Redis 设计与实现:数据结构
2015-12-17
背景
Redis 采用最简的思路,实现了几个数据结构,向上支持对象,每个数据结构都有自己的特点,汇总整理一下:
- 简单动态字符串(SDS)
- 链表
- 字典
- 跳跃表:skip list
- 整数集合
- 压缩列表
- 对象
Redis 上层的对象:字符串、列表、哈希、集合、有序集合5种数据类型
- REDIS_STRING,编码是整数数值或 SDS 类型(和 embstr 字符串,将 SDS 与 redisObject 紧挨着申请内存空间,一种优化,缓存友好,当字符串长度小于等于32时用)
- REDIS_LIST,编码是 ziplist 或 linkedlist。所有字符串长度小于 list-max-ziplist-value (64),元素数量少于 list-max-ziplist-entries (512) 时使用 ziplist
- REDIS_HASH,编码可以是 ziplist 或者 hashtable。所有字符串长度小于 hash-max-ziplist-value (64),元素数量少于 hash-max-ziplist-entries (512) 时使用 ziplist
- REDIS_SET,编码是 intset 或 hashtable。所有元素都是整数并且长度小于 set-max-intset-entries (512) 时使用 inset
- REDIS_ZSET,编码是 ziplist 或者 skiplist。所有字符串长度小于 zset-max-ziplist-value (64),元素数量少于 zset-max-ziplist-entries (128) 时使用 ziplist(这里的 ziplist 是按照 score 排序的)
跳跃表(Skip List)
解决的问题和思路
目标:
跳跃表(Skip List),为了解决有序链表的
查询、插入效率问题。备注:
跳跃表(Skip List)是链表,是有序链表,是基于有序链表的多层有序链表。
具体效果:
- 普通链表:
有序链表的查询、插入,时间复杂度,都是O(N) - 跳跃表:
有序链表的查询、插入,时间复杂度,都是O(logN),恶化情况为O(N)
具体思路:
- 充分利用特性:跳跃表充分利用了
有序链表的特性,基于有序链表的前提条件,进行优化 - 空间换时间:跳跃表基于
有序链表,创建多层链表,可以看作索引文件,提升查询\插入效率
实现细节
跳跃表的具体存储形式:
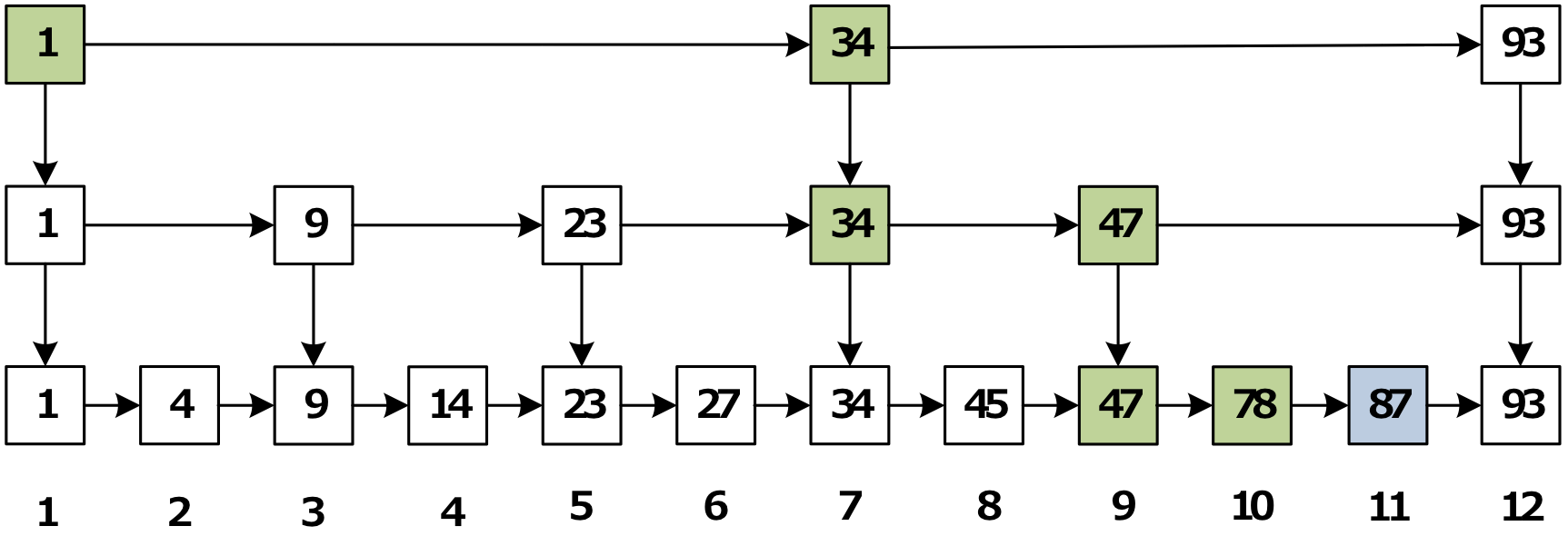
查询\插入场景下,使用上面跳跃表的数据结构,很简单,从上层一步一步操作下来即可。
现在的问题是:上面的数据结构,是如何构造的?如何维护的?
跳跃表的具体构造过程:节点逐个插入,
单个节点的插入过程,细节:
- 随机一个层数
x;(x在 1~32 之间); - 利用现有的多层有序列表,找到即节点在
第1层的位置; - 在层数
x及以下各层,都生成一个完全相同的节点,每个节点的取值完全相同,上层节点,指向下层节点; - 插入一个节点完毕;
注:多层的有序链表,最底层称为 第1层。
特别说明:
- 实际上,跳跃表跟二叉查找树类似,都是由一个个节点,逐步插入而形成的;
- 跳跃表跟二叉查找树,作用也一致,都是提升查询、插入效率;
- 跳跃表相对二叉查找树优势:实现思路简单、容易实现、容易理解;代价是:数据冗余;
redis中skiplist应用场景
排名存储
存储用户排名,尤其是网络游戏中存储用户排行榜时,会有很多适用的场景
- 获取 top(N) 操作
- 查询第X名的用户
- 已知用户,查询其名次
- 查询排名在某一范围的用户,例如对某一排名区域的用户发放对应的奖励
Redis 集群分片存储
redis集群中,使用跳跃表,维护 slot-key 之间的对应关系(slot 中增加/删除 Key):
- 在cluster.h—>clusterState 数据结构中,定义了一个跳表 zskiplist
*slots_to_keys; slots_to_keys中分值 score 是每一个槽号,具体存储内容 obj 是数据库的键 key- 每当节点 cluster-node 往数据库添加一个新的 KV 时,cluster-node 会将这个键及槽号关联到
slots_to_keys跳表 - 每当节点 cluster-node 删除一个 KV 时,cluster-node 会在
slots_to_keys跳表中解除删除的键与槽号的关联
特别说明:
- Redis 集群中,根据 key 计算出 slot;
- slots-to-keys 跳跃表中,slot 是有序链表,具体的应用数据是’keys’的引用
- Redis 扩容时,会找出一个 slot 下的所有 keys,然后进行迁移。
原文地址:https://ningg.top/redis-lesson-11-redis-data-structure/