分布式锁:方案分析(Redis 典型方案)
2015-12-18
0.概要
几个方面:
- 分布式锁简介
- 作用:分布式锁,有什么用
- 使用:基本使用过程
- Redis 实现分布式锁
1.分布式锁简介
分布式锁简介,从 3 方面进行:
- 作用:分布式锁,有什么用?
- 使用:分布式锁,如何使用?
- 实现:分布式锁,几种典型的实现方式
1.1.作用 & 典型用法
作用:分布式场景下,出现竞争资源时,为了保证有序获取资源,需要依赖「分布式锁」。
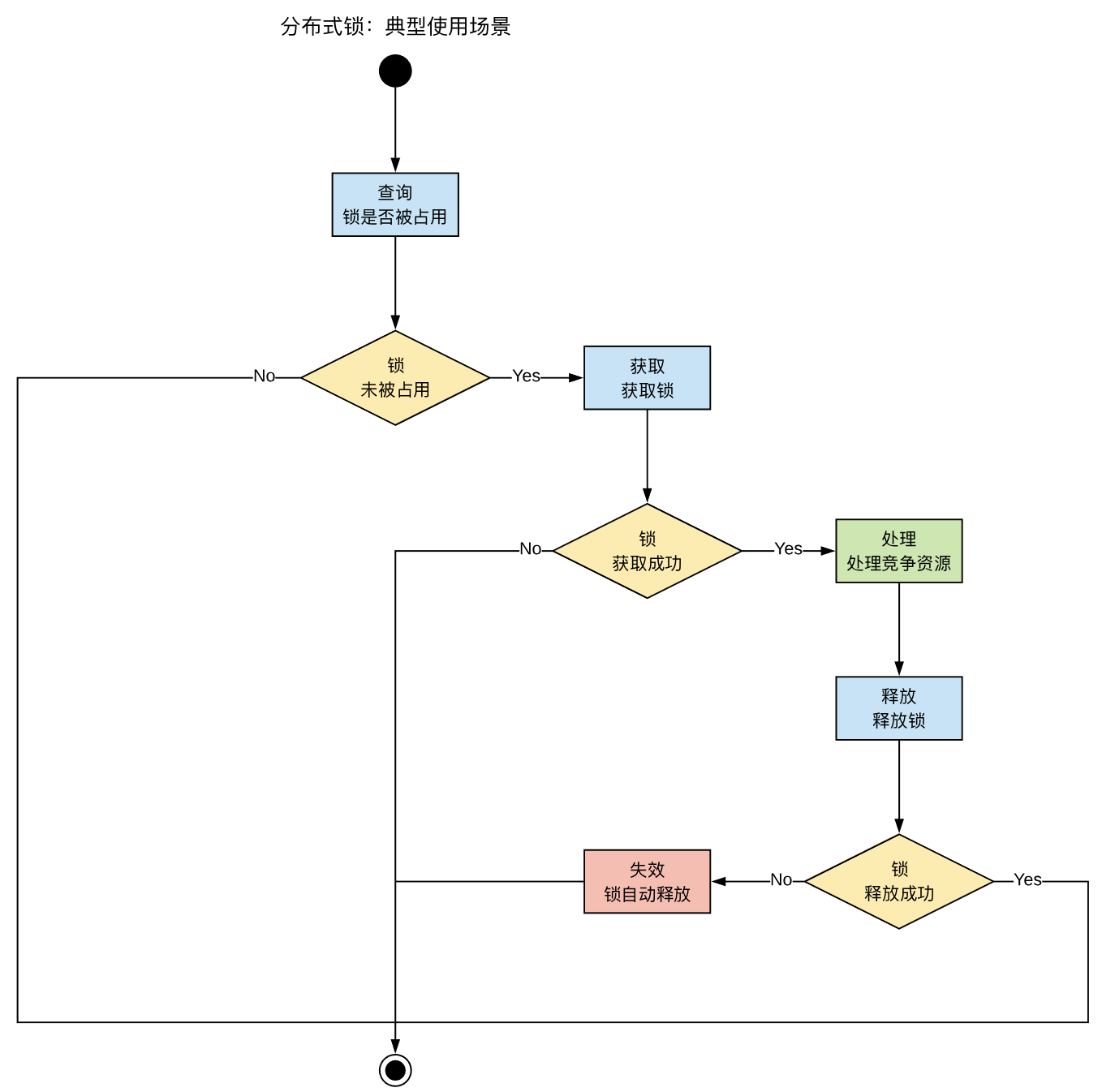
使用:使用分布式锁的典型步骤
- 查询:锁是否已经被占用
- 获取:获取锁
- 处理:处理竞争资源
- 释放:释放锁,允许其他进程再次获取锁
分布式锁,典型使用过程:
分布式锁的要求:
- 高可用:
高可用的获取锁 - 高性能:
高性能的获取锁 - 锁失效机制:避免
死锁 - 可重入:对于同一个身份,获取锁之后,可以再次成功获取锁
- 阻塞锁:和ReentrantLock一样支持
lock和trylock以及tryLock(long timeOut),如果没有获得锁,则,可以等待一段时间 - 公平锁:按照请求
加锁的顺序获得锁,非公平锁就相反是无序的
一个通用问题:
锁自动释放问题(分布式锁的
安全性问题):锁失效机制,避免死锁,同时,会引入「进程阻塞」,锁超时自动释放的问题,进程恢复后,已经失去了锁;
上面「分布式锁的安全性问题」,业界讨论非常多,当前无法完全避免,只能依赖「业务逻辑」上,做最终兜底逻辑,DB 持久化之前,进行好最后的控制。
几种典型原因,都会造成上述分布式锁的安全性问题:
- GC 停顿,分布式锁自动释放
- 时钟跳跃,设置的过期时间非真实时间,分布式锁自动释放
- 网络延迟
更多细节,参考:https://juejin.im/post/5bbb0d8df265da0abd3533a5
1.2.分布式锁,具体实现
分布式锁,几种典型实现:
- 基于数据库:一个表格,增加唯一性索引约束
- 基于 Redis 的实现方式:通过 SETNX 创建 key 获取锁,依赖 EXPIRE 设置锁的自动失效时间
- 基于 Zookeeper 的实现方式
1.2.1.基于数据库,实现分布式锁
基于数据库:一个表格,增加唯一性索引约束
步骤:
- 查询:查询 key 的记录是否存在
- 获取:增加一条 key 的记录,增加成功
- 处理:增加 key 成功后,表示已经获取锁,此时,可以独占处理竞争资源
- 释放:删除 key 的记录,释放锁
优点:
- 简单:依赖数据库即可,实现简单
缺点:
- 性能,依赖数据库的读写性能:较差,数据库中,增加、删除一条记录,一般在 5 ms 以上
- 可用性,依赖数据库的可用性:需要数据库的主备集群
- 锁失效机制:需要增加字段,标明锁失效时间,一旦进程没有释放锁,其他进程根据记录的锁失效时间,可以重新获取锁
- 可重入:需要增加字段,记录当前进程的身份(IP 以及进程、线程标识),同一个身份,可以获取同一把锁
- 其他:实现过程中,会遇到各种问题,为了解决这些问题,实现方式,会越来越复杂;同时,数据库方式的主要缺点在「性能」上,一般 5 ms 以上
1.2.2.基于 Redis 的实现分布式锁
基于 Redis 的实现方式:通过 SETNX 创建 key 获取锁,依赖 EXPIRE 设置锁的自动失效时间
几种实现:查询 GET,获取 SET,释放 DEL,死锁 依赖 key 的过期机制.
2.6.12 版本之前(2012年11 月),需要使用MULTI+EXEC封装 Redis 事务,SETNX key+EXPIRE key设置失效时间2.6.12 版本后,直接使用SET key NX PX timeout即可.
Redis 的主从结构,过期 key 的读取方式:
3.2 版本之前(2015年 8月),依赖 TTL 查询 key 是否存在(结果 > 0 表示存在),因为 Redis 的 master 和 slave 节点,数据读取不一致,过期 key 在 slave 上,仍能读取到3.2 版本之后,完全依赖 GET 即可查询 key 是否存在
几个常见问题:
- 问题 A:
命令的原子性(SET + EXPIRE),在Redis 2.6.2之后版本,使用SET key NX PX timeout一个命令,即可解决 - 问题 B:Redis 的 master-slave 结构(主从结构),主从同步是异步复制,潜在的数据不一致,极端情况下,从 slave 进行的查询 GET 请求会出现数据不一致,建议采用 Redlock 算法(多 master 冗余 + 过半投票策略)
优点:
- 性能:非常高效,锁获取性能在 1ms 以下
- 锁失效机制:key 的自动过期机制,原生支持锁失效,避免死锁
缺点:
- 可用性:集群
主从同步,是异步复制,master 节点写入 key 后失败,slave 升级为 master 后,可能丢失了 key,导致锁丢失;- 解决办法,在 Redis 之外,使用
多 master 冗余+ 外部实现过半投票策略(Redlock 算法)
- 解决办法,在 Redis 之外,使用
1.2.3.基于 ZooKeeper 的实现
基于 Zookeeper 的实现方式:
几种实现:临时节点,跟 client 的连接自动绑定,client 失去连接,会自动
- 临时节点:创建临时节点,
创建成功,表示获取锁 - 临时顺序节点:创建临时顺序节点,查询其
序号是否最小,如果最小,则获取锁;如果不是最小序号,则,可以watch 比前驱节点的删除动作。
几个常见问题:
- 如何实现「读写锁」?创建「
临时顺序节点」,读锁和写锁的前缀不同,会单独整理一篇 blog.
优点:
- 高可用:ZK 采用 ZAB 协议,
2PC过半投票确认,保证 leader 切换过程中,临时节点仍存在 - 高性能:内存中存储,读写性能
1ms以下 - 阻塞锁:依赖临时顺序节点,可以实现阻塞锁
- 公平锁:根据加锁顺序,依次获取锁
缺点:
- 性能:采用 2PC(广播、过半确认、提交),性能不如 Redis(但跟 Redis 的
Redlock差不多)
2.Redis 实现分布式锁
分为 3 个方面进行:
- Redis 分布式锁-传统方案
- Redis 分布式锁-高可用方案(
Redlock算法) - 实践建议
2.1.Redis 分布式锁-传统方案
几个方面:Redis 实现分布式锁,传统方案:
2.6.12版本之前(2012年11 月),需要使用MULTI+EXEC封装 Redis 事务,SETNX key+EXPIRE key设置失效时间2.6.12版本后,直接使用SET key NX PX timeout即可.
针对 Redis 主从结构,Slave 上仍可以读取到「过期 key」的缺陷:
3.2 版本之前(2015年 8月),依赖 TTL 查询 key 是否存在(结果 > 0表示存在),因为 Redis 的 master 和 slave 节点,数据读取不一致,过期 key 在 slave 上,仍能读取到3.2 版本之后,完全依赖 GET 即可查询 key 是否存在
具体资料:
- SET 命令:
SET key NX PX milliseconds- https://redis.io/commands/set
- 从
Redis 2.6.12,开始支持NX PX等选项
SETNX命令:SET if Not eXists,MULTI+SETNX+Expire+EXEC
历史演进:
- Redis 2.6.2 之前,SET 命令 + EXPIRE 命令 (2012 年 11 月之前)
- Redis 2.6 之后,单独的 SET 命令,SET key NX PX milliseconds 获取分布式锁
- Redis 3.2 修正 主从节点之间,过期 key 的读取一致性(2015 年之后)
2.2.Redis 分布式锁-高可用方案(Redlock 算法)
Redlock 算法,本质:
多 master 冗余+过半投票策略
Redlock 算法,典型步骤:
- 获取机器的当前时间:startTime
- client 向
N个master节点,异步发送「加锁请求」,并设置超时时间(应小于锁自动释放时间) - 当 client 获取
N/2 + 1个master节点的「加锁成功」请求后,即,表示「获取锁成功」;否则,向「所有的 master 节点」发送「解锁请求」进行解锁。
中间存在 2 个要点:
- 获取动作的超时时间:多 redis 节点,设置锁时,会耗费时间,需要设置一个超时时间,如果超过此时间,则,需要释放锁
- 失败重试:针对单个 Redis 节点,获取锁失败时,需要
随机延迟后,再重试获取当前 Redis 节点的锁
Think:
多 master 冗余+过半投票策略,获取锁失败时,向「所有的 master 节点」发送「释放锁的请求」,是否会导致「其他进程」加锁成功后,锁也被释放。- Re:这个地方有个细节,「加锁时」在设置的 key 上,设置了只有当前 client 知道的 value 值(版本值),释放锁时,会根据此,进行版本验证后,再释放锁,因此,向「所有的 master 节点」发送「释放锁的请求」,不会有问题。
2.3.实践建议
实践过程中,一般使用 Redis 分布式锁(传统方案),针对 Redis 集群主从之间异步同步引发的主从切换时,分布式锁失效的情况,一般建议:
- 在「资源处理」阶段,增加一个「兜底策略」:依赖
DB 层的CAS 乐观锁机制,进行竞争资源的处理。
3.ZooKeeper 分布式锁
几个方面:
- 写锁
- 读写锁
Curator 是一个 jar 包,封装了 Zookeeper底层的 API,方便对 ZooKeeper 操作,并且其封装了「分布式锁」的功能,这样就无需我们自己实现了。
Curator 中提供的锁:
InterProcessMutex:可重入锁,写锁InterProcessSemaphoreMutex:不可重入锁,写锁InterProcessReadWriteLock:可重入锁中,实现了读写锁,机制基本类似,都是顺序临时节点
3.1.写锁(可重入锁)InterProcessMutex
InterProcessMutex 是 Curator 实现的可重入锁,使用示例:
public class TestOfDistributeLock {
public static void main(String[] args) {
CuratorFramework client = null;
String lockPath = null;
// 创建「可重入锁」(写锁)
InterProcessMutex lock = new InterProcessMutex(client, lockPath);
try {
// a. 获取锁
lock.acquire();
// b. 获取锁成功, 进行业务处理
// ...
} finally {
// c. 释放锁
lock.release();
}
}
}
关于 ZooKeeper 实现的可重入锁 InterProcessMutex :
- 使用 acquire 加锁
- 使用 release 释放锁
获取锁,加锁的具体流程:
- 首先进行可重入的判定: 这里的可重入锁记录在ConcurrentMap<Thread, LockData> threadData这个Map里面,如果threadData.get(currentThread)是有值的那么就证明是可重入锁,然后记录就会加1。我们之前的Mysql其实也可以通过这种方法去优化,可以不需要count字段的值,将这个维护在本地可以提高性能。
- 然后在我们的资源目录下创建一个节点:比如这里创建一个/0000000002这个节点,这个节点需要设置为EPHEMERAL_SEQUENTIAL也就是临时节点并且有序。
- 获取当前目录下所有子节点,判断自己的节点是否位于子节点第一个。
- 如果是第一个,则获取到锁,那么可以返回。
- 如果不是第一个,则证明前面已经有人获取到锁了,那么需要获取自己节点的前一个节点。/0000000002的前一个节点是/0000000001,我们获取到这个节点之后,再上面注册Watcher(这里的watcher其实调用的是object.notifyAll(),用来解除阻塞)。
- object.wait(timeout)或object.wait():进行阻塞等待这里和我们第5步的watcher相对应。
解锁的具体流程:
- 首先进行可重入锁的判定:如果有可重入锁只需要次数减1即可,减1之后加锁次数为0的话继续下面步骤,不为0直接返回。
- 删除当前节点。
- 删除threadDataMap里面的可重入锁的数据。
ZK 的「互斥锁」,本质:
- 获取锁:创建「临时顺序节点」,并查询是否为「
最小序号」- 如果
是,则,获取锁; - 否则,监听(watch)「
邻近的前驱节点」的节点删除动作;
- 如果
- 释放锁:
删除自己创建的「临时顺序节点」
ZooKeeper 另一种实现互斥锁的方式:
- 多进程,竞争创建「临时节点」,创建失败的进程 watch 这个「临时节点」
3.2.读写锁
几个方面:
- 读写锁的含义:需要满足哪些语义
- ZooKeeper 中的读写锁,是如何实现的
读写锁的含义:
- 写锁:互斥,同一时刻,只有一个进程,持有写锁
- 读锁:共享,同一时刻,可以多个进程,持有读锁
- 综合:
- 所有的
写锁都失效时,可以加读锁 - 所有的
读锁都失效时,可以加写锁
- 所有的
围绕「读写锁」单独整理一篇 blog:
4.参考资料
- https://redis.io/topics/distlock
- Redis 发布版本记录
- Redis 各版本新增特性汇总
- https://github.com/antirez/redis/releases
- 分布式锁的讨论
- https://juejin.im/post/5bbb0d8df265da0abd3533a5
- 分布式锁的实现原理
- http://ifeve.com/zookeeper-lock/
- http://ifeve.com/redis-lock/ 详细的官方文档说明
原文地址:https://ningg.top/redis-lesson-13-redis-distributed-locks/