正则表达式(字符串匹配模式)
2014-05-04
背景
最近师兄安排我用Pig解析一下日志文件,在数据装载过程中,需要抽取特定位置的字符串(即使是数字、符号,在程序看来也是字符)。
回想起之前的团队中,CZW对正则表达式进行过技术分享,深入浅出,反正当时我是听懂了,应该也达到了能用的水平,无奈10月左右的时间,只剩下点滴印象了,(唉,时光已去,曾经掌握的东西,当要用时,又需要重新去学,这正是自己写技术博客的原因之一)
不多说了,接下来,将整体上对正则表达式来一个梳理。
正则表达式,是什么?
正则表达式,英文原名: Regular Expression(简称:regex或regexp),直接翻译:有规律的式子,或者,可以翻译为描述规律的式子。(他奶奶的,不知道谁第一个翻译的,取名正则表达式?忒高大上了,听上去完全不知到干什么的,还是描述规律的式子容易理解)

解决什么问题?
通俗的说:查找满足一定规则的字符串。
可用于文本的查找、替换。
应用场景举例
- 场景1:仅查找出文本中单词
car,不想找出其他单词scar、carry等。 - 场景2:用户在注册页面填写Email时,检查Email地址格式是否正确。
- 场景3:查找指定目录下,文件名中包含
application字样的文件。
正式定义
正则表达式,给个正式定义:按一定规则查找字符串,并可以进行替换操作。
正则表达式,几点要注意的内容:
- 有自己的语法规则,即,正则表达式语言;
- 不是正规的(完备的)程序设计语言,没有专门针对正则表达式的软件,来安装和运行;
- 常内置于其他软件/语言中;(即,其他语言实现了正则表达式规则的解析器)
当前,java/Python/PHP/JavaScript等,都支持正则表达式。
支持正则表达式的语言\工具:Applications and Languages Related with RegEx
产生的启发点
1950年左右时,数学领域的一些研究工作
A logical calculus of the ideas immanent in nervous activity, 1943; Author: McCulloch, Warren S., and Walter Pitts; 简述:神经系统中神经元看作小巧而简单的自动控制单元。
Representation of Events in Nerve Nets and Finite Automata, 1956; Author: Kleene, Stephen C; 简述:“正则集合”的数学符号来描述此模型。
几年后,计算机领域借助上述研究成果,实现perl、grep等工具/语言,正则表达式进入实用阶段。
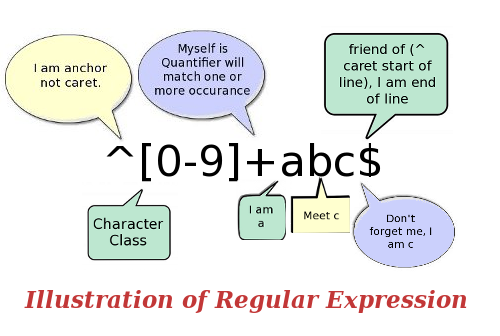
校正:上面图片Illustration of Regular Expression中,Meet c应该修正为Meet b。
怎么用?
正则表达式,俗称描述规律的式子,用来查找字符串,基本逻辑是:
- 如何匹配出1个字符;
- 如何匹配出n个字符;
- 如何匹配出特定位置的字符;(特定位置:字符串的开头、结尾)
匹配1个字符
| 字符 | 含义 |
|---|---|
| a | 一个字符a |
| [abc] | [..]表示集合内的任意一个字符,在此例中,[abc]表示a、b、c字符中的任意一个 |
| [^abc] | 除去a、b、c之外的任意一个字符,注意,^只限于在[^位置,才表示此含义 |
| [0123456789] | 任意一个数字 |
| [a-z] | 任意一个消息字母(在[]内-为特殊字符,代表区间) |
| [0-9] | 任意一个数字,等同于[0123456789] |
| . | 任意一个字符 |
| \f | 换页符 |
| \t | 制表键,tab |
| \r | 回车符,return |
| \n | 换行符,nextLine |
| \v | 垂直制表符 |
| \w | 等价于[a-zA-Z0-9],任何一个字母(区分大小写)、数字、下划线 |
| \W | 等价于[^a-zA-Z0-9],任何一个非字母(区分大小写)、数字、下划线 |
| \d | 任何一个数字字符,等价于[0-9] |
| \D | 等价于[^0-9],任何一个非数字字符 |
| \s | 等价于[ \f\n\r\t\v],任何一个空白字符 |
| \S | 等价于[^ \f\n\r\t\v],任何一个非空白字符 |
| \x0A | (16进制)对应ASCII字符10,即\n |
| \011 | (8进制)对应ASCII字符9,即\t |
校正:关于\s,《正则表达式必知必会》 版本信息(2007年12月,第1版),在Page 31中,\s表示任何一个空白字符,应该包含空格 在内(具体参考:Shorthand Character Classes Of Regex)
匹配n个字符
匹配n个字符,就是“匹配一个字符”重复n次,嗯,很简单,则有:aa,表示匹配连续两个字符a;\d\d,表示匹配2个数字;\n\n\n,表示匹配3个换行符。(很简单有木有)
问题来了,假设有如下文本:
I $am$ the $god$.
目标:查找出$..$间的内容,正则表达式怎么写?($..$间字符的个数,不能确定,只知道1个以上)
我x,不是说要“匹配一个字符”重复n次就可以么?关键现在n是几啊?这怎么还是一个范围(n>=1)?这如何是好?
莫急莫急,请往下看。
| 字符 | 含义 |
|---|---|
| ? | 0次或1次 |
| + | 1次以上(a+:表示一个或多个a的连续出现;[0-9]+:表示一个或多个连续出现的数字) |
| * | 0次及0次以上 |
| {3} | 3次 |
| { ,3} | 0次–3次(包含0次和3次) |
| {1, } | 1次以上 |
| {1,3} | 1次–3次(包含1次和3次) |
到这儿,就可以看出,使用 $.+$就能匹配上面的内容了。
匹配特定位置字符
| 字符 | 含义 |
|---|---|
| ^ | 在字符串开头 |
| $ | 在字符串结尾 |
| \b | 单词的边界 |
| \B | 非单词的边界 |
匹配出如下文本中的cat单词:
cat catt
正则表达式:\bcat\b
匹配如下文本中的-,要求:只找出两个字母之间的-,文本内容:
A-b - ss s- f- - a-
正则表达式:\B-\B
过度匹配(贪婪)
要匹配文本
ben@cib.com.cn
正则表达式:\w+@\w[\w\.]+\.\w+
理论上,可以匹配出:
ben@baidu.comben@baidu.com.cn
但是,上述匹配结果是2,即ben@cib.com.cn。原因:+、*默认都是贪婪匹配,即找出最长的匹配模式;如果希望匹配出结果1,即ben@cib.com,惰性匹配,找出最短的匹配模式,需要修改正则表达式:\w+?@\w[\w\.]+?\.\w+?,即+替换为+?,*替换为*?。
| 贪婪匹配 | 懒惰字符 |
|---|---|
| * | *? |
| + | +? |
| {n, } | {n, }? |
补充说明
| 字符 | 含义 |
|---|---|
| \ | 转义字符,例如,\. 表示.字符本身,单独.表示匹配任意一个字符;\?表示?字符自身 |
| |
表示其前后两种模式的任意一个,例如(19|20)\d{2},匹配19xx和20xx,xx表示任意两位数字 |
| () | 子表达式,整体上看作一个独立元素 |
假设有一个文本
Hello, my name is Ben
… Node.js, Linux , and other tech.
现在要匹配出连续的两个 ,可以使用 ,也可以使用( ){2},而不能使用 {2},因为{2},表示匹配其前面字符,实际 {2}等价与 ;。
匹配IP:10.108.210.111
正则表达式:\d{1,3}\. \d{1,3}\. \d{1,3}\. \d{1,3}\
可以替换为: (\d{1,3}\.){3}\d{1,3}\
高级用法
子表达式
前文提到过,在这儿单独拿出来说,是因为下文要用到。(尼玛,下文难道不会用到前文其他内容么?凭什么单说子表达式啊;因为,实在是怕你忘了,其他内容你即使忘了,也容易自己查找)
引用回溯
本质:前后匹配一致;
技术上实质:后半部分引用前半部分匹配到的子表达式。
举例:
匹配如下文档中重复输入的单次:
This is a block of of text, several words here are are repeated, and and they should not be.
正则表达式:[ ]+(\w+)[ ]+\1
\1表示(\w+)中匹配到的内容。
注意:回溯引用中\1,\2只能一用子表达式(即用()括起来的部分),\0代表整个正则表达式匹配的结果。
前后查找
本质:匹配全部,返回局部;
技术上实质:将子表达式向前(后)匹配到字符串返回。
- 向前查找: 正 向前查找
exp2(?=exp1), 负 向前查找(exp2(?!exp1)); - 向后查找: 正 向后查找
(?<=exp1)exp2, 负 向后查找(?<!exp1)exp2;
注:上式都是匹配exp1,返回exp2。
举例1:
匹配如下文本中的传输协议
http://www.baidu.com
ftp://ftp.baidu.com
https://mails.baidu.com
正则表达式:.+(?=:)
举例2:
匹配如下文本中的金额
abc: $23.01
hdc: $899.00
正则表达式:(?<=\$)\d[\d.]*\d
嵌入条件
可以添加逻辑条件,类似if。
说几点:
- 功能很强大;
- 使用的不是很多;
- 真要了解一下,参考《正则表达式必知必会》
元字符?
啥?元字符?什么东东?小伙儿,不要激动。正则表达式为了描述匹配哪些位置的字符串,使用了.,\d,\s,\w,\W,^,[],(),|,$,来描述正则表达式语言的语法,即,这些字符是表述正则表达式语言语法规则的字符,成为这个语言的元字符。
参考来源
休息一下
你能读懂下面这张图片吗?
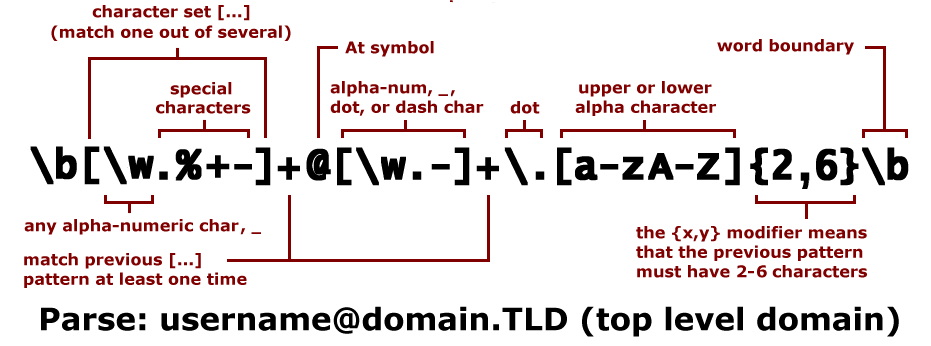
原文地址:https://ningg.top/regular-expression/