Flume 1.5.0.1:如何将flume聚合的数据送入Kafka
2014-10-24
背景
Flume收集分布在不同机器上的日志信息,聚合之后,将信息送入Kafka消息队列,问题来了:如何将Flume输出的信息送入Kafka中?
定一个场景:flume读取apache的访问日志,然后送入Kafka中,最终消息从Kafka中取出,显示在终端屏幕上(stdout)。
Flume复习
整理一下Flume的基本知识,参考来源有两个:
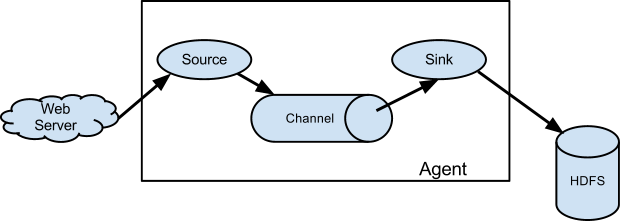
几个概念
- Flume event: a unit of data flow, having a byte payload and an optional set of string attributes.(event中包含了,payload和attributes)
- Flume agent: a (JVM) process, that hosts the components through which events flow from an external source to the next destination(hop).(agent对应JVM process)
- Channel: passive store, keeps the event until it’s consumded by a Flume Sink.(Channel不会主动消费event,其等待Sink来取数据,会在本地备份Event)
- Sink: remove the event from the channel and put it into external repository.(Sink主动从Channel中取出event)
练习
场景:Flume收集apache访问日志,然后,在标准终端(stdout)显示。
分析:Flume官方文档中,已经给出了一个demo,flume从localhost:port收集数据,并在标准终端上显示。基于这一场景,只需要修改Source即可。
构造实例
通过参阅Flume官网,得知ExecSource可用于捕获命令的输出,并将输出结果按行构造event,tail -F [local file]命令用于查阅文件[local file]的新增内容;在$FLUME_HOME/conf目录下,新建文件apache_log_scan.log,内容如下:
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /var/log/httpd/access_log
a1.sinks.k1.type = logger
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动Flume agent,命令如下:
[ningg@localhost flume]$ cd conf
[ningg@localhost conf]$ sudo ../bin/flume-ng agent --conf ../conf --conf-file example.conf --name a1 -Dflume.root.logger=INFO,console
...
...
Component type: SOURCE, name: r1 started
然后访问一下Apache承载的网站,可以看到上面的窗口也在输出信息,即,已经在捕获Apache访问日志access_log的增量了。(可以另起一个窗口,通过tail -F access_log查看日志的实际内容)
存在的问题
通过比较Flume上sink的输出、tail -F access_log命令的输出,发现输出有差异:
# Flume上logger类型sink的输出
Event: { headers:{} body: 31 36 38 2E 35 2E 31 33 30 2E 31 37 35 20 2D 20 168.5.130.175 - }
# access_log原始文件上的新增内容(长度超过上面logger sink的输出)
168.5.130.175 - - [23/Oct/2014:16:34:59 +0800] "GET /..."
思考:
- logger类型的sink,遇到
[字符就结束? - logger类型的sink,有字符长度的限制吗?
- channel有长度限制?channel中存储的event是什么形式存储的?
通过vim access_log,向文件最后添加一行内容,发现应该是logger类型的sink,对于event的长度有限制;或者,memory类型的channel对于存储的event有限制。
RE:上述问题已经解决,Logger sink输出内容不完整,详情可参考Advanced Logger Sink。
Kafka复习
下面Kafka的相关总结都参考自:
几个概念
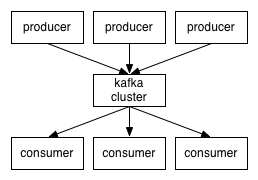
- 消息队列:Kafka充当消息队列,producer将message放入Kafka集群,consumer从Kafka集群中读取message;
- 内部结构:按照topic来存放message,每个topic对应一个partitioned log,其中包含多个partition,每个都是一个有序的、message队列;
- 消息存活时间:在设定的时间内,kafka始终保存所有的message,即使message已经被consume;
- consume message:每个consumer,只需保存在log中的offset,并且这个offset完全由consumer控制,可自由调整;鉴于此,cousumer之间相互基本没有影响;
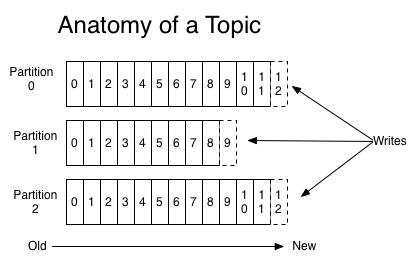
针对上面每个topic对应的partitioned log,其中包含了多个partition,这样设计有什么好处?
- single server上,单个log的大小由文件系统限制,而采用多partition模式,虽然单个partition也受限,但partition的个数不受限制;
- 多个partition时,每个partition都可作为一个unit,以此来支撑并发处理;
- partition是分布式存储的,即,某个server上的partition可能也存在其他的server上,两点好处:
- 方便不同server之间的partition共享;
- 配置每个partition的复制份数,提升系统可靠性;
- partition对应的server,分为两个角色:
leader和follower:- 每个partition都对应一个server担当
leader角色:负责所有的read、write; - 其他server担
follower角色:重复leader的操作; - 如果
leader崩溃,则自动推选一个follower升级为leader; - server只对其上的部分partition担当
leader角色,方便cluster的均衡;
- 每个partition都对应一个server担当
Producer产生的数据放到topic的哪个partition下?集中方式:
- 轮询:保证每个partition以均等的机会存储message,均衡负载;
- 函数:根据key in the message来确定partition;
Consumer读取message有两种模式:
- queueing:多个consumer构成一个pool,然后,每个message只被其中一个consumer处理;
- publish-subscribe:向所有的consumer广播message;
Kafka中通过将consumer泛化为consumer group来实现,来支持上述两种模式,关于此,详细说一下:
- consumer都标记有consumer group name,每个message都发送给对应consumer group中的一个consumer instance,consumer instance可以是不同的进程,也可以分布在不同的物理机器上;
- 若所有的consumer instances都属于同一个consume group,则为queuing轮询的均衡负载;
- 若所有的consumer instances都属于不同的consume group,则为publish-subscribe,message广播到所有的consumer;
- 实际场景下,topic对应为数不多的几个consumer group,即,consumer group类似
logical subscriber;每个group中有多个consumer,目的是提升可扩展性和容错能力。
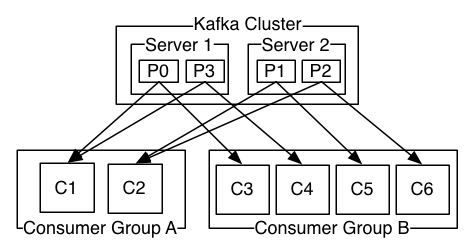
notes(ningg):几个问题:
- consumer group是与topic对应的?还是partition对应?
- consumer group方式能够提升可扩展性和容错能力?
Ordering guarantee,Kafka保证message按序处理,同时也保证并行处理,几点:
- 单个partition中的message保证按序处理,同时一个partition只能对应一个consumer instance;
- 不同partition之间,不保证顺序处理,多个partition实现了并行处理;
notes(ningg):同一个partition中的message,当其中一个message A被指派给一个consumer instance后,在message A被处理完之前,message B是否会被指派出去?RE:细节还没看,具当前的理解,应该是串行处理的,即,一个处理完后,才会发送另一个。
小结
Kafka通过 partition data by key 和 pre-partition ordering,满足了大部分需求。如果要保证所有message都顺序处理,则将topic设置为only one partition,此时,变为串行处理。
notes(ningg):单个partition是以什么形式存储在server上的?纯粹的文档文件?Flume的fan-in、fan-out什么含义?fan-in针对的是agent之间,fan-out针对agent内部source–channel之间?
Flume的Kafka sink
Flume中数据送入Kafka,本质上就是一个Kafka sink。很多人都有这个需求,甚至有的还需要将Flume来读取Kafka中的数据(Kafka source)。本次使用的Flume和Kafka的详细版本信息如下:
- Flume:apache-flume-1.5.0.1-bin.tar.gz
- Kafka:kafka_2.9.2-0.8.1.1.tgz
前人的工作
Flume中Kafka source和Kafka sink都有人在做,整体来说有几个进展:
- 唯品会的工程师Frank Yao,提供了一个针对Kafka 0.7.2的实现版本;
- Github上用户thilinamb提供了一个Kafka 0.8.1.1的实现版本
- Flume官网提到,将在Flume 1.6版本中提供对Kafka的支持;
现在,怎么做?打算学习thilinamb的版本,并且用起来,必要时,形成自己的版本。
notes(ningg):Flume官网虽然还没有发布 1.6 版本,但作为开源软件,能够提前查看针对Kafka source和sink部分的代码吗?JIRA上能不能看?
具体实现
直接参考thilinamb的Kafka 0.8.1.1的实现版本中的README。 说明:thilinamb的工程是用Maven进行管理的,可以作为Existing Maven Project直接导入,然后mvn clean instal即可。

notes(ningg):thilinamb的工程,使用maven进行管理,结构好像挺合理的,有一个parent的project,需要认真学习一下。
Flume Kafka sink原理
在上一部分,虽然实现了Flume中数据送入Kafka,但具体原理是什么?需要深入学习一下。
(TODO)
参考来源
原文地址:https://ningg.top/flume-with-kafka/