
特别说明:
如果iconv转码命令,出现iconv: illegal input sequence at position 42错误信息,则可以使用如下命令进行转码:
iconv –f gbk –t UTF-8 < origin.txt > origin.txt.gbk
(思考:上面的原因是否是file命令查询结果不精确,查询文件的编码方式,linux下还有其他的命令吗?)
(思考:不同的编码格式的差异?为什么有多种编码?对应的应用场景?)
iconv转码出错[重要]
当对1G以上的大文件,进行转码时:如果按照如下命令进行转码:
// 下面命令中 origin.txt.utf8为输出文件。
iconv –f gbk –t UTF-8 < origin.txt > origin.txt.utf8
可能仍然会出错:iconv: illegal input sequence at position 91401042,查看origin.txt.utf8文件,其内中文已经正常显示,只是原始文件在某个位置出现问题,没能完成整个文档的转码。
原因排查:是否是原始文件中真的有字符无法转码?还是文件过大?
排查措施:使用split、head等命令对文件分割之后,在相应位置仍然出错;
原因确定:是原始文件有非法字符,GBK中不存在的编码,GBK自己无法识别,因此无法转码。
解决途径:
- 删除有乱码的行?(使用wc –l 、 sed –i 等命令;)
- 跳过有乱码的几个字符?
iconv有没有强制转换,忽略/跳过错误?(尼玛,恭喜你,猜对了,有这么个机制)- 使用
man iconv查询不到,应该使用iconv –help,查看命令的帮助。
最终命令:
iconv –f gbk –t utf-8//IGNORE < input > output
搞定。
参考来源:
[1] http://www.aiezu.com/system/linux/linux_iconv_code.html [2] http://www.linuxquestions.org/questions/linux-newbie-8/usr-bin-iconv-illegal-input-sequence-at-position-905152/
将文档传到远端linux服务器
注意:在传输过程中,应尽量保持文档的属性/编码方式保持不变。
仅仅是将windows下文档传递到远端linux服务器上,方法很多:fileZilla、WinSCP等,下面说一种不需要安装软件的方法(亲,不要想错了,需要下载软件的,只是软件很小,不需要安装)。
下载PSCP,文件300k,果真很小;现在工具有了,如何利用PSCP来向远端linux传送文件呢?操作如下:
//-p : preserve file attributes.(传送过程中,保持文件属性不变)
scp –p originalFile user@ip:/home/user/destFold
上面命令会将本地originalFile文件,无失真传送到服务器/home/user/destFold目录下。
在远端linux服务器上,如何查看文档的具体编码方式呢?
file –i filename
可以使用上述命令来确认文件的编码方式。
现在按照utf-8编码的文件,已经在服务器上了,那原材料就齐全了,开始处理吧。
远端服务器上,中文显示乱码
既然要操作远端linux服务器,最好要建立持久的连接,常用的方式:putty、secureCRT。然而,查看服务器上的中文文档时,可能出现乱码。
服务器的基本环境
针对上述情况,需要先检查一下服务器上设置的语言环境。
echo $LANG
// 上述输出结果为:en_US.UTF-8
更进一步,查看3个文件,看LANG具体如何配置的:
cat /etc/sysconfig/i18n
//上述输出结果为:LANG=”en_US.UTF-8”
cat ~/.bash_profile
//上述输出结果中,没有LANG的配置
cat ~//.bashrc
//上述输出结果中,没有LANG的配置
(思考:LANG的配置有什么用?LANG不就是个环境变量吗?)
Putty连接服务器
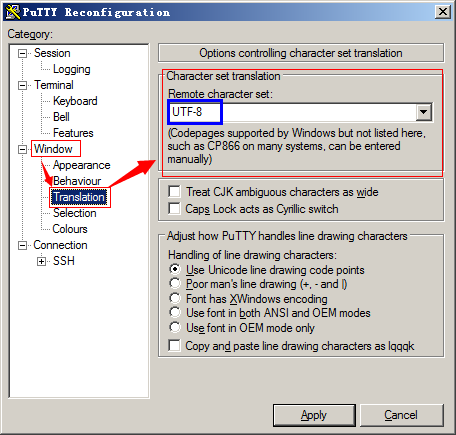
设置方式:
Window–Translation–Character set translation–Remote character set,选中“UTF-8”。
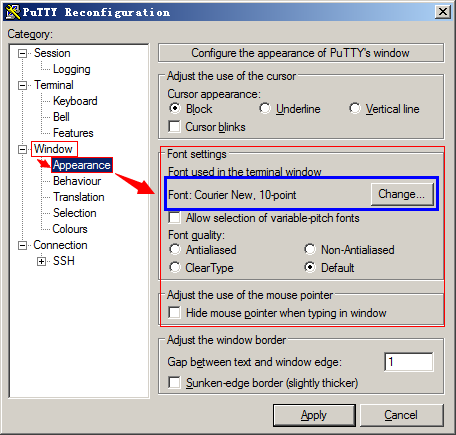
Window–Appearance–Font settings–Font used in terminal window,选中Courier New(尝试其他字体也可以解决中文乱码)。
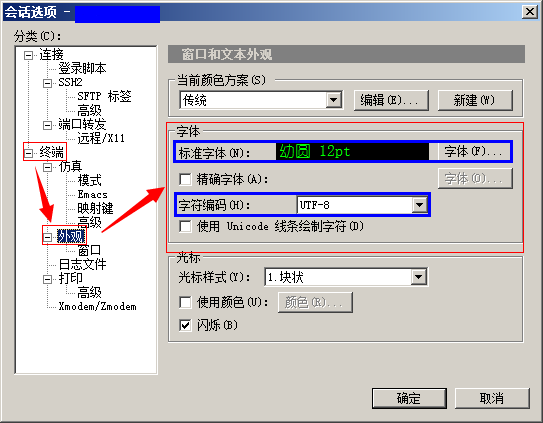
SecureCRT连接服务器
选项–会话选项–终端–外观–字体,字符编码选中UTF-8;
标准字体选中幼圆(宋体等其他也可以)
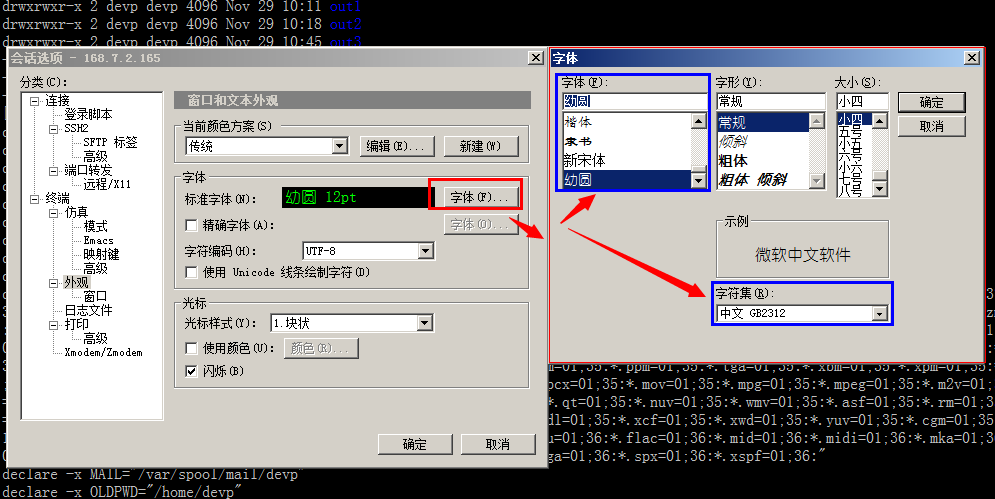
OK,到现在位置,使用putty/secureCRT连接远程服务器,再查看UTF-8编码的中文文档时,就不会出现乱码了。下面测试一下效果:
less filename

Pig脚本解析中文文档
千呼万唤始出来、犹抱琵琶半遮面,使用pig来解析中文文档是本文的重点,却姗姗来迟。好的,先来回顾一下前面的工作:
- 将pig脚本
select_rows.pig使用UTF-8格式编码、待分析的文档sfzf.log也使用UTF-8格式编码; - 将两个文件传送到linux服务器上,并且使用
file –i filename命令查看,确保其都为UTF-8的编码格式; - 设置
secureCRT或者putty,保证其查阅中文文档时,无乱码; - 到这一步了,直接运行pig脚本
select_rows.pig就可以了~哈哈(对,pig解析中文文档,就这么简单);
Pig脚本select_rows.pig内容如下:
/* 查找输入文档中,包含关键字“时间”的行,并输出 */
A = load '$input' as (col1:chararray);
B = filter A by ($col1 matches '.*时间.*');
store B into '$output';
运行命令:
pig –x local –param input=sfzf.log –param output=out4 select_rows.pig

原文地址:https://ningg.top/pig-deal-with-chinese/