数据库设计 3 个范式
2012-08-21
什么是范式?
为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规则。在关系型数据库中这种规则就称为范式。范式是符合某一种设计要求的总结。
常见的3个设计范式
第 1 范式
第 1 范式,列不可分,所有字段值都是不可分解的原子值。
第一范式的合理遵循需要根据系统的实际需求来定。比如某些数据库系统中需要用到“地址”这个属性,本来直接将“地址”属性设计成一个数据库表的字段就行。但是如果系统经常会访问“地址”属性中的“城市”部分,那么就非要将“地址”这个属性重新拆分为省份、城市、详细地址等多个部分进行存储,这样在对地址中某一部分操作的时候将非常方便。这样设计才算满足了数据库的第一范式,如下表所示。
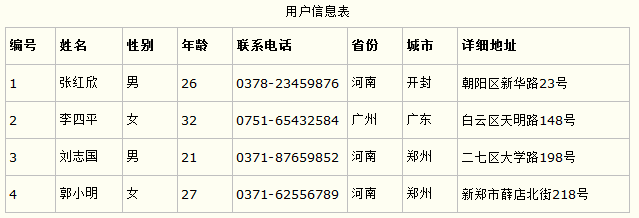
上表所示的用户信息遵循了第一范式的要求,这样在对用户使用城市进行分类的时候就非常方便,也提高了数据库的性能。
第 2 范式
第 2 范式,非主键列完全依赖主键列,每列都和主键相关,第二范式在第一范式的基础之上更进一层。第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
比如要设计一个订单信息表,因为订单中可能会有多种商品,所以要将订单编号和商品编号作为数据库表的联合主键,如下表所示。
订单信息表
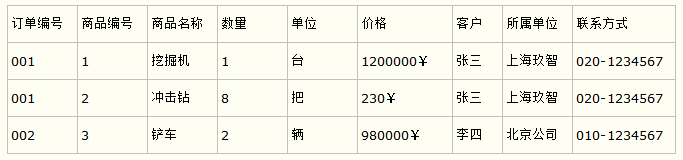
这样就产生一个问题:这个表中是以订单编号和商品编号作为联合主键。这样在该表中商品名称、单位、商品价格等信息不与该表的主键相关,而仅仅是与商品编号相关。所以在这里违反了第二范式的设计原则。将带来的问题:
- 数据冗余,每条记录中都有重复信息;
- 更新异常,修改“挖掘机”价格时,所有相关记录都要修改;
而如果把这个订单信息表进行拆分,把商品信息分离到另一个表中,把订单项目表也分离到另一个表中,就非常完美了。如下所示。(本质,对象、对象之间关系,分别单独构成一张表)
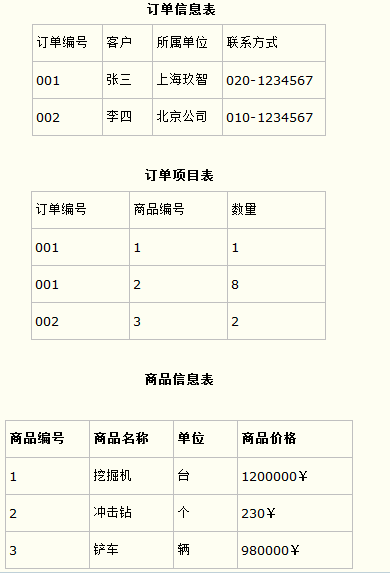
这样设计,在很大程度上减小了数据库的冗余。如果要获取订单的商品信息,使用商品编号到商品信息表中查询即可。
第 3 范式
第 3 范式,非主键列之间没有传递依赖,确保每列都和主键列直接相关,而不是间接相关。
比如在设计一个订单数据表的时候,可以将客户编号作为一个外键和订单表建立相应的关系。而不可以在订单表中添加关于客户其它信息(比如姓名、所属公司等)的字段。如下面这两个表所示的设计就是一个满足第三范式的数据库表。
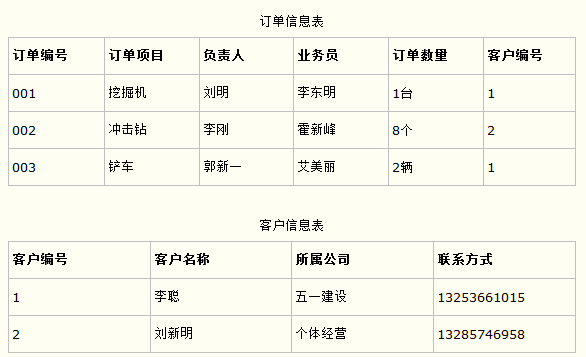
这样在查询订单信息的时候,就可以使用客户编号来引用客户信息表中的记录,也不必在订单信息表中多次输入客户信息的内容,减小了数据冗余。
不符合第三范式的例子: 学号, 姓名, 年龄, 所在学院, 学院联系电话,关键字为单一关键字”学号”; 存在依赖传递: (学号) → (所在学院) → (学院地点, 学院电话)
小结
关于关系型数据库的 3 个范式:
- 第 1 范式:列不可分,原子性;例如:地址信息,提取省份和城市。
- 第 2 范式:非主键列完全依赖主键列,一张表格只保存一类数据;例如:学生选课信息,学号、课程名称、学分,需要将课程信息(课程名称、学分)单独提取出来。
- 第 3 范式:非主键列之间不存在传递依赖,即,非主键列之间,没有相互关联关系;
个人感觉,第 2 范式与第 3 范式比较相似;
使用范式的情况:
- 范式的目标:降低数据冗余;带来的问题:副作用:查询数据时,需要进行表的连接操作;
- 表格的连接操作比较耗时,需要在数据冗余与范式之间做好权衡,通常允许一部分的数据冗余来减少表格的连接操作;
参考来源
原文地址:https://ningg.top/database-nf/