Apache Kafka 0.10 技术内幕:最佳实践
2016-03-17
简介
Kafka 最佳实践:
- 吞吐量 vs. 数据实时性
- 并发效率:数据倾斜
- 数据丢失,典型问题:
- 数据丢失 1:producer 侧
- 数据丢失 2:consumer 侧
提升:吞吐量
吞吐量 vs. 数据实时性,之间做一个权衡:
- producer 侧,可以开启 Nagel 策略:批量发送 msg,提升吞吐量以及有效 payload
- producer 配置
批量发送的参数:触发任何一个条件,都会发送 msg 到 Kafkalinger.ms超时时间batch.size单个 Partition msg 批量大小(单位字节)
具体 Producer API 的属性配置:

数据倾斜
简介
- 数据倾斜:数据分区时,没有均分到各个区中。
- 正视数据倾斜的存在:80%的用户只使用20%的功能 , 20%的用户贡献了80%的访问量,数据也类似,因此,涉及数据分区时,应主动考虑
数据倾斜现象。
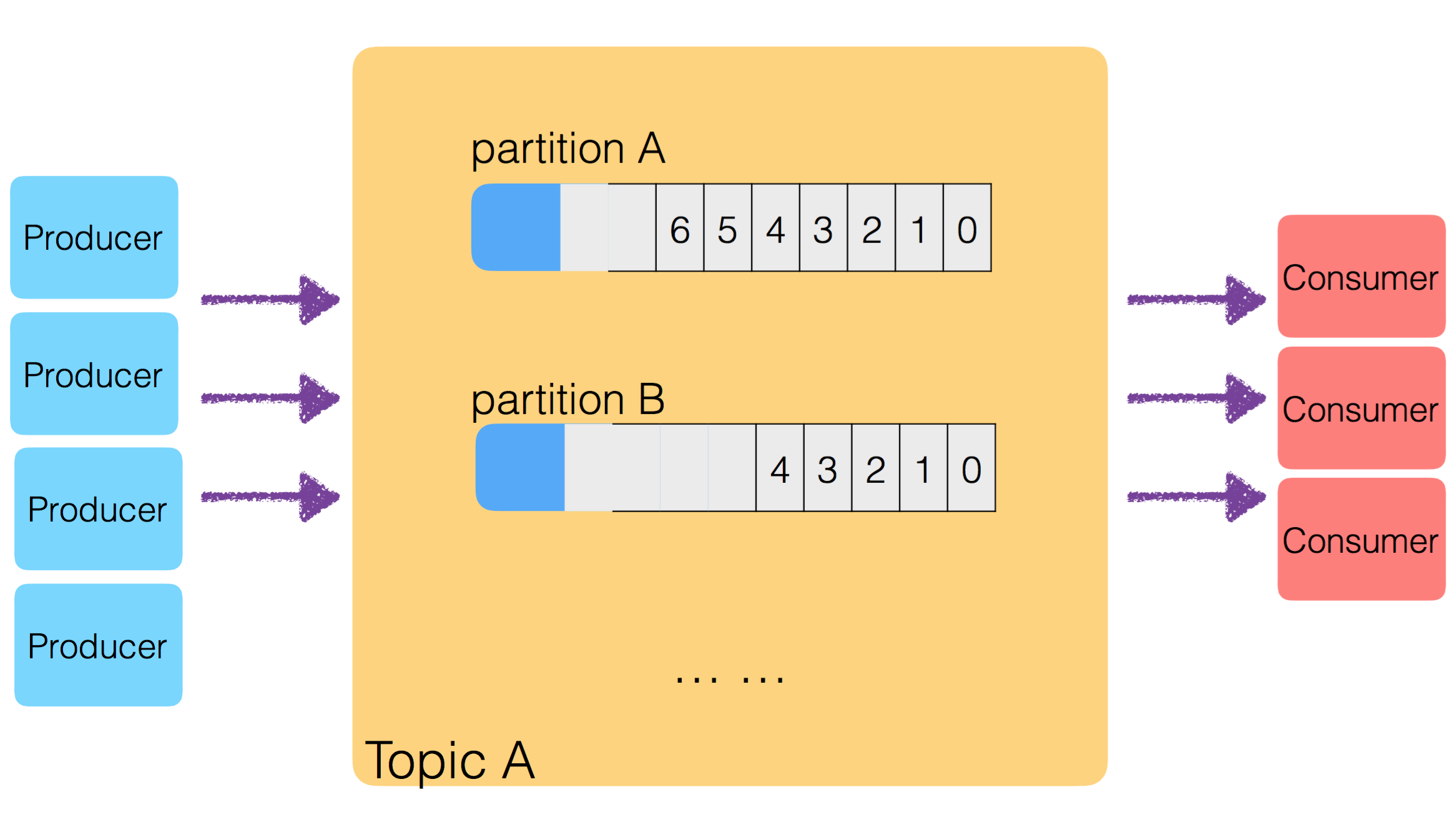
要解决数据倾斜的问题,主要从 Producer 入手,弄清楚 Producer 生成的 Msg,是如何选择传输到哪个 Partition 的。只要让 Producer 把生成的 Msg 均匀的分发到各个 Partition 中,就解决了数据倾斜问题。
Producer 产生的数据,送入哪个 Partition
自定义路由策略:
- partitioner.class:
- 指定 Class 继承 Partitioner 接口,利用 key 计算出
partition index - 默认值:
- Kafka
0.8.1-:kafka.producer.DefaultPartitioner - Kafka
0.8.2+:org.apache.kafka.clients.producer.internals.DefaultPartitioner,即,Utils.abs(key.hashCode) % numPartitions
- Kafka
- 指定 Class 继承 Partitioner 接口,利用 key 计算出
发送 msg 时,需要同时设定:key、msg:
- key 用于计算发送到哪个 partition
- key 不为 null 时,大多数处理方式都以下述方式计算
partition index=key.hashCode % numPartitions - key 为 null 时,随机选择 partition index,NOTE:此处有坑
key 为 null 时,msg 发送到哪个 Partition
简单回答一下「key 为 null 时,msg 发送到哪个 Partition」答案是:跟使用的 Producer API 有关:
new Java Producer API:轮循,round-robin,每次换一个 partitionlegacy Scala Producer API:随机一个 partition index,并且缓存起来,每 10 mins 清除一次缓存 ,随机下一个 partition index,并再次缓存
特别说明:
new Java Producer API,从 Kafka 0.8.2.x 开始引入,但后续版本中,仍然保留 legacy Scala Producer API
最佳实践建议
为了最大程度减弱数据倾斜现象,最佳策略:
- Producer 发送 msg 时,设置 key
- 对 key 没有特殊要求时,建议设置 key 为随机数
Partition 与 Consumer 之间如何对应起来?
几个简单说明:
consumer thread nums>partition nums时,一部分 consumer thread 永远不会消费到 msgconsumer thread nums<partition nums时,将 partition 均分为 consumer thread nums 份,每个 consumer thread 得到一份
思考:consumer thread 正在处理某个 partition 时,如何转去处理 另一个 partition(补充详细操作)
Note:consumer、broker 的变化,会触发 reblance,重新绑定 partition 与 consumer 之间的消费关系。
数据重复消费
Consumer 重复消费 msg,一般 2 种原因:
- producer 向 Kafka 集群重复发送数据
- consumer 从 Kafka 读取数据,并且 offset 由 consumer 控制:
- consumer 消费完 msg 之后,未将 offset 更新至 zookeeper,然后 consumer 宕机
- 重启之后,consumer 会重复消费 msg
- Note:向 zookeeper 提交 offset 的时间间隔:
auto.commit.interval.ms,默认,60 000 ms (1 mins)
补充几点知识:
Producer 设置同步发送、异步发送:
- 参数:
producer.type- Kafka 0.8.2 及以下版本:默认 sync,Producer 同步发送 msg
- Kafka 0.9.0+ 版本:不再使用 producer.type 参数,换作其他参数,并且默认 异步发送
producer.type设置为async时,Producer 异步发送 msg,即,在本地合并小的 msg,Nagel 策略,批量发送,提升系统的整体有效吞吐量
Producer 触发 Broker 同步复制、异步复制:
- 参数:
acks,默认1,即,要求 broker leader 进行 ack; - 其余取值:
0,不要求任何 broker 进行 ack1,要求 leader 返回 ack;-1或者all,要求所有的 follower 完成复制之后,再返回 ack;
consumer 对应 offset 存储的问题
offset 存储问题:
High Level Consumer API,offset 存储在 ZookeeperSimple Consumer API, offset 完全由 consumer 自处理
Kafka 0.8.2+ 开始,offset 管理策略有改进:
Consumer 处理能力感知
Consumer 的处理能力感知:
- Kafka:一个 partition 只能被一个 consumer 处理
- 某个 consumer 处理能力很强时,如何设置 consumer 切换处理其他 partition?
需要弄清楚:
- Kafka 的 Consumer API 中解决了上述问题了么?
- 解决上述问题,基本思路是什么?
结论:
Kafka 作为新一代数据平台核心组件,
不会感知计算能力,而是以「数据」为第一公民,Consumer 处理能力很强时,不会类似Fork-Join机制一样去处理其他 Partition,而是类似Map-Reduce机制,Consumer 处理完之后,就会空转。
先看一个问题:
- consumer 消费 partition 中数据,当没有新数据时,consumer 会断开连接吗?
- partition 中有新的数据产生时,consumer 会定期查询、并获取最新数据吗?
- 细节上,consumer 与 partition 中之间详细交互过程?
结论:
无论partition是否有数据,consumer都会不断向broker轮询。所以不会断开连接,且会获取到最新的数据。
producer、broker、zookeeper、consumer 之间的基本关系
几个基本说法:
- 启动 Producer 时,需配置 broker 地址:producer 通过配置的 broker 发现其他 broker
- 启动 Consumer 时,需要配置 Zookeeper:consumer 将 offset 提交到 Zookeeper 存储、通过 zookeeper 发现 broker (针对 High Level Consumer API)
- 启动 Consumer 时,可以不配置 Zookeeper,改为配置 broker (针对 Simple Consumer API)
参考资料
- Kafka 官网
- https://cwiki.apache.org/confluence/display/KAFKA/0.8.0+Producer+Example Kafka 0.8.1版本以下,Producer API 的示例
- https://cwiki.apache.org/confluence/display/KAFKA/Consumer+Group+Example High Level Consumer API 示例 (offset 未及时提交到 zookeeper 导致数据重复消费)
- https://cwiki.apache.org/confluence/display/KAFKA/0.8.0+SimpleConsumer+Example Simple Consumer API
- http://kafka.apache.org/082/documentation.html Kafka 0.8.2 版本文档
- https://cwiki.apache.org/confluence/display/KAFKA/FAQ
- http://stackoverflow.com/q/25896109
- http://stackoverflow.com/a/30650787
- http://www.confluent.io/blog/whats-coming-in-apache-kafka-0-8-2/
- Kafka 0.9.0 源码
原文地址:https://ningg.top/apache-kafka-10-best-practice-tips/