数据平台系列:海量数据处理——关键思想
2015-06-15
海量数据处理,特点:
- 存储瓶颈:数据量大,单台机器无法满足
- 计算瓶颈:单台机器计算能力有限,无法满足
解决办法:
- 存储集群:可伸缩、易扩展
- 计算集群:可伸缩、易扩展
疑问:
- 网络瓶颈:如果数据量过大,达到网络瓶颈,怎么处理?
补充:Keynote 下载地址:海量数据处理:关键思想.pdf
1. 基本原理
1.1. 典型场景
典型场景:词频统计,统计下面文本中,所有单词出现的频率。

Hadoop 生态中,典型的处理过程:
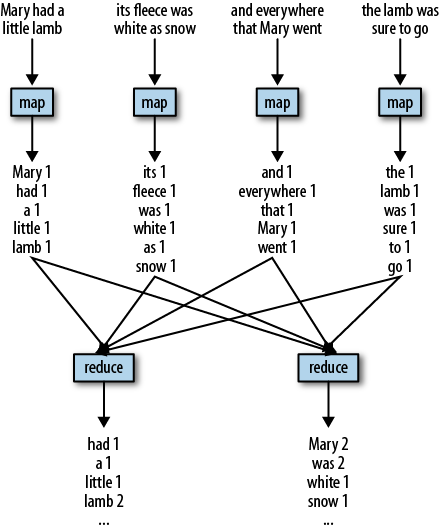
上面是,常说的 Map-Reduce,简单说明:
- Map:
- 是什么含义?
- 输入,是什么?
- 输出,是什么?
- 作用,是什么?数据处理,快速的数据处理,通常处理逻辑简单
- Reduce:
- 是什么含义?
- 输入,是什么?
- 输出,是什么?输出的数据单元 <= 输入数据单元数量
- 作用,是什么?对 map 结果进行聚合、收敛
1.2. 基本原理剖析
实际上,上述场景包含更丰富的内容:
- 分片:Map 之前的数据切割、分片
- 分发:Map 之后,将 Map 结果 shuffle 到特定的 Reduce 进行聚合
- Multi-MapReduce:一次 MR 之后,通常还没有结束,会再次进行 Map 或 Reduce
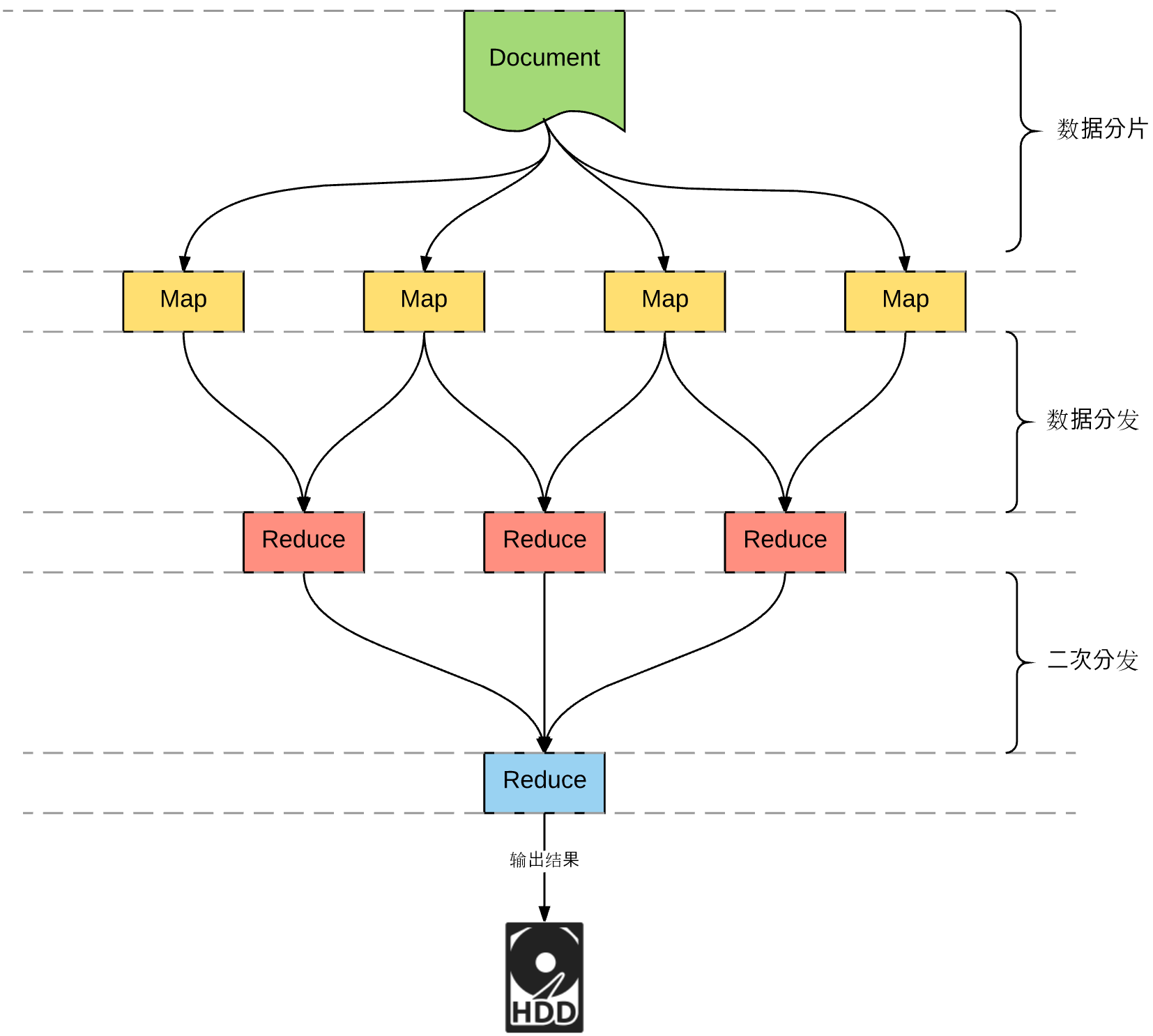
Note:数据分片、数据分发之间的区别:
- 数据分片(partition):第一次进行数据处理之前,并不知道数据的具体内容,因此,是简单的数据切割
- 数据分发(shuffle):已经知道数据的具体内容,按照既定的业务逻辑,将特定的数据,送入特定的节点,数据分发中,要处理的典型问题:数据倾斜
数据倾斜:部分处理节点承担的输入数据过多,因此,需要更多的执行时间,最终导致整个任务执行时间过长。
1.3. 小结
根据上面的基本原理:
- 海量数据处理,涉及 4 个典型过程:数据分片、Map、Shuffle、Reduce
- 海量数据处理,调优时,根据具体的业务场景、数据特征,减弱「数据倾斜」现象
- Map-Reduce 是一种编程模型,实现方式可以有多种,代表性的实现,就是 Hadoop
疑问:
- 上面的场景,潜在瓶颈在哪?海量数据,各种瓶颈
2. Key Point:分发计算
上面描述的典型过程是,分布式计算。
面对海量数据,单个存储节点,无法完成所有数据的存储,因此,采用分布式存储。
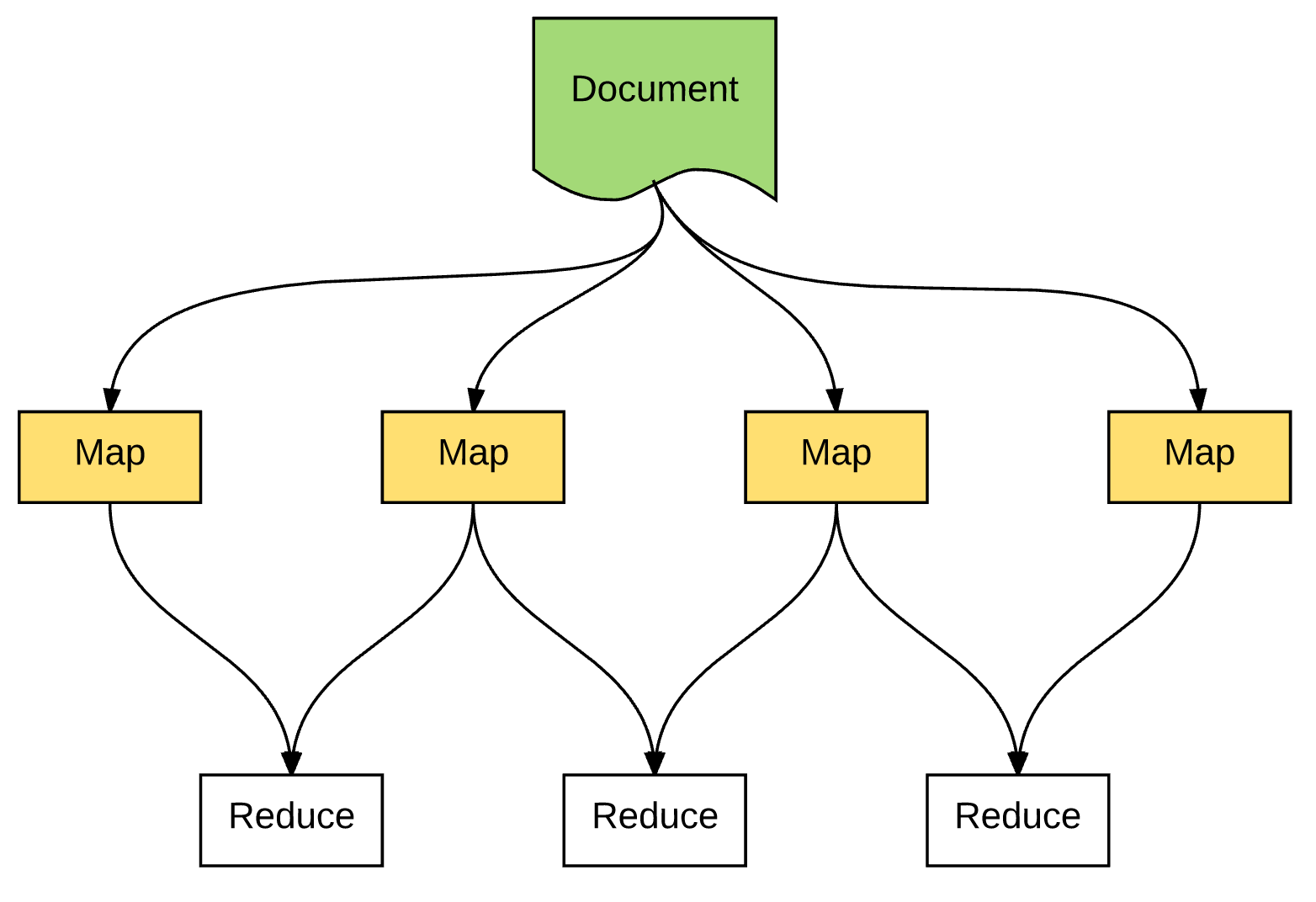
升级为分布式存储之后,整体架构:
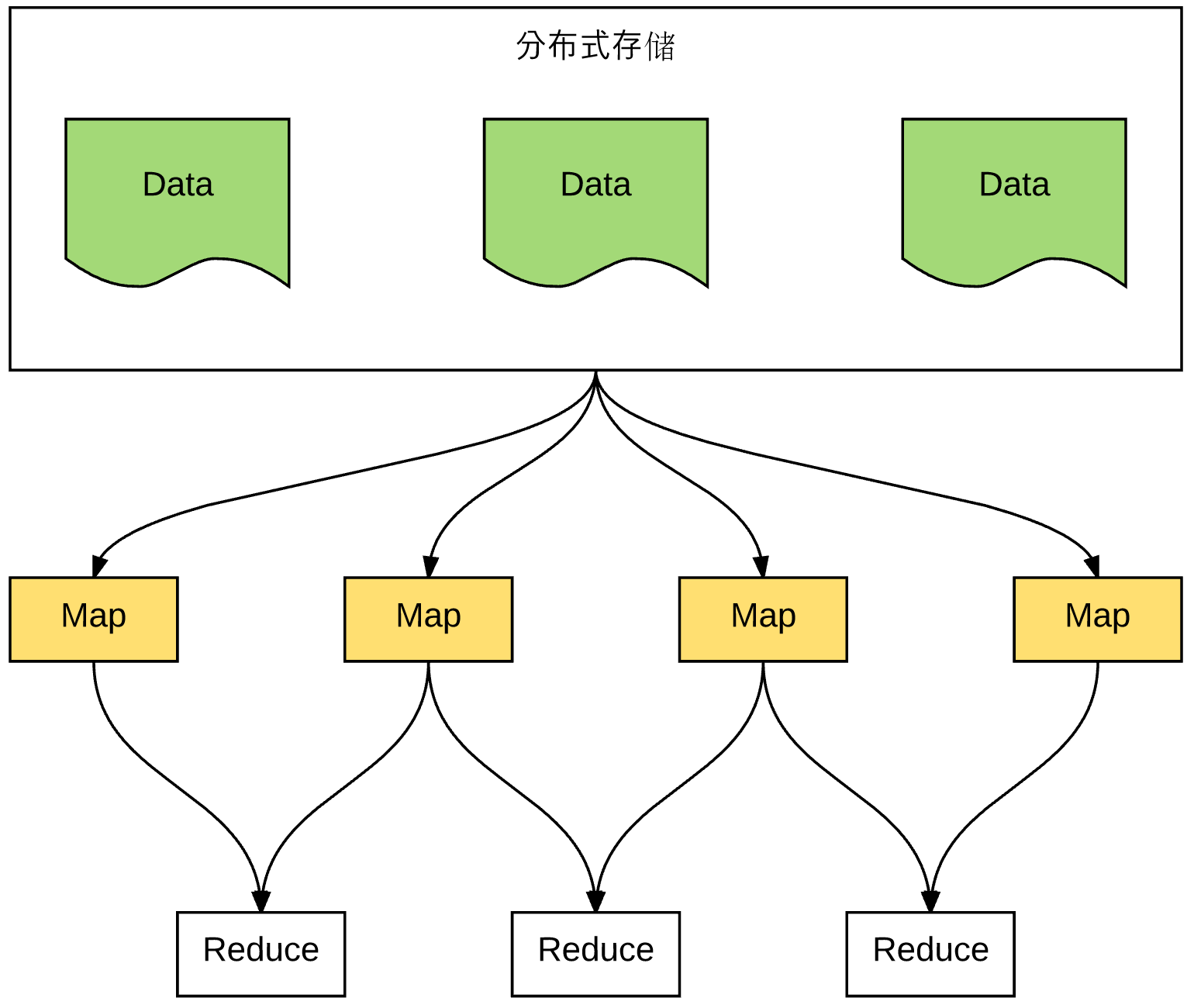
2.1. 存在的问题
小数据量时,都没有问题,一旦是真的海量数据,就会导致:数据分片过程中,Map 节点读取 Data 时,耗费大量的网络带宽,网络被打满,成为新的瓶颈,随着数据量的剧增,达到网络带宽的瓶颈。
几个瓶颈及解决思路:
- 磁盘容量的瓶颈:采用分布式存储解决
- 单机计算能力的瓶颈:采用分布式计算解决
- 网络带宽的瓶颈:海量数据,Map 节点,读取海量数据,达到网络,怎么办?
2.2. 解决思路
为什么会出现:网络带宽瓶颈?
本质原因:
Map 节点,计算过程中,需要输入,需要数据,就从其他地方读取数据,耗费网络带宽。
换个思路,就能解决上述问题,上述本质原因是:分发数据,即,计算节点把数据,读取到计算节点本地,耗费大量网络。
解决思路:分发计算(Deliver Computation),把计算逻辑(计算代码)分发到 Data 所在的数据节点上,就能极大降低网络消耗,简直是天才。
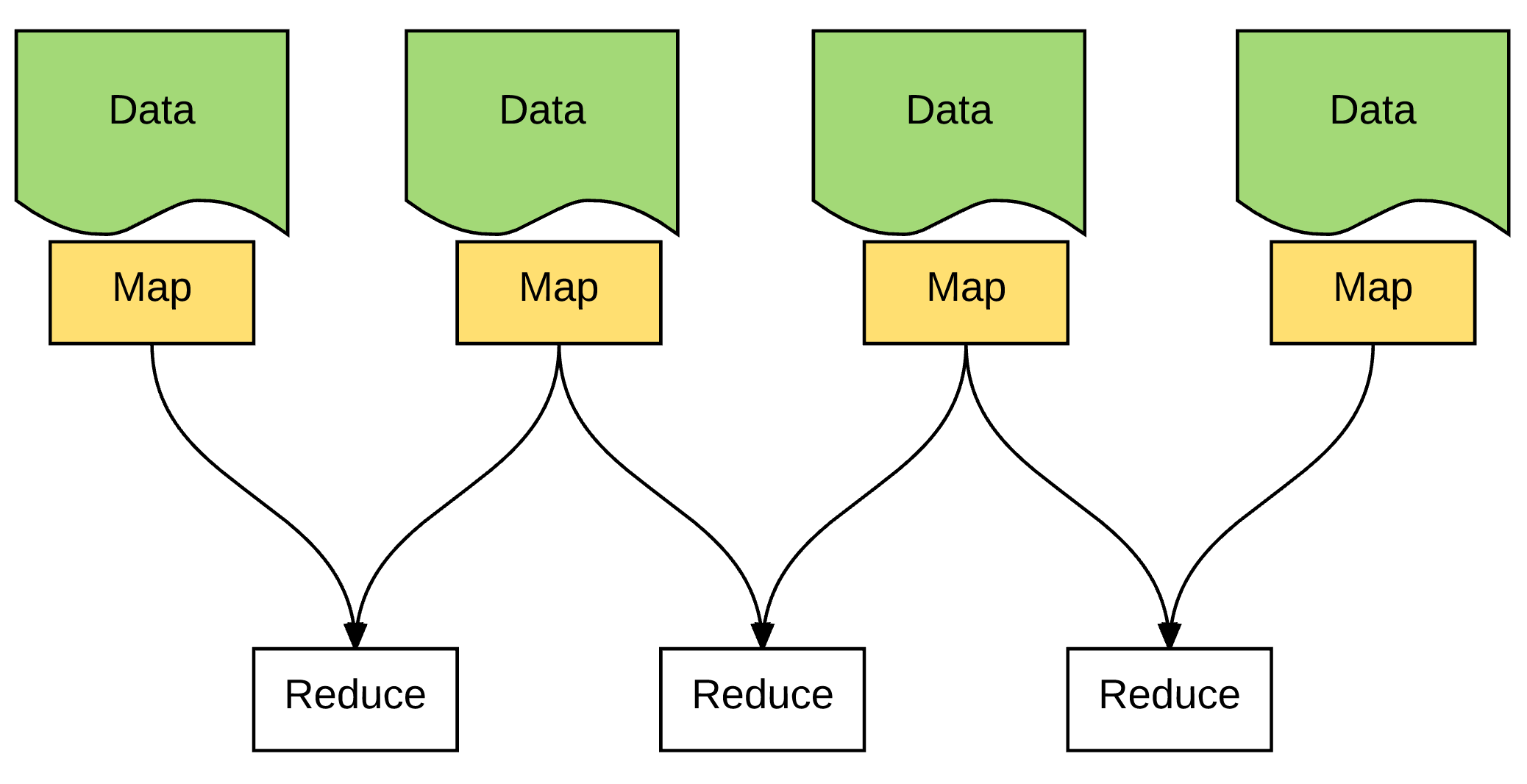
3. Key Point:机架感知
3.1. 存在的问题
上面分发计算的基本思路是:把计算逻辑分发到数据节点上,就能避免大量的网络传输,解决海量数据处理场景下的带宽瓶颈。
但实际上,分布式存储跟分布式计算,是要保持一定的隔离的:
- 过度的耦合:会限制两个系统(计算引擎和存储引擎)性能的发展和演进,无法实现计算引擎的可插拔
- 计算能力受限:数据节点的数目,不应跟处理节点的数目绑定,即,不能因为节点数量,限制计算能力上限
- 因此,不能让 Map 紧贴 Data。
3.2. 解决思路
既然不能让 Map 紧贴 Data,那就让他们尽可能贴近就好了。
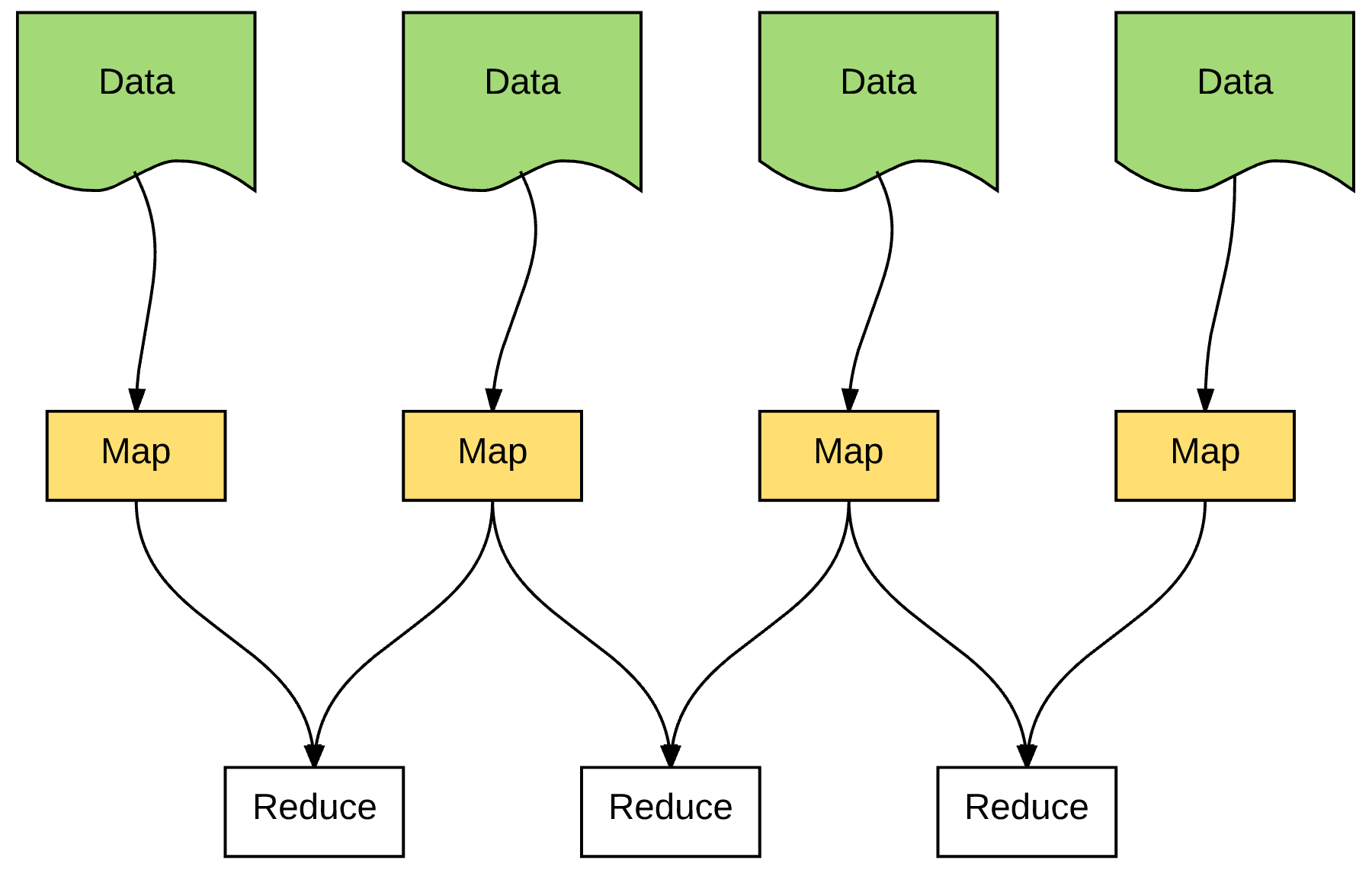
尽可能让离 Data 物理距离近的 Map 来处理相应的 Data。
物理距离,一般以:机架、机房来划分,即,同机架、同机房。
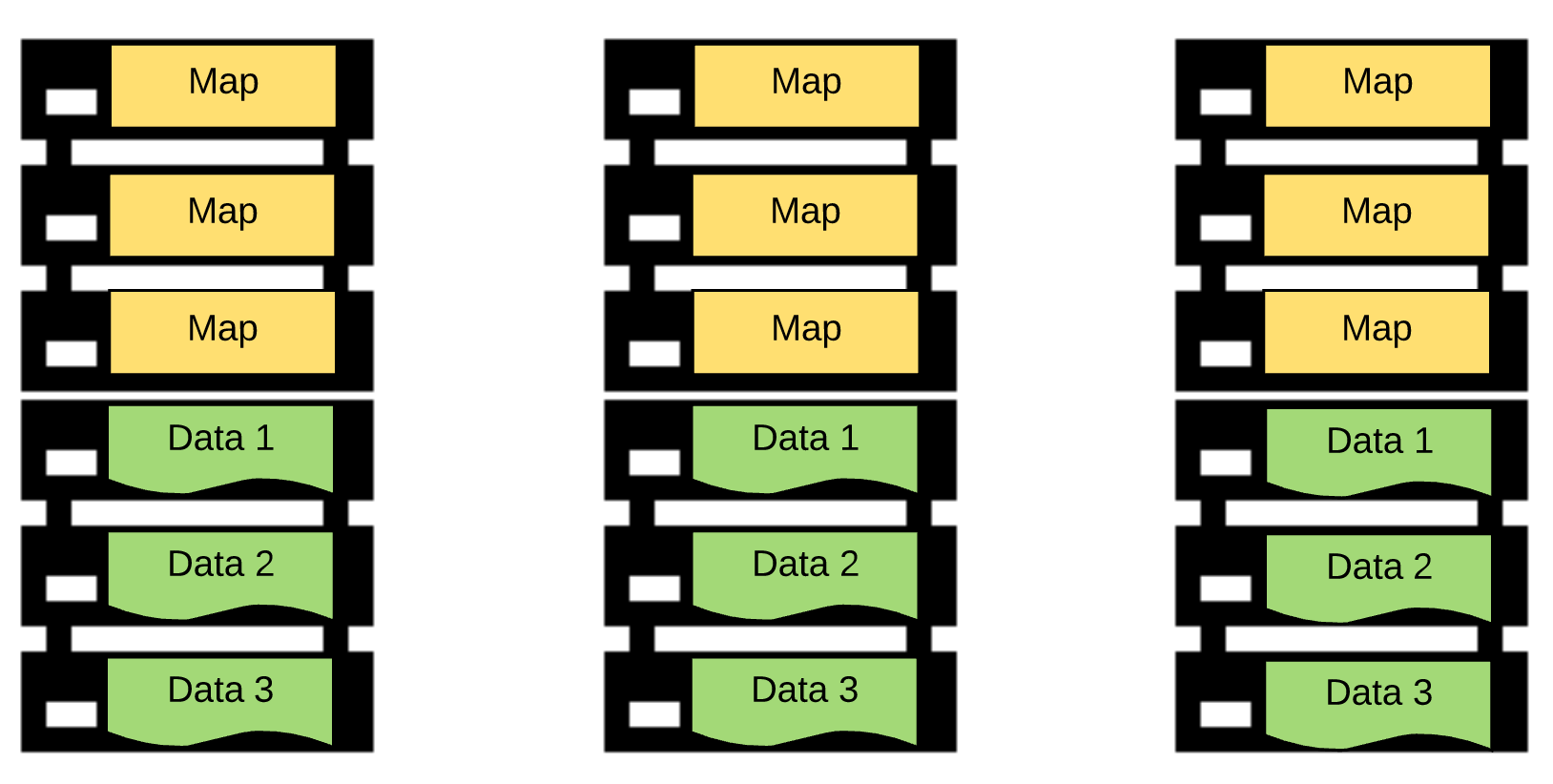
Note:补充说明,分不是存储,为了提高系统的可靠性,一般会设置数据的副本个数,例如,设置数据副本数为 3, 则,采取适当策略,会在至少 3 个机架中,都存在同样的一份数据。
4. 小结
本质:局部性原理(Principle Of Locality),就近原则(远亲近邻)
- 网络局部性原理
- 磁盘局部性原理
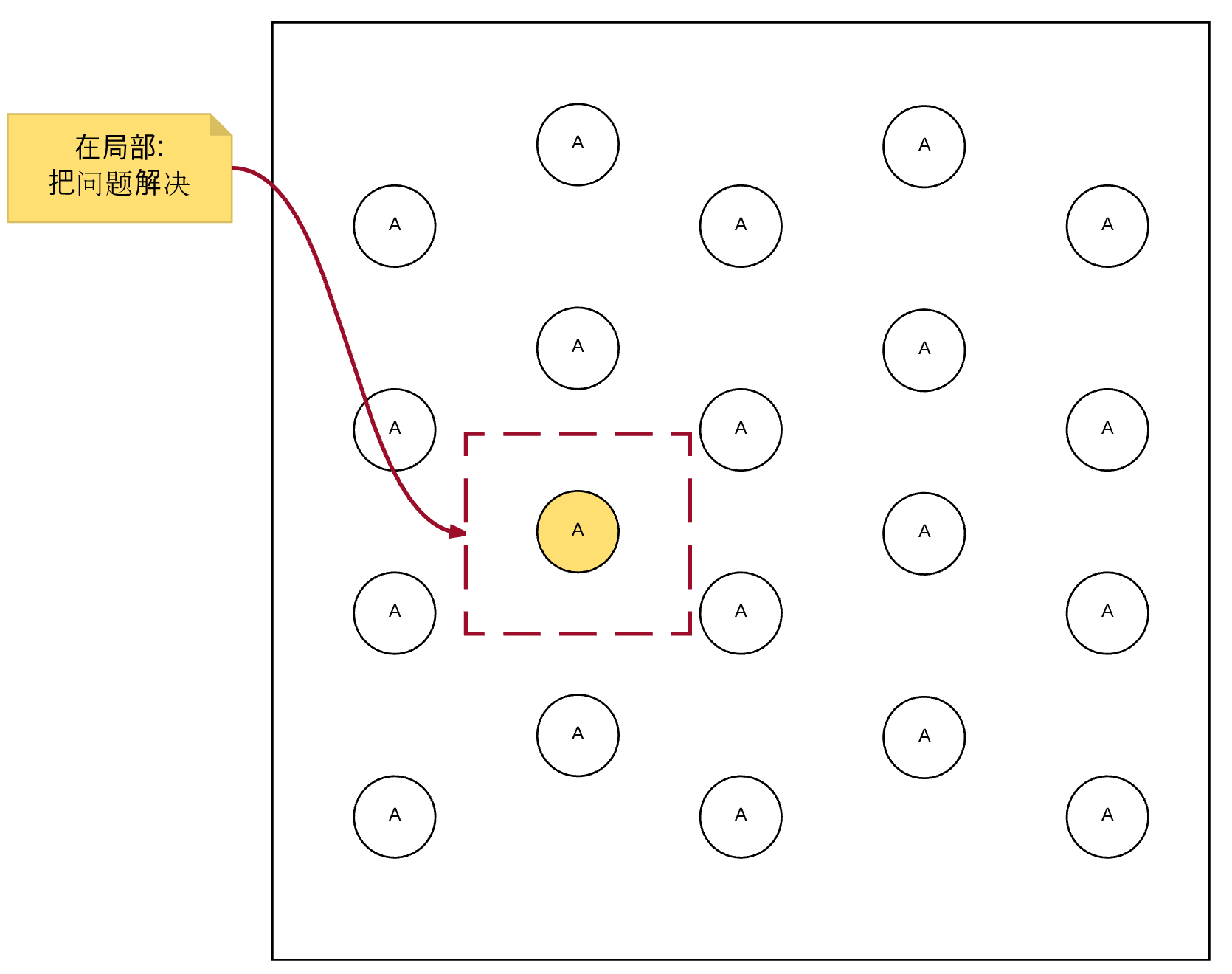
扁鹊早就知道局部性原理的厉害之处:
魏文王问扁鹊曰:「子昆弟三人其孰最善为医?」
扁鹊曰:「长兄最善,中兄次之,扁鹊最为下。」
魏文侯曰:「可得闻邪?」
扁鹊曰:
长兄於病视神,未有形而除之,故名不出於家。
中兄治病,其在毫毛,故名不出於闾。
若扁鹊者,鑱血脉,投毒药,副肌肤,闲而名出闻於诸侯。
5. 参考来源
- Dean J, Ghemawat S. MapReduce: simplified data processing on large clusters[J]. Communications of the ACM, 2008, 51(1): 107-113.
- Hadoop and HDFS: Storage for Next Generation Data Management (White Paper of Cloudera)
- Principle Of Locality wiki
- http://hadoop.apache.org/
原文地址:https://ningg.top/massive-data-series-process-massive-data-key-points/