Kafka 0.8.1 Documentation:Getting Started
2014-10-18
1. Getting Started
1.1 Introduction
Kafka is a distributed, partitioned, replicated commit log service. It provides the functionality of a messaging system, but with a unique design. What does all that mean?
notes(ningg):distributed, partitioned, replicated commit log service?
First let’s review some basic messaging terminology:(几个messaging概念)
- Kafka maintains feeds of messages in categories called topics.(按topic来分类message?)
- We’ll call processes that publish messages to a Kafka topic producers.(调用process,向topic producer中写message)
- We’ll call processes that subscribe to topics and process the feed of published messages consumers..
- Kafka is run as a cluster comprised of one or more servers each of which is called a broker.(kafka集群由borker构成)
So, at a high level, producers send messages over the network to the Kafka cluster which in turn serves them up to consumers like this:(producer向kafka集群写入message,consumer从kafka集群中读取message)
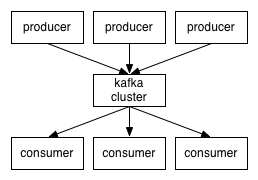
Communication between the clients and the servers is done with a simple, high-performance, language agnostic TCP protocol. We provide a Java client for Kafka, but clients are available in many languages.(client与server之间通过TCP协议通信,默认为kafka提供了java client,当然也可以用其他语言实现client)
Topics and Logs
A topic is a category or feed name to which messages are published. For each topic, the Kafka cluster maintains a partitioned log that looks like this:(topic,就是category、feed name,message按此分开存放;每个topic,对应一个partitioned log)
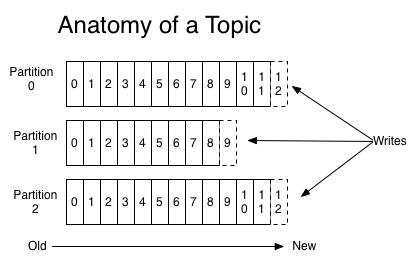
Each partition is an ordered, immutable sequence of messages that is continually appended to—a commit log. The messages in the partitions are each assigned a sequential id number called the offset that uniquely identifies each message within the partition.(partition是ordered、immutable sequence of message,其中的message被唯一标识,partition对应 a commit log)
The Kafka cluster retains all published messages—whether or not they have been consumed—for a configurable period of time. For example if the log retention is set to two days, then for the two days after a message is published it is available for consumption, after which it will be discarded to free up space. Kafka’s performance is effectively constant with respect to data size so retaining lots of data is not a problem.(在一段可配置的时间内,kafka始终保存所有的published messages,即使message已经被consume;Kafka对data size不敏感,lots of data对performance造成太大影响)
In fact the only metadata retained on a per-consumer basis is the position of the consumer in the log, called the “offset”. This offset is controlled by the consumer: normally a consumer will advance its offset linearly as it reads messages, but in fact the position is controlled by the consumer and it can consume messages in any order it likes. For example a consumer can reset to an older offset to reprocess. (on a per-consumer basis,只需保存元数据:consumer在log中的position,即,offset;这个offset完全由consumer自己决定,offset默认是顺序递增,但实际上consumer可以任意调整。)
This combination of features means that Kafka consumers are very cheap—they can come and go without much impact on the cluster or on other consumers. For example, you can use our command line tools to “tail” the contents of any topic without changing what is consumed by any existing consumers.(总之,consumer在kafka中非常cheap:随意的come and go,对系统影响很小,consumer相互之间的影响也很小)
The partitions in the log serve several purposes. First, they allow the log to scale beyond a size that will fit on a single server. Each individual partition must fit on the servers that host it, but a topic may have many partitions so it can handle an arbitrary amount of data. Second they act as the unit of parallelism—more on that in a bit.(对log分partition,有几点目的:1.single server支撑较大的log,单个partition受到server的限制,但partition的数量不受限;2.多partition可以支撑并发处理,每个partition作为一个unit。)
Distribution
The partitions of the log are distributed over the servers in the Kafka cluster with each server handling data and requests for a share of the partitions. Each partition is replicated across a configurable number of servers for fault tolerance. (partition分布式存储,方便共享;同时可配置每个patition的复制份数,以提升系统可靠性)
Each partition has one server which acts as the “leader” and zero or more servers which act as “followers”. The leader handles all read and write requests for the partition while the followers passively replicate the leader. If the leader fails, one of the followers will automatically become the new leader. Each server acts as a leader for some of its partitions and a follower for others so load is well balanced within the cluster. (每个partition都对应一个server担当”leader”角色,也可能有其他server担当”follower”角色;leader负责所有的Read、write;follower只replicate the leader;如果leader崩溃,则自动推选一个follower升级为leader;server只对其上的部分partition充当leader角色,方便cluster的均衡。)
Producers
Producers publish data to the topics of their choice. The producer is responsible for choosing which message to assign to which partition within the topic. This can be done in a round-robin fashion simply to balance load or it can be done according to some semantic partition function (say based on some key in the message). More on the use of partitioning in a second. (producer负责将message分发到相应的topic,具体将message分发到哪个topic的哪个partition,常用方式,轮询、函数;)
Consumers
Messaging traditionally has two models: queuing and publish-subscribe. In a queue, a pool of consumers may read from a server and each message goes to one of them; in publish-subscribe the message is broadcast to all consumers. Kafka offers a single consumer abstraction that generalizes both of these—the consumer group. (messaging,消息发送,有两种方式:queuing、publish-subscribe。Queuing,message发送到某一个consumer;publish-subscribe,message广播到所有的consumers。Kafka,通过将consumer泛化为consumer group,来支持这两种方式)
notes(ningg):publish-subscribe,发布-订阅模式的含义?
Consumers label themselves with a consumer group name, and each message published to a topic is delivered to one consumer instance within each subscribing consumer group. Consumer instances can be in separate processes or on separate machines. (每个consumer都标记有consumer group name,每个message都被分发给subscribing consumer group中的一个consumer instance,consumer instances可以是不同的进程,也可以分布在不同的物理机器上。)
If all the consumer instances have the same consumer group, then this works just like a traditional queue balancing load over the consumers.(若所有的consumer都属于同一个consumer group,则,情况变为:queue的负载均衡?)
If all the consumer instances have different consumer groups, then this works like publish-subscribe and all messages are broadcast to all consumers. (若所有的consumer都属不同的consumer group,则,情况变为:publish-subscribe,message广播发送到所有consumer)
More commonly, however, we have found that topics have a small number of consumer groups, one for each “logical subscriber”. Each group is composed of many consumer instances for scalability and fault tolerance. This is nothing more than publish-subscribe semantics where the subscriber is cluster of consumers instead of a single process.
(topics只对应少数的consumer group,即,consumer group类似logical subscriber;每个group中有多个consumer,目的是提升可扩展性、容错能力)
notes(ningg):consumer group下有多个consumer?这些consumer怎么调用的?相互之间有什么差异?
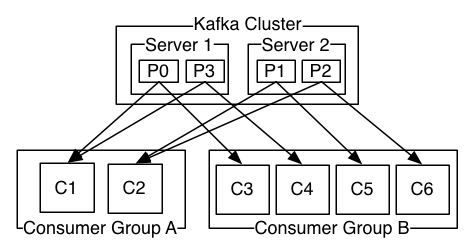
A two server Kafka cluster hosting four partitions (P0-P3) with two consumer groups. Consumer group A has two consumer instances and group B has four.
Kafka has stronger ordering guarantees than a traditional messaging system, too.(kafka有strong ordering guarantees)
A traditional queue retains messages in-order on the server, and if multiple consumers consume from the queue then the server hands out messages in the order they are stored. However, although the server hands out messages in order, the messages are delivered asynchronously to consumers, so they may arrive out of order on different consumers. This effectively means the ordering of the messages is lost in the presence of parallel consumption. Messaging systems often work around this by having a notion of “exclusive consumer” that allows only one process to consume from a queue, but of course this means that there is no parallelism in processing.
(message queue中存放的message,按照顺序发送到不同的consumers,但是这些发送是异步的,因此,后发送的message可能先到达consumer,即,并行处理时,有可能message乱序。现有的Messaging system,常用exclusive consumer,独占消费,仅仅启动一个process来读取一个queue中的数据,此时,就无法实现并行处理。)
Kafka does it better. By having a notion of parallelism—the partition—within the topics, Kafka is able to provide both ordering guarantees and load balancing over a pool of consumer processes. This is achieved by assigning the partitions in the topic to the consumers in the consumer group so that each partition is consumed by exactly one consumer in the group. By doing this we ensure that the consumer is the only reader of that partition and consumes the data in order. Since there are many partitions this still balances the load over many consumer instances. Note however that there cannot be more consumer instances than partitions.
(Kafka,采用partition的方式解决上述问题:每个partition被指定给topic对应的consumer group中的特定的consumer,这样能保证一点:一个partition中的message被顺序处理。由于有多个partition,并且对应多个consumer instance来处理,从而实现负载均衡;特别注意:consumer instance个数不能多于partitions个数)
notes(ningg):message是怎么分配到topic对应的partition中的?(这是有Producer决定的,常用方式:轮询、函数)consumer instance为什么不能多于partition个数?
Kafka only provides a total order over messages within a partition, not between different partitions in a topic. Per-partition ordering combined with the ability to partition data by key is sufficient for most applications. However, if you require a total order over messages this can be achieved with a topic that has only one partition, though this will mean only one consumer process. (Kafka只保证partition内mesaage的顺序处理,不保证partition之间的处理顺序。per-partition ordering和partition data by key,满足了大部分需求。如果要保证所有message顺序处理,则,将topic设置为only one partition,此时,变为串行处理。)
notes(ningg):producer、consumer属于kafka吗?(Kafka主要负责按Topic进行message的存储,同时提供Producer\Consumer API,本质上Kafka不包含producer和consumer;)外部的message怎么进来的?怎么出去的?flume+kafka+storm模式到底什么情况?(外部应用通过调用Kafka的Producer API向Kafka中存入message;同时,外部应用也可以通过调用Kafka的Consumer API来读取Kafka中的message;flume+kafka+storm,就是flume中添加了一个实现Kafka Producer API的kafka sink,storm中添加了一个实现了Kafka Consumer API的kafka spout)
Guarantees
At a high-level Kafka gives the following guarantees:
- Messages sent by a producer to a particular topic partition will be appended in the order they are sent. That is, if a message M1 is sent by the same producer as a message M2, and M1 is sent first, then M1 will have a lower offset than M2 and appear earlier in the log.(同一个producer发送到a particular topic partition的message,保证在partition中是有序的)
- A consumer instance sees messages in the order they are stored in the log.(partition对应的commit log中message是有序的)
- For a topic with replication factor N, we will tolerate up to N-1 server failures without losing any messages committed to the log.(复制N份的topic,保证N-1份都丢失的情况下能够恢复。)
More details on these guarantees are given in the design section of the documentation.
1.2 Use Cases
Here is a description of a few of the popular use cases for Apache Kafka. For an overview of a number of these areas in action, see this blog post. (使用Kafka的典型场景,详细应用参考this blog post)
Messaging
Kafka works well as a replacement for a more traditional message broker. Message brokers are used for a variety of reasons (to decouple processing from data producers, to buffer unprocessed messages, etc). In comparison to most messaging systems Kafka has better throughput, built-in partitioning, replication, and fault-tolerance which makes it a good solution for large scale message processing applications. (替换传统的message broker/消息代理,其基本用途:解耦processing和data producer,缓存message,etc。)
In our experience messaging uses are often comparatively low-throughput, but may require low end-to-end latency and often depend on the strong durability guarantees Kafka provides. (实验发现messaging过程中,对broker的吞吐量要求不高,但要求低延迟、高可靠,这些kafka都满足。)
In this domain Kafka is comparable to traditional messaging systems such as ActiveMQ or RabbitMQ. (在messaging方面,Kafka的性能可与ActiveMQ、RabbitMQ相匹敌。)
Website Activity Tracking
The original use case for Kafka was to be able to rebuild a user activity tracking pipeline as a set of real-time publish-subscribe feeds. This means site activity (page views, searches, or other actions users may take) is published to central topics with one topic per activity type. These feeds are available for subscription for a range of use cases including real-time processing, real-time monitoring, and loading into Hadoop or offline data warehousing systems for offline processing and reporting.
Activity tracking is often very high volume as many activity messages are generated for each user page view. (活动追踪,数据流量很大)
Metrics
Kafka is often used for operational monitoring data. This involves aggregating statistics from distributed applications to produce centralized feeds of operational data. (运行状态监控系统,从分布式应用中,汇总统计数据,形成集中的运行监控数据)
Log Aggregation
Many people use Kafka as a replacement for a log aggregation solution. Log aggregation typically collects physical log files off servers and puts them in a central place (a file server or HDFS perhaps) for processing. Kafka abstracts away the details of files and gives a cleaner abstraction of log or event data as a stream of messages. This allows for lower-latency processing and easier support for multiple data sources and distributed data consumption. In comparison to log-centric systems like Scribe or Flume, Kafka offers equally good performance, stronger durability guarantees due to replication, and much lower end-to-end latency. (收集不同物理机器上的log,汇总到a central place:a file server or HDFS。与 Scribe or Flume相比,Kafka提供相当的performance、可靠性、低延迟。)
notes(ningg):日志收集方面,Kafka的性能与Flume相当?Kafka能取代掉Flume吗?
Stream Processing
Many users end up doing stage-wise processing of data where data is consumed from topics of raw data and then aggregated, enriched, or otherwise transformed into new Kafka topics for further consumption. For example a processing flow for article recommendation might crawl article content from RSS feeds and publish it to an “articles” topic; further processing might help normalize or deduplicate this content to a topic of cleaned article content; a final stage might attempt to match this content to users. This creates a graph of real-time data flow out of the individual topics. Storm and Samza are popular frameworks for implementing these kinds of transformations. (在Stream Processing中,Kafka担当data存储功能,即,raw data存储到Kafka中,consumer处理后的结果存储到new kafka topics中)
Event Sourcing
Event sourcing is a style of application design where state changes are logged as a time-ordered sequence of records. Kafka’s support for very large stored log data makes it an excellent backend for an application built in this style. (Event sourcing,事件溯源,记录不同时间点的应用状态变化,通常log数据很大,Kafka满足此需求)
Commit Log
Kafka can serve as a kind of external commit-log for a distributed system. The log helps replicate data between nodes and acts as a re-syncing mechanism for failed nodes to restore their data. The log compaction feature in Kafka helps support this usage. In this usage Kafka is similar to Apache BookKeeper project.
1.3 Quick Start
This tutorial assumes you are starting fresh and have no existing Kafka or ZooKeeper data. (新手入门,对Kafka、Zookeeper一知半解的人,看这儿就对了)
Step 1: Download the code
Download the 0.8.1.1 release and un-tar it.
> tar -xzf kafka_2.9.2-0.8.1.1.tgz
> cd kafka_2.9.2-0.8.1.1
Step 2: Start the server
Kafka uses ZooKeeper so you need to first start a ZooKeeper server if you don’t already have one. You can use the convenience script packaged with kafka to get a quick-and-dirty single-node ZooKeeper instance. (kafka自带了ZooKeeper,不推荐使用)
> bin/zookeeper-server-start.sh config/zookeeper.properties
[2013-04-22 15:01:37,495] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig)
...
Now start the Kafka server:
> bin/kafka-server-start.sh config/server.properties
[2013-04-22 15:01:47,028] INFO Verifying properties (kafka.utils.VerifiableProperties)
[2013-04-22 15:01:47,051] INFO Property socket.send.buffer.bytes is overridden to 1048576 (kafka.utils.VerifiableProperties)
...
Step 3: Create a topic
Let’s create a topic named “test” with a single partition and only one replica:
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
We can now see that topic if we run the list topic command:
> bin/kafka-topics.sh --list --zookeeper localhost:2181
test
Alternatively, instead of manually creating topics you can also configure your brokers to auto-create topics when a non-existent topic is published to. (可通过配置文件,让broker自动创建topic)
Step 4: Send some messages
Kafka comes with a command line client that will take input from a file or from standard input and send it out as messages to the Kafka cluster. By default each line will be sent as a separate message. (kafka自带了一个工具,能够将file或者standard input作为输入,按行传送到kafka cluster中。)
Run the producer and then type a few messages into the console to send to the server.
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
This is a message
This is another message
Step 5: Start a consumer
Kafka also has a command line consumer that will dump out messages to standard output.
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
This is a message
This is another message
If you have each of the above commands running in a different terminal then you should now be able to type messages into the producer terminal and see them appear in the consumer terminal.
All of the command line tools have additional options; running the command with no arguments will display usage information documenting them in more detail. (所有命令行,不夹带参数启动时,会自动弹出usage info)
Step 6: Setting up a multi-broker cluster
So far we have been running against a single broker, but that’s no fun. For Kafka, a single broker is just a cluster of size one, so nothing much changes other than starting a few more broker instances. But just to get feel for it, let’s expand our cluster to three nodes (still all on our local machine). (上述例子中,只启动了一个broker,其最多能够启动几个broker instances。下面说一下如何启动多个broker,构造cluster)
First we make a config file for each of the brokers:(为每个broker,设定属性)
> cp config/server.properties config/server-1.properties
> cp config/server.properties config/server-2.properties
Now edit these new files and set the following properties:
config/server-1.properties:
broker.id=1
port=9093
log.dir=/tmp/kafka-logs-1
config/server-2.properties:
broker.id=2
port=9094
log.dir=/tmp/kafka-logs-2
The broker.id property is the unique and permanent name of each node in the cluster. We have to override the port and log directory only because we are running these all on the same machine and we want to keep the brokers from all trying to register on the same port or overwrite each others data.
(不同的broker,应该设置不同的port和log.dir,否则,broker的数据会相互覆盖。)
notes(ningg):同一台物理主机上,可以启动多个node,每个node通过broker.id唯一标识。
We already have Zookeeper and our single node started, so we just need to start the two new nodes:
> bin/kafka-server-start.sh config/server-1.properties &
...
> bin/kafka-server-start.sh config/server-2.properties &
...
Now create a new topic with a replication factor of three:
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topic
Okay but now that we have a cluster how can we know which broker is doing what? To see that run the describe topics command:
> bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:
Topic: my-replicated-topic Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
Here is an explanation of output. The first line gives a summary of all the partitions, each additional line gives information about one partition. Since we have only one partition for this topic there is only one line.
(describe topics命令的输出结果说明:first line,partition的汇总信息;remaining lines 分别说明每个partition的详细信息)
- leader is the node responsible for all reads and writes for the given partition. Each node will be the leader for a randomly selected portion of the partitions.
- replicas is the list of nodes that replicate the log for this partition regardless of whether they are the leader or even if they are currently alive. (备份当前partition的node列表,包含当前已经不再存活的node)
- isr is the set of “in-sync” replicas. This is the subset of the replicas list that is currently alive and caught-up to the leader.(
replicas内的node中,存活的node列表)
notes(ningg):leader后的数字1,对应的含义?leader是怎么标识的?node怎么标识的?RE:node,本质就是broker,leader也是broker中的一个,borker使用broker.id唯一标识。
Note that in my example node 1 is the leader for the only partition of the topic. We can run the same command on the original topic we created to see where it is:
> bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test
Topic:test PartitionCount:1 ReplicationFactor:1 Configs:
Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
So there is no surprise there—the original topic has no replicas and is on server 0, the only server in our cluster when we created it.
Let’s publish a few messages to our new topic:
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my-replicated-topic
...
my test message 1
my test message 2
^C
Now let’s consume these messages:
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic my-replicated-topic
...
my test message 1
my test message 2
^C
Now let’s test out fault-tolerance. Broker 1 was acting as the leader so let’s kill it:(验证kafka的容错性:kill leader)
> ps | grep server-1.properties
7564 ttys002 0:15.91 /System/Library/Frameworks/JavaVM.framework/Versions/1.6/Home/bin/java...
> kill -9 7564
Leadership has switched to one of the slaves and node 1 is no longer in the in-sync replica set:(leader终止后,slave自动升级为leader)
> bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:
Topic: my-replicated-topic Partition: 0 Leader: 2 Replicas: 1,2,0 Isr: 2,0
But the messages are still be available for consumption even though the leader that took the writes originally is down:(新选出的leader,对用户是透明的,consumer感觉不到异常)
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic my-replicated-topic
...
my test message 1
my test message 2
^C
1.4 Ecosystem
There are a plethora of tools that integrate with Kafka outside the main distribution. The ecosystem page lists many of these, including stream processing systems, Hadoop integration, monitoring, and deployment tools. (有很多工具与Kafka集成,参考页面)
1.5 Upgrading From Previous Versions
Upgrading from 0.8.0 to 0.8.1
0.8.1 is fully compatible with 0.8. The upgrade can be done one broker at a time by simply bringing it down, updating the code, and restarting it.
Upgrading from 0.7
0.8, the release in which added replication, was our first backwards-incompatible release: major changes were made to the API, ZooKeeper data structures, and protocol, and configuration. The upgrade from 0.7 to 0.8.x requires a special tool for migration. This migration can be done without downtime.
2. API
2.1 Producer API
/**
* V: type of the message
* K: type of the optional key associated with the message
*/
class kafka.javaapi.producer.Producer<K,V> {
public Producer(ProducerConfig config);
/**
* Sends the data to a single topic, partitioned by key, using either the
* synchronous or the asynchronous producer
* @param message the producer data object that encapsulates the topic, key and message data
*/
public void send(KeyedMessage<K,V> message);
/**
* Use this API to send data to multiple topics
* @param messages list of producer data objects that encapsulate the topic, key and message data
*/
public void send(List<KeyedMessage<K,V>> messages);
/**
* Close API to close the producer pool connections to all Kafka brokers.
*/
public void close();
}
You can follow this example to learn how to use the producer api.
2.2 High Level Consumer API
class Consumer {
/**
* Create a ConsumerConnector
*
* @param config at the minimum, need to specify the groupid of the consumer and the zookeeper
* connection string zookeeper.connect.
*/
public static kafka.javaapi.consumer.ConsumerConnector createJavaConsumerConnector(ConsumerConfig config);
}
/**
* V: type of the message
* K: type of the optional key assciated with the message
*/
public interface kafka.javaapi.consumer.ConsumerConnector {
/**
* Create a list of message streams of type T for each topic.
*
* @param topicCountMap a map of (topic, #streams) pair
* @param decoder a decoder that converts from Message to T
* @return a map of (topic, list of KafkaStream) pairs.
* The number of items in the list is #streams. Each stream supports
* an iterator over message/metadata pairs.
*/
public <K,V> Map<String, List<KafkaStream<K,V>>>
createMessageStreams(Map<String, Integer> topicCountMap, Decoder<K> keyDecoder, Decoder<V> valueDecoder);
/**
* Create a list of message streams of type T for each topic, using the default decoder.
*/
public Map<String, List<KafkaStream<byte[], byte[]>>> createMessageStreams(Map<String, Integer> topicCountMap);
/**
* Create a list of message streams for topics matching a wildcard.
*
* @param topicFilter a TopicFilter that specifies which topics to
* subscribe to (encapsulates a whitelist or a blacklist).
* @param numStreams the number of message streams to return.
* @param keyDecoder a decoder that decodes the message key
* @param valueDecoder a decoder that decodes the message itself
* @return a list of KafkaStream. Each stream supports an
* iterator over its MessageAndMetadata elements.
*/
public <K,V> List<KafkaStream<K,V>>
createMessageStreamsByFilter(TopicFilter topicFilter, int numStreams, Decoder<K> keyDecoder, Decoder<V> valueDecoder);
/**
* Create a list of message streams for topics matching a wildcard, using the default decoder.
*/
public List<KafkaStream<byte[], byte[]>> createMessageStreamsByFilter(TopicFilter topicFilter, int numStreams);
/**
* Create a list of message streams for topics matching a wildcard, using the default decoder, with one stream.
*/
public List<KafkaStream<byte[], byte[]>> createMessageStreamsByFilter(TopicFilter topicFilter);
/**
* Commit the offsets of all topic/partitions connected by this connector.
*/
public void commitOffsets();
/**
* Shut down the connector
*/
public void shutdown();
}
You can follow this example to learn how to use the high level consumer api.
2.3 Simple Consumer API
class kafka.javaapi.consumer.SimpleConsumer {
/**
* Fetch a set of messages from a topic.
*
* @param request specifies the topic name, topic partition, starting byte offset, maximum bytes to be fetched.
* @return a set of fetched messages
*/
public FetchResponse fetch(kafka.javaapi.FetchRequest request);
/**
* Fetch metadata for a sequence of topics.
*
* @param request specifies the versionId, clientId, sequence of topics.
* @return metadata for each topic in the request.
*/
public kafka.javaapi.TopicMetadataResponse send(kafka.javaapi.TopicMetadataRequest request);
/**
* Get a list of valid offsets (up to maxSize) before the given time.
*
* @param request a [[kafka.javaapi.OffsetRequest]] object.
* @return a [[kafka.javaapi.OffsetResponse]] object.
*/
public kafak.javaapi.OffsetResponse getOffsetsBefore(OffsetRequest request);
/**
* Close the SimpleConsumer.
*/
public void close();
}
For most applications, the high level consumer Api is good enough. Some applications want features not exposed to the high level consumer yet (e.g., set initial offset when restarting the consumer). They can instead use our low level SimpleConsumer Api. The logic will be a bit more complicated and you can follow the example in here.
2.4 Kafka Hadoop Consumer API
Providing a horizontally scalable solution for aggregating and loading data into Hadoop was one of our basic use cases. To support this use case, we provide a Hadoop-based consumer which spawns off many map tasks to pull data from the Kafka cluster in parallel. This provides extremely fast pull-based Hadoop data load capabilities (we were able to fully saturate the network with only a handful of Kafka servers). (Hadoop-based consumer,并行的从Kafka cluster中pull data,速度很快)
Usage information on the hadoop consumer can be found here.
3. Configuration
Kafka uses key-value pairs in the property file format for configuration. These values can be supplied either from a file or programmatically.
3.1 Broker Configs
The essential configurations are the following:
- broker.id
- log.dirs
- zookeeper.connect
详细信息,请参考官网:Broker Configs。
3.2 Consumer Configs
The essential consumer configurations are the following:
- group.id
- zookeeper.connect
详细信息,请参考官网:Consumer Configs
3.3 Producer Configs
Essential configuration properties for the producer include:
- metadata.broker.list
- request.required.acks
- producer.type
- serializer.class
详细信息,请参考官网:Producer Configs
3.4 New Producer Configs
We are working on a replacement for our existing producer. The code is available in trunk now and can be considered beta quality. Below is the configuration for the new producer.
详细信息,请参考官网:New Producer Configs
参考来源
原文地址:https://ningg.top/kafka-documentation/