Storm 0.9.2:Tutorial
2014-10-20
原文地址:Storm Tutorial,本文使用
英文原文+中文注释方式来写。
In this tutorial, you’ll learn how to create Storm topologies and deploy them to a Storm cluster. Java will be the main language used, but a few examples will use Python to illustrate Storm’s multi-language capabilities. (这个tutorial中,着重说明:如何创建Storm topologies,如何将Storm topologies部署到Storm cluster中。)
Preliminaries
This tutorial uses examples from the storm-starter project. It’s recommended that you clone the project and follow along with the examples. Read Setting up a development environment and Creating a new Storm project to get your machine set up. (example都是来自storm-starterproject,建议clone一份,跟着例子操作一把。在此之前,需要参考Setting up a development environment 和 Creating a new Storm project来配置一下环境)
Components of a Storm cluster
A Storm cluster is superficially similar to a Hadoop cluster. Whereas on Hadoop you run “MapReduce jobs”, on Storm you run “topologies”. “Jobs” and “topologies” themselves are very different – one key difference is that a MapReduce job eventually finishes, whereas a topology processes messages forever (or until you kill it).
(Storm cluster与Hadoop cluster类似,Hadoop中运行MapReduce jobs,Storm中运行topologies。)
There are two kinds of nodes on a Storm cluster: the master node and the worker nodes. The master node runs a daemon called “Nimbus” that is similar to Hadoop’s “JobTracker”. Nimbus is responsible for distributing code around the cluster, assigning tasks to machines, and monitoring for failures.
(Storm cluster中两类node:master node、worker node;master上运行一个daemon——Nimbus,其负责:distribute code,assign task,monitor failures)
Each worker node runs a daemon called the “Supervisor”. The supervisor listens for work assigned to its machine and starts and stops worker processes as necessary based on what Nimbus has assigned to it. Each worker process executes a subset of a topology; a running topology consists of many worker processes spread across many machines.
(worker上运行daemon——Supervisor,监听来自Nimbus的任务,并starts或stop worker process。每个worker process执行了topology的一部分,也就是说,a running topology 包含很多分布在不同机器上的worker process。)
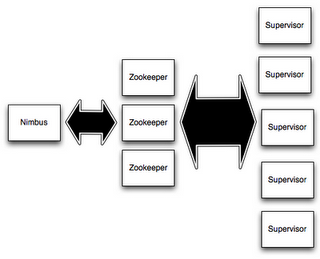
All coordination between Nimbus and the Supervisors is done through a Zookeeper cluster. Additionally, the Nimbus daemon and Supervisor daemons are fail-fast and stateless; all state is kept in Zookeeper or on local disk. This means you can kill -9 Nimbus or the Supervisors and they’ll start back up like nothing happened. This design leads to Storm clusters being incredibly stable.
(Zookeeper cluster负责Nimbus和Supervisor之间的协调;Nimbus和Supervisor deamon是fail-fast和stateless的,所有的状态都存储在Zookeeper or local disk;即,通过kill -9 Nimbus/Supervisor,然后重启进程,对于用户基本是透明的)
notes(ningg):fail-fast,表示如果输入有误,或者其他异常,则系统立刻停止运行。
举例说明一下
fail-fast:在并发的时候,如果线程A正遍历一个collection(List, Map, Set etc.),这时另外一个线程B却修改了该collection的size,线程A就会抛出一个错:ConcurrentModificationException,表明:我正读取的内容被修改掉了,你是否需要重新遍历?或是做其它处理?这就是fail-fast的含义。Fail-fast是并发中乐观(optimistic)策略的具体应用,它允许线程自由竞争,但在出现冲突的情况下假设你能应对,即你能判断出问题何在,并且给出解决办法。悲观(pessimistic)策略就正好相反,它总是预先设置足够的限制,通常是采用锁(lock),来保证程序进行过程中的无错,付出的代价是其它线程的等待开销。
Topologies
To do realtime computation on Storm, you create what are called “topologies”. A topology is a graph of computation. Each node in a topology contains processing logic, and links between nodes indicate how data should be passed around between nodes. (topology中每个node都包含了相应的processing logic)
Running a topology is straightforward. First, you package all your code and dependencies into a single jar. Then, you run a command like the following:(执行 a topology:将your code和dependencies都放到一个jar中)
storm jar all-my-code.jar backtype.storm.MyTopology arg1 arg2
This runs the class backtype.storm.MyTopology with the arguments arg1 and arg2. The main function of the class defines the topology and submits it to Nimbus. The storm jar part takes care of connecting to Nimbus and uploading the jar.
(storm jar负责connecting to Nimbus,以及uploading the jar;同时其中指定的 main 方法负责向Nimbus提交Topology)
Since topology definitions are just Thrift structs, and Nimbus is a Thrift service, you can create and submit topologies using any programming language. The above example is the easiest way to do it from a JVM-based language. See Running topologies on a production cluster for more information on starting and stopping topologies. (利用Thrift structs,来定义topology,并且,Nimbus是Thrift service,因此,可以使用任何编程语言。)
notes(ningg):Thrift structs? Thrift service?
Streams
The core abstraction in Storm is the “stream”. A stream is an unbounded sequence of tuples. Storm provides the primitives for transforming a stream into a new stream in a distributed and reliable way. For example, you may transform a stream of tweets into a stream of trending topics.
(Storm的核心是Stream,Storm提供一种分布式的、可靠的数据流转换方式,将原始数据流处理后,转换为其他的数据流)
The basic primitives Storm provides for doing stream transformations are “spouts” and “bolts”. Spouts and bolts have interfaces that you implement to run your application-specific logic.
(Storm通过spouts和bolts来实现stream transformation)
A spout is a source of streams. For example, a spout may read tuples off of a Kestrel queue and emit them as a stream. Or a spout may connect to the Twitter API and emit a stream of tweets. (spout是a source of streams)
A bolt consumes any number of input streams, does some processing, and possibly emits new streams. Complex stream transformations, like computing a stream of trending topics from a stream of tweets, require multiple steps and thus multiple bolts. Bolts can do anything from run functions, filter tuples, do streaming aggregations, do streaming joins, talk to databases, and more. (bolt负责处理input stream,也可能产生new stream;bolt通过run functions,filter tuples,do streaming aggregations,do streaming joins,talk to database,etc…来做任何事情)
Networks of spouts and bolts are packaged into a “topology” which is the top-level abstraction that you submit to Storm clusters for execution. A topology is a graph of stream transformations where each node is a spout or bolt. Edges in the graph indicate which bolts are subscribing to which streams. When a spout or bolt emits a tuple to a stream, it sends the tuple to every bolt that subscribed to that stream.
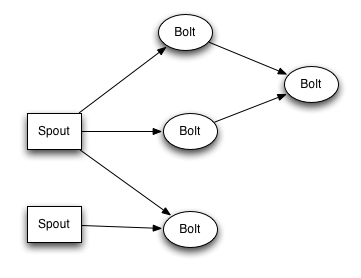
Links between nodes in your topology indicate how tuples should be passed around. For example, if there is a link between Spout A and Bolt B, a link from Spout A to Bolt C, and a link from Bolt B to Bolt C, then everytime Spout A emits a tuple, it will send the tuple to both Bolt B and Bolt C. All of Bolt B’s output tuples will go to Bolt C as well.
Each node in a Storm topology executes in parallel. In your topology, you can specify how much parallelism you want for each node, and then Storm will spawn that number of threads across the cluster to do the execution. (topology中所有node都是并发运行的,可以配置每个node的并发数。)
A topology runs forever, or until you kill it. Storm will automatically reassign any failed tasks. Additionally, Storm guarantees that there will be no data loss, even if machines go down and messages are dropped. (topology会自动重启失败的任务,并且run forever——因为是stream processing;即使Nimbus、Supervisor机器崩溃并且message丢失,Storm也能保证no data loss)
notes(ningg):Storm如何保证Nimbus、Supervisor崩溃后,no data loss的?
Data model
Storm uses tuples as its data model. A tuple is a named list of values, and a field in a tuple can be an object of any type. Out of the box, Storm supports all the primitive types, strings, and byte arrays as tuple field values. To use an object of another type, you just need to implement a serializer for the type.
(Storm中用tuple结构来存储数据,tuple中的field可以是任何类型的object,自定义的类型,需要实现a serializer接口)
Every node in a topology must declare the output fields for the tuples it emits. For example, this bolt declares that it emits 2-tuples with the fields “double” and “triple”: (每个spout、bolt都要定义输出的tuple的结构)
// java
public class DoubleAndTripleBolt extends BaseRichBolt {
private OutputCollectorBase _collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollectorBase collector) {
_collector = collector;
}
@Override
public void execute(Tuple input) {
int val = input.getInteger(0);
_collector.emit(input, new Values(val*2, val*3));
_collector.ack(input);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("double", "triple"));
}
}
The declareOutputFields function declares the output fields ["double", "triple"] for the component. The rest of the bolt will be explained in the upcoming sections.
A simple topology
Let’s take a look at a simple topology to explore the concepts more and see how the code shapes up. Let’s look at the ExclamationTopology definition from storm-starter:
// java
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("words", new TestWordSpout(), 10);
builder.setBolt("exclaim1", new ExclamationBolt(), 3).shuffleGrouping("words");
builder.setBolt("exclaim2", new ExclamationBolt(), 2).shuffleGrouping("exclaim1");
This topology contains a spout and two bolts. The spout emits words, and each bolt appends the string “!!!” to its input. The nodes are arranged in a line: the spout emits to the first bolt which then emits to the second bolt. If the spout emits the tuples “bob” and “john”, then the second bolt will emit the words “bob!!!!!!” and “john!!!!!!”.
This code defines the nodes using the setSpout and setBolt methods. These methods take as input a user-specified id, an object containing the processing logic, and the amount of parallelism you want for the node. In this example, the spout is given id “words” and the bolts are given ids “exclaim1” and “exclaim2”.
(两个方法 setSpout / setBolt ,参数的含义:node id、processing logic、amount of parallelism。)
The object containing the processing logic implements the IRichSpout interface for spouts and the IRichBolt interface for bolts. (包含processing logic的object需要实现IRichSpout/IRichBolt接口)
The last parameter, how much parallelism you want for the node, is optional. It indicates how many threads should execute that component across the cluster. If you omit it, Storm will only allocate one thread for that node. (如果不设置 amount of parallelism的,系统默认自启动一个thread)
setBolt returns an InputDeclarer object that is used to define the inputs to the Bolt. Here, component “exclaim1” declares that it wants to read all the tuples emitted by component “words” using a shuffle grouping, and component “exclaim2” declares that it wants to read all the tuples emitted by component “exclaim1” using a shuffle grouping. “shuffle grouping” means that tuples should be randomly distributed from the input tasks to the bolt’s tasks. There are many ways to group data between components. These will be explained in a few sections.
(shuffle grouping,随机分发tuple)
notes(ningg):Storm是流式处理,需要保证tuple的顺序执行吗?还有,tuple需要顺序执行吗?RE:先收到的tuple,一定是先处理的,后收到的tuple由于是不同的thread在处理,因此后收到的tuple可能先处理完。
If you wanted component “exclaim2” to read all the tuples emitted by both component “words” and component “exclaim1”, you would write component “exclaim2”’s definition like this:
(连续的使用.shuffleGrouping(),则当前bolt将读取所有shuffleGroup对应的source)
// java
builder.setBolt("exclaim2", new ExclamationBolt(), 5)
.shuffleGrouping("words")
.shuffleGrouping("exclaim1");
As you can see, input declarations can be chained to specify multiple sources for the Bolt.
(一个Bolt可以有多个输入的数据的source)
Let’s dig into the implementations of the spouts and bolts in this topology. Spouts are responsible for emitting new messages into the topology. TestWordSpout in this topology emits a random word from the list [“nathan”, “mike”, “jackson”, “golda”, “bertels”] as a 1-tuple every 100ms. The implementation of nextTuple() in TestWordSpout looks like this:
// java
public void nextTuple() {
Utils.sleep(100);
final String[] words
= new String[] {"nathan", "mike", "jackson", "golda", "bertels"};
final Random rand = new Random();
final String word = words[rand.nextInt(words.length)];
_collector.emit(new Values(word));
}
As you can see, the implementation is very straightforward.
ExclamationBolt appends the string “!!!” to its input. Let’s take a look at the full implementation for ExclamationBolt:
// java
public static class ExclamationBolt implements IRichBolt {
OutputCollector _collector;
public void prepare(Map conf, TopologyContext context,
OutputCollector collector) {
_collector = collector;
}
public void execute(Tuple tuple) {
_collector.emit(tuple, new Values(tuple.getString(0) + "!!!"));
_collector.ack(tuple);
}
public void cleanup() {
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
public Map getComponentConfiguration() {
return null;
}
}
The prepare method provides the bolt with an OutputCollector that is used for emitting tuples from this bolt. Tuples can be emitted at anytime from the bolt – in the prepare, execute, or cleanup methods, or even asynchronously in another thread. This prepare implementation simply saves the OutputCollector as an instance variable to be used later on in the execute method.
(prepare method主要目标,提供一个OutputCollector,从bolt发送tuple。)
The execute method receives a tuple from one of the bolt’s inputs. The ExclamationBolt grabs the first field from the tuple and emits a new tuple with the string “!!!” appended to it. If you implement a bolt that subscribes to multiple input sources, you can find out which component the Tuple came from by using the Tuple#getSourceComponent method.
(executemethod主要从bolt的input中获取一个tuple;如果bolt对应有多个input,则可以通过Tuple#getSourceComponent获取tuple的来源)
There’s a few other things going in in the execute method, namely that the input tuple is passed as the first argument to emit and the input tuple is acked on the final line. These are part of Storm’s reliability API for guaranteeing no data loss and will be explained later in this tutorial.
(在execute方法中,最后一行进行ack;ack机制,用于保证Storm中no data loss;在In-stream Big Data Processing 中提到过Storm的可靠性机制。)
notes(ningg):ack方法的作用?如何实现的?
The cleanup method is called when a Bolt is being shutdown and should cleanup any resources that were opened. There’s no guarantee that this method will be called on the cluster: for example, if the machine the task is running on blows up, there’s no way to invoke the method. The cleanup method is intended for when you run topologies in local mode (where a Storm cluster is simulated in process), and you want to be able to run and kill many topologies without suffering any resource leaks.
(cleanup的一个用途:local mode中运行Storm时,可以释放资源,防止资源泄漏。)
The declareOutputFields method declares that the ExclamationBolt emits 1-tuples with one field called “word”.
The getComponentConfiguration method allows you to configure various aspects of how this component runs. This is a more advanced topic that is explained further on Configuration.
(component中很多方面的属性都可进行设置)
Methods like cleanup and getComponentConfiguration are often not needed in a bolt implementation. You can define bolts more succinctly by using a base class that provides default implementations where appropriate. ExclamationBolt can be written more succinctly by extending BaseRichBolt, like so:
(通常,bolt并不需要实现cleanup和getComponentConfiguration;建议:为多个功能相似的bolt创建一个base类,然后所有的实现都继承base类)
// java
public static class ExclamationBolt extends BaseRichBolt {
OutputCollector _collector;
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
_collector = collector;
}
public void execute(Tuple tuple) {
_collector.emit(tuple, new Values(tuple.getString(0) + "!!!"));
_collector.ack(tuple);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
Running ExclamationTopology in local mode
Let’s see how to run the ExclamationTopology in local mode and see that it’s working.
Storm has two modes of operation: local mode and distributed mode. In local mode, Storm executes completely in process by simulating worker nodes with threads. Local mode is useful for testing and development of topologies. When you run the topologies in storm-starter, they’ll run in local mode and you’ll be able to see what messages each component is emitting. You can read more about running topologies in local mode on Local mode. (local mode,用于testing和development,因为,其可以查看到component:Spout、Bolt,发出的所有message)
notes(ningg):Local mode 的详细信息我还没有看。
In distributed mode, Storm operates as a cluster of machines. When you submit a topology to the master, you also submit all the code necessary to run the topology. The master will take care of distributing your code and allocating workers to run your topology. If workers go down, the master will reassign them somewhere else. You can read more about running topologies on a cluster on Running topologies on a production cluster. (distributed mode,用户需要向master提交topology,以及运行这个topology所需要的所有code,详细信息推荐阅读)
notes(ningg):Running topologies on a production cluster 是distributed mode,详细信息还没看。
Here’s the code that runs ExclamationTopology in local mode:
// java
Config conf = new Config();
conf.setDebug(true);
conf.setNumWorkers(2);
// LocalCluster:local mode
LocalCluster cluster = new LocalCluster();
cluster.submitTopology(“test”, conf, builder.createTopology());
Utils.sleep(10000);
cluster.killTopology(“test”);
cluster.shutdown();
First, the code defines an in-process cluster by creating a LocalCluster object. Submitting topologies to this virtual cluster is identical to submitting topologies to distributed clusters. It submits a topology to the LocalCluster by calling submitTopology, which takes as arguments a name for the running topology, a configuration for the topology, and then the topology itself.
(为topology指定一个唯一标识的名字)
The name is used to identify the topology so that you can kill it later on. A topology will run indefinitely until you kill it. (除非kill掉topology,否则,其永久的运行下去,因为是stream processing嘛,自然是endless)
The configuration is used to tune various aspects of the running topology. The two configurations specified here are very common: (有两个参数,重点说一下)
- TOPOLOGY_WORKERS (set with
setNumWorkers) specifies how manyprocessesyou want allocated around the cluster to execute the topology. Each component in the topology will execute as manythreads. The number of threads allocated to a given component is configured through thesetBoltandsetSpoutmethods. Those threads exist within worker processes. Eachworker processcontains within it some number of threads for some number of components. For instance, you may have 300 threads specified across all your components and 50 worker processes specified in your config. Each worker process will execute 6 threads, each of which of could belong to a different component. You tune the performance of Storm topologies by tweaking the parallelism for each component and the number of worker processes those threads should run within.(每个component:spout、bolt,都会启动几个thread,这些Thread都运行在worker process中,每个worker process都会包含来自一部分components的一些thread。) - TOPOLOGY_DEBUG (set with
setDebug), when set to true, tells Storm to log every message every emitted by a component. This is useful in local mode when testing topologies, but you probably want to keep this turned off when running topologies on the cluster.(设置Debug模式启动后,component emit的所有message都会被记录下来)
There’s many other configurations you can set for the topology. The various configurations are detailed on the Javadoc for Config. (topology对应的详细设置信息:spout、bolt、link,参考资料)
notes(ningg):worker process、thread、component之间什么关系?worker process只是作为支撑component与thread间的映射关系?
RE:简要说几点:
- component指的是spout、bolt,其中,每个spout、bolt都可设置并发执行数;
- 每个spout、bolt的每个并发都对应单个thread,这些thread构成了topology的所有threads;
- worker负责提供worker process,worker process支撑所有thread执行,可以认为所有thread均匀散布在这些worker process上;
- master、worker是物理上的机器,其分别都有自己的daemon:Nimbus、Supervisor;
- spout、bolt是逻辑上的划分,其构成topology;
To learn about how to set up your development environment so that you can run topologies in local mode (such as in Eclipse), see Creating a new Storm project。 (设置本地的开发环境,这样就可以在Eclipse等中进行调试开发)
Stream groupings
A stream grouping tells a topology how to send tuples between two components. Remember, spouts and bolts execute in parallel as many tasks across the cluster. If you look at how a topology is executing at the task level, it looks something like this: (stream grouping负责一个topology中tuples在components(Spout、Bolt)间的传递;)
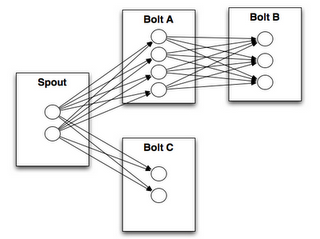
When a task for Bolt A emits a tuple to Bolt B, which task should it send the tuple to? (从Bolt A发出的tuple,发送给Bolt B的哪一个task?)
notes(ningg):tuple与task之间什么关系?此处的task本质是spout、bolt对应的thread,task获取tuple并在处理之后生产新的tuple。
A “stream grouping” answers this question by telling Storm how to send tuples between sets of tasks. Before we dig into the different kinds of stream groupings, let’s take a look at another topology from storm-starter. This WordCountTopology reads sentences off of a spout and streams out of WordCountBolt the total number of times it has seen that word before:
(stream grouping,负责分配tuple到task中去;)
// java
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(“sentences”, new RandomSentenceSpout(), 5);
builder.setBolt(“split”, new SplitSentence(), 8) .shuffleGrouping(“sentences”);
builder.setBolt(“count”, new WordCount(), 12) .fieldsGrouping(“split”, new Fields(“word”));
SplitSentence emits a tuple for each word in each sentence it receives, and WordCount keeps a map in memory from word to count. Each time WordCount receives a word, it updates its state and emits the new word count.
There’s a few different kinds of stream groupings.
The simplest kind of grouping is called a “shuffle grouping” which sends the tuple to a random task. A shuffle grouping is used in the WordCountTopology to send tuples from RandomSentenceSpout to the SplitSentence bolt. It has the effect of evenly distributing the work of processing the tuples across all of SplitSentence bolt’s tasks.
(shuffle grouping,随机分发tuple到所有的bolt)
A more interesting kind of grouping is the “fields grouping”. A fields grouping is used between the SplitSentence bolt and the WordCount bolt. It is critical for the functioning of the WordCount bolt that the same word always go to the same task. Otherwise, more than one task will see the same word, and they’ll each emit incorrect values for the count since each has incomplete information. A fields grouping lets you group a stream by a subset of its fields. This causes equal values for that subset of fields to go to the same task. Since WordCount subscribes to SplitSentence’s output stream using a fields grouping on the “word” field, the same word always goes to the same task and the bolt produces the correct output.
(fields grouping,根据给定的fields进行group操作)
notes(ningg):有个问题:参考上述WordCount类进行word的统计,实际上,每个线程共享变量,则,是否即使同一个word被发送给不同的线程,最终也能实现对word的准确计数。
Fields groupings are the basis of implementing streaming joins and streaming aggregations as well as a plethora of other use cases. Underneath the hood, fields groupings are implemented using mod hashing. (fields grouping,应用很广泛,本质上,其使用mod hashing方式实现)
There’s a few other kinds of stream groupings. You can read more about them on Concepts. (关于stream grouping的更多内容,参考Concepts)
Defining Bolts in other languages
Bolts can be defined in any language. Bolts written in another language are executed as subprocesses, and Storm communicates with those subprocesses with JSON messages over stdin/stdout. The communication protocol just requires an ~100 line adapter library, and Storm ships with adapter libraries for Ruby, Python, and Fancy. (bolt可以使用其他语言实现,本质上其他语言编写的bolt都是subprocess,Storm通过stdin/stdout上的JSON串来与其进行通讯)
Here’s the definition of the SplitSentence bolt from WordCountTopology:
// java
public static class SplitSentence extends ShellBolt implements IRichBolt {
public SplitSentence() {
super(“python”, “splitsentence.py”);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
SplitSentence overrides ShellBolt and declares it as running using python with the arguments splitsentence.py. Here’s the implementation of splitsentence.py:
// python
import storm
class SplitSentenceBolt(storm.BasicBolt):
def process(self, tup):
words = tup.values[0].split(“ “)
for word in words:
storm.emit([word])
SplitSentenceBolt().run()
For more information on writing spouts and bolts in other languages, and to learn about how to create topologies in other languages (and avoid the JVM completely), see Using non-JVM languages with Storm.
Guaranteeing message processing
Earlier on in this tutorial, we skipped over a few aspects of how tuples are emitted. Those aspects were part of Storm’s reliability API: how Storm guarantees that every message coming off a spout will be fully processed. See Guaranteeing message processing for information on how this works and what you have to do as a user to take advantage of Storm’s reliability capabilities. (本文中,并没有深入介绍how tuples are emitted,其中涉及一个关键问题:如何保证spout提供的message一定会被成功处理,详细信息可参考Guaranteeing message processing)
Transactional topologies
Storm guarantees that every message will be played through the topology at least once. A common question asked is “how do you do things like counting on top of Storm? Won’t you overcount?” Storm has a feature called transactional topologies that let you achieve exactly-once messaging semantics for most computations. Read more about transactional topologies here. (如何保证message只被处理一次,而不被重复处理?Storm提供了transactional topologies来保证只执行一次)
notes(ningg):message到底是什么?tuple?task?message就是storm中data model所指的tuple(一组field的有序排列)。
Distributed RPC
This tutorial showed how to do basic stream processing on top of Storm. There’s lots more things you can do with Storm’s primitives. One of the most interesting applications of Storm is Distributed RPC, where you parallelize the computation of intense functions on the fly. Read more about Distributed RPC here. (Distribute RPC很有意思的,能够parallelize the computation of intense functions on the fly。)
Conclusion
This tutorial gave a broad overview of developing, testing, and deploying Storm topologies. The rest of the documentation dives deeper into all the aspects of using Storm.
参考来源
原文地址:https://ningg.top/storm-tutorial/