ZooKeeper 技术内幕:消息广播(Zab & Paxos)
2016-02-11
背景
ZK Follower/Observer 收到 事务请求后:
- 请求转发:
Follower/Observer将事务请求转发到Leader; - 2PC(2 phase commit,两阶段提交):
Leader向所有的Follower发送提案(Proposal)Follower将事务信息写入事务队列后, 向Leader返回 ACK 确认Leader接收到法定数量 ACK 后,提交事务请求,并向Follower/Observer广播 Commit。
具体,事务执行过程中,提案投票过程见下图:
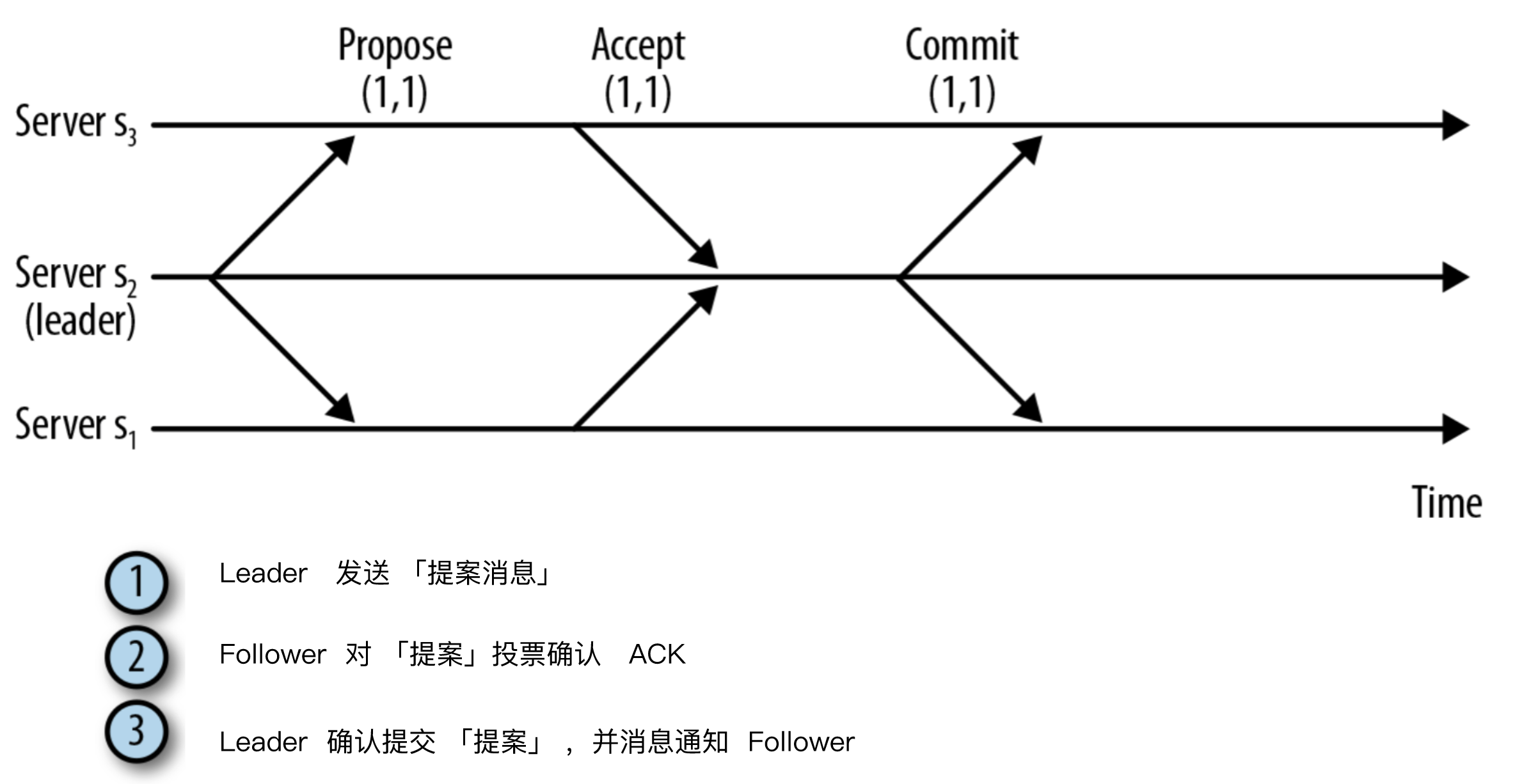
广播协议:状态更新
上述事务提交的 2PC 策略,实际是由 Zab 协议保证的:
- ZAB:ZooKeeper Atomic Broadcast protocol,ZooKeeper 原子广播协议。
- 目标:每次事务执行过程,都是
原子的,要么成功、要么失败,不存在中间状态; - ZK 中,事务执行过程中,没有
回滚机制;
ZAB 协议,具体策略:
- 事务顺序执行:Leader 确保
T1事务提交成功后,才会提交事务T2 - Follower 事务顺序执行:所有 Follower 都会先提交
T1,再提交T2
Note:ZAB 协议,允许:
- 在广播事务
T1后,提交T1前,广播事务T2;
ZAB 协议
ZK 并没有完全采用 Paxos 算法,而是采用 ZooKeeper Atomic Broadcast(ZAB, ZooKeeper原子广播协议)作为数据一致性的核心算法。
- 目标:Master-Slave 模式中,数据一致性
- 特点:支持崩溃恢复
- 不是通用的分布式一致性算法,Paxos 才是通用的分布式一致性算法
- 针对 ZooKeeper 专门设计的,支持崩溃恢复(
Leader 选举)的原子广播协议 - 具体:
- 单一进程处理事务:ZK 集群中,只有 Leader 负责处理事务请求
- ZAB 原子广播协议:Leader 将事务消息广播到 Follower 和 Observer
ZAB 协议需要保证:
- 事务广播顺序:先接收的事务,先广播
- 事务提交顺序:先接收的事务,先提交
- Follower/Observer 事务顺序:Leader 上先提交的事务,在 Follower/Observer 上也先提交
Note:
ZooKeeper 采用
提案投票策略,并等待所有的 Follower 都返回确认信息,但,仍能保证所有的 Follower 上事务执行顺序跟 Leader 保持一致.原因:Leader 跟 Follower 之间采用 TCP 长连接,广播的事务消息具有顺序性。
ZAB 协议用途
ZAB 协议应用场景:
- 崩溃恢复:Leader 选举投票
- 事务提交:提案投票
ZAB 协议,规定:事务提交过程中,是 2PC,
- 其只要求半数以上节点 ACK,就会提交事务;
- 没有要求所有的节点 ACK,因此,Leader 出现异常时,不同节点的数据不一致;
- ZAB 采用
Leader 选举的崩溃恢复策略,保证新的 Leader 上数据是最新的数据即可;
ZAB 与 Paxos 算法的对比
ZAB 协议,并不是 Paxos 算法的一个典型实现。
两者的相同之处:
- Leader、Follower 角色:都存在类似 Leader 进程,负责协调多个 Follower 进程的运行;
- 投票机制:Leader 都会等待半数以上Follower 发出 ACK 后,才会提交事务;
- Leader 纪元:对 Leader 都存在一个唯一的 epoch 值;
两者很类似,本质区别:设计目标不一样
- ZAB协议:高可用的分布式数据主备系统
- Paxos协议:分布式的一致性状态机系统
思考:what?啥区别?
补充:Paxos 的本质
Paxos 目标:解决
分布式一致性问题,提高分布式系统容错性的一致性算法。Paxos 本质:基于
消息传递的高度容错的一致性算法
分布式系统的一致性问题:
- 消息传递:延迟性,先发送的消息,不一定先到达;
- 消息传递:丢失性,发送的消息,可能丢失;
- 节点崩溃:分布式系统内,任何一个节点都可能崩溃;
在这种情况下,如何保证数据的一致性?
- 提案投票:基于投票策略,2PC
- 选举投票:基于投票策略,投出
优先级最高的节点(包含最新数据的节点)
参考资料
原文地址:https://ningg.top/zookeeper-lesson-4-zab-zookeeper-atomic-broadcast/