基础原理系列:缓存通用原理和实践
2014-08-15
1. 概念解释
1.1. 缓存数据级别
根据粒度不同,从大到小,基本可分为:
- 页面缓存:渲染后的页面
- 数据缓存:页面数据
- 实体缓存:页面数据之下对应的实体
1.2. 几个时间
使用缓存,目标是提高数据访问性能,其中涉及几个时间:
- 本地缓存读取时间
- 数据库读取时间
- 网络调用耗时
- 分布式缓存读取时间
1.3. CAP理论
分布式领域 CAP 理论:
- Consistency,一致性:数据一致更新,所有数据变动都是同步的
- Availability,可用性:读和写操作都能成功
- Partition tolerance,可靠性:分区容错,出现网络故障导致分布式节点间不能通信时,系统仍能提供服务
定理:任何分布式系统,只可能同时满足两点,无法三者兼顾。架构师应该在CAP上做好取舍。
一个DB服务 搭建在两个机房(北京,广州),两个DB实例同时提供写入和读取,不同方案下,出现网络故障时,均无法同时保证CAP:
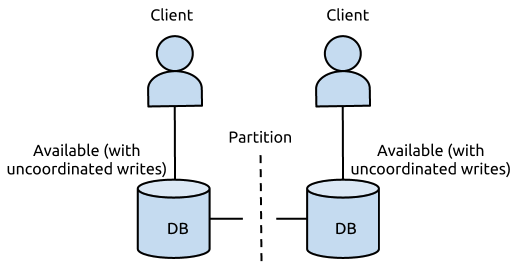
- 假设DB的更新操作是同时写北京和广州的DB都成功才返回成功
在没有出现网络故障的时候,满足CA原则,C 即我的任何一个写入,更新操作成功并返回客户端完成后,分布式的所有节点在同一时间的数据完全一致, A 即我的读写操作都能够成功,但是当出现网络故障时,我不能同时保证CA,即P条件无法满足
- 假设DB的更新操作是只写本地机房成功就返回,通过binlog/oplog回放方式同步至侧边机房
这种操作保证了在出现网络故障时,双边机房都是可以提供服务的,且读写操作都能成功,意味着他满足了AP ,但是它不满足C,因为更新操作返回成功后,双边机房的DB看到的数据会存在短暂不一致,且在网络故障时,不一致的时间差会很大(仅能保证最终一致性)
- 假设DB的更新操作是同时写北京和广州的DB都成功才返回成功且网络故障时提供降级服务
降级服务,如停止写入,只提供读取功能,这样能保证数据是一致的,且网络故障时能提供服务,满足CP原则,但是他无法满足可用性原则
1.4. ACID
关系数据库的ACID模型拥有 高一致性 + 可用性,但很难进行分区:
- Atomicity 原子性:一个事务中所有操作要么全部成功,要么全部失败
- Consistency 一致性: 在事务开始或结束时,数据库应该在一致状态,业务上的约束
- Isolation 隔离性:多个事务执行时,互不干扰
- Durability 持久化:一旦事务提交,即使断电,事务仍然有效
1.5. BASE
BASE模型,不同ACID模型,牺牲高一致性,获得可用性、可靠性:
- Basically Available,基本可用:支持分区失败(e.g. sharding碎片划分数据库)
- Soft state,软状态:状态可以有一段时间不同步,异步。
- Eventually consistent,最终一致:最终数据是一致的就可以了,而不是实时高一致。
BASE思想的主要实现有
- 按功能划分数据库
- sharding碎片
1.6. 穿透、雪崩、并发
简要解释:
- 穿透:
- 原因:null 对象(DB无数据),未被缓存
- 结果:从 DB 反复查询不存在的记录,造成 DB 损耗,锁/事务/树索引
- 解决方法:缓存一个 EMPTY 对象
- 雪崩:
- 原因:缓存内,大量记录集中失效
- 结果:短时间内 DB 负载极高
- 解决方法:交错失效,随机缓存时间
- 并发:
- 原因:读缓存(未命中) – 读 DB – 写缓存,不是原子操作
- 结果:当单个key失效时,如果有海量请求,则会有大量请求同时进入 DB
- 解决方法:DCL/Future/Mutex/异步刷新
- 特别说明:不要滥用防并发策略,因为有代价,具体场景,具体分析
- 场景一:并发导致若干次 DB 主键查询,没必要防并发
- 场景二:并发导致ES扫描上亿条数据,精心设计防并发
1.7. 缓存指标
缓存命中率:从缓存成功读取数据的次数/从缓存读取数据的次数。
1.8. 缓存策略
1.8.1. Eviction policy
移除策略,即如果缓存满了,从缓存中移除数据的策略;常见的有LFU、LRU、FIFO:
- FIFO(First In First Out):先进先出算法,即先放入缓存的先被移除;
- LRU(Least Recently Used):最近最少使用算法,使用时间距离现在最久的那个被移除;
- LFU(Least Frequently Used):最少使用算法,一定时间段内使用次数(频率)最少的那个被移除;
1.8.2. TTL(Time To Live )
存活期,即从缓存中创建时间点开始直到它到期的一个时间段(不管在这个时间段内有没有访问都将过期)
1.8.3. TTI(Time To Idle)
空闲期,即一个数据多久没被访问将从缓存中移除的时间。
2. 实践建议
使用缓存的基本步骤:
- 什么时候设置缓存?查(特别说明:新增时,不会设置缓存)
- 什么时候失效缓存?增、删、改
- 缓存的粒度:
- id
- Entity
- 集合
- id 集合
- Entity 集合
缓存中几个基本问题:
- 缓存集合?
- 场景:读取 List
的请求频率很高,是否要缓存整个 Entity 集合? - 建议:缓存 id 集合 + 逐个 id 读取 Entity
- 收益:
- 增加缓存有效时间
- 避免频繁设置和失效缓存(相对于缓存)
- 代价:
- 一次 DB 交互,变为潜在的多次 DB 交互 (实际上,比想象的情况要好)
- 场景:读取 List
- 缓存击穿?
- 场景:查询对象为 null,是否添加到缓存?
- 建议:null 对象增加到缓存中,避免缓存击穿
- 收益:
- 避免缓存击穿
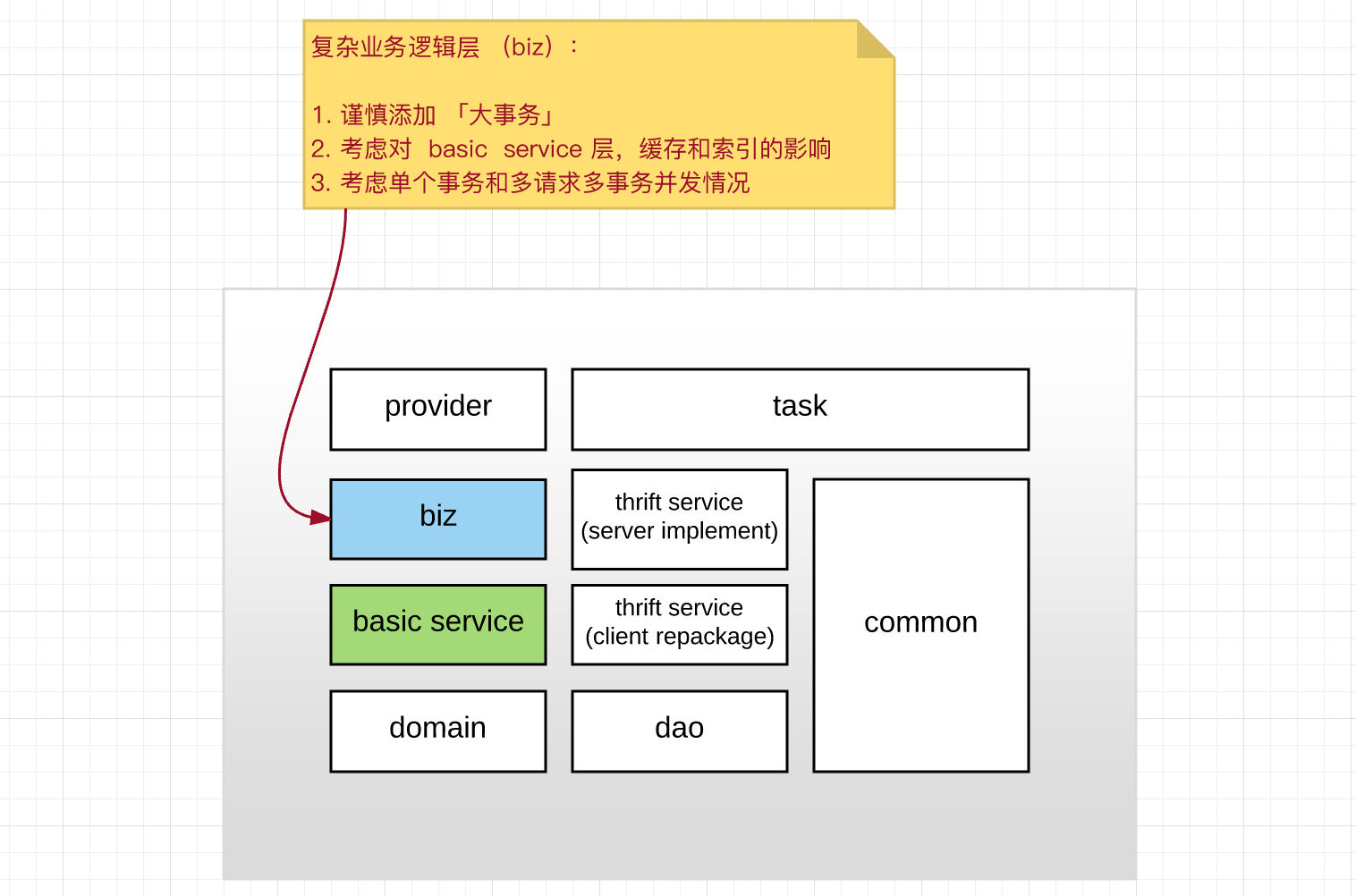
3. Spring 中缓存实践:缓存、事务、数据库
关于 Spring AOP 中,「缓存」、「索引」、「事务」的织入顺序,踩过几个坑:
(前方高能预警:下面是最佳实践)
整体来说,为保证「事务」、「缓存」、「索引」操作时,不会出现缓存污染问题,可以采取下述措施:
- biz 层(复杂业务逻辑层)谨慎添加「事务」:
- 尽可能在业务逻辑上进行补偿,减少大事务的使用,减少事务共用;
- 业务层补充错误:业务幂等性 + 业务异常报警
- AOP 织入优先级:异步索引 > 缓存 > 事务(在 after 部分步骤刚好相反),说明如下:
- 缓存 > 事务:数据优先写入 DB > Cache > Search;如果先清理缓存,再 commit 到 DB,则这个时间间隔内,高并发情况下,会产生缓存污染;
- 备注:事务提交成功后,可能缓存清理失败,此时出现缓存污染,需要完善报警和补偿机制。
- 异步索引>事务:只在事务提交成功后,再进行异步索引操作,避免因为事务隔离,异步索引读取到「旧数据」污染缓存;
- 异步索引失败:增加 replay 重放机制 + 索引失败报警机制
- 缓存 > 事务:数据优先写入 DB > Cache > Search;如果先清理缓存,再 commit 到 DB,则这个时间间隔内,高并发情况下,会产生缓存污染;
具体,最佳实践建议如下:
![]()
整体建议:
4. 参考来源
原文地址:https://ningg.top/computer-basic-theory-cache-intro-and-best-practice/