MySQL 技术内幕:主从同步和主从延时
2015-03-17
1. 背景
用户画像功能上线后,线上 MySQL 监控显示
主从延迟现象严重:平均 6s 左右,需要剖析一下原因,找到改进的措施。
当前 blog 要解决的问题:
- 监控:MySQL 的主从延迟?
- 影响:
- MySQL 主从延迟的影响?
- 多少的延迟,可以接受?
- 原因:MySQL 主从延迟的产生原因?
2. MySQL 主从复制
2.1. 作用
原点之问:MySQL 主从集群的作用,要解决什么问题?
场景:
高并发情况下,单台 MySQL 数据库承载的连接数多、读写压力大,MySQL系统瓶颈凸显- 大部分互联网场景,数据模型「
一写多读」- 读次数(
read_num) 一般是写次数(write_num)的 10 倍以上 - 补充:数据分析、商业智能等场景,
read_num和write_num基本相当,同一量级
- 读次数(
MySQL 集群方式,能够分散单个节点的访问压力。
MySQL 集群,常见方式:主从集群
- Master 节点,负责所有的「写请求」
- Slave 节点,负责大部分的「读请求」
MySQL 主从集群的作用:
MySQL 主从集群,分散访问压力,提升整个系统的可用性,降低大访问量引发的故障率。
常见的主从架构:
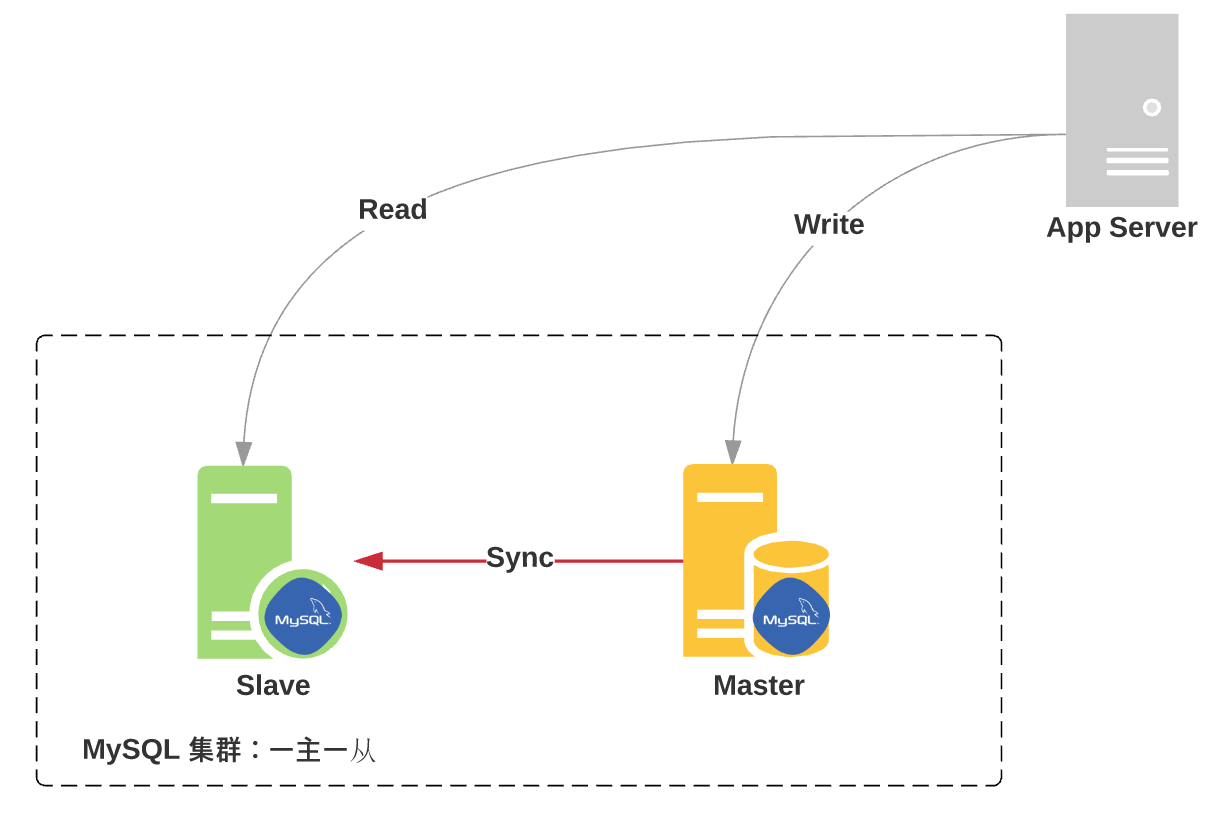
- 一主一从:一个 Master,一个 Slave
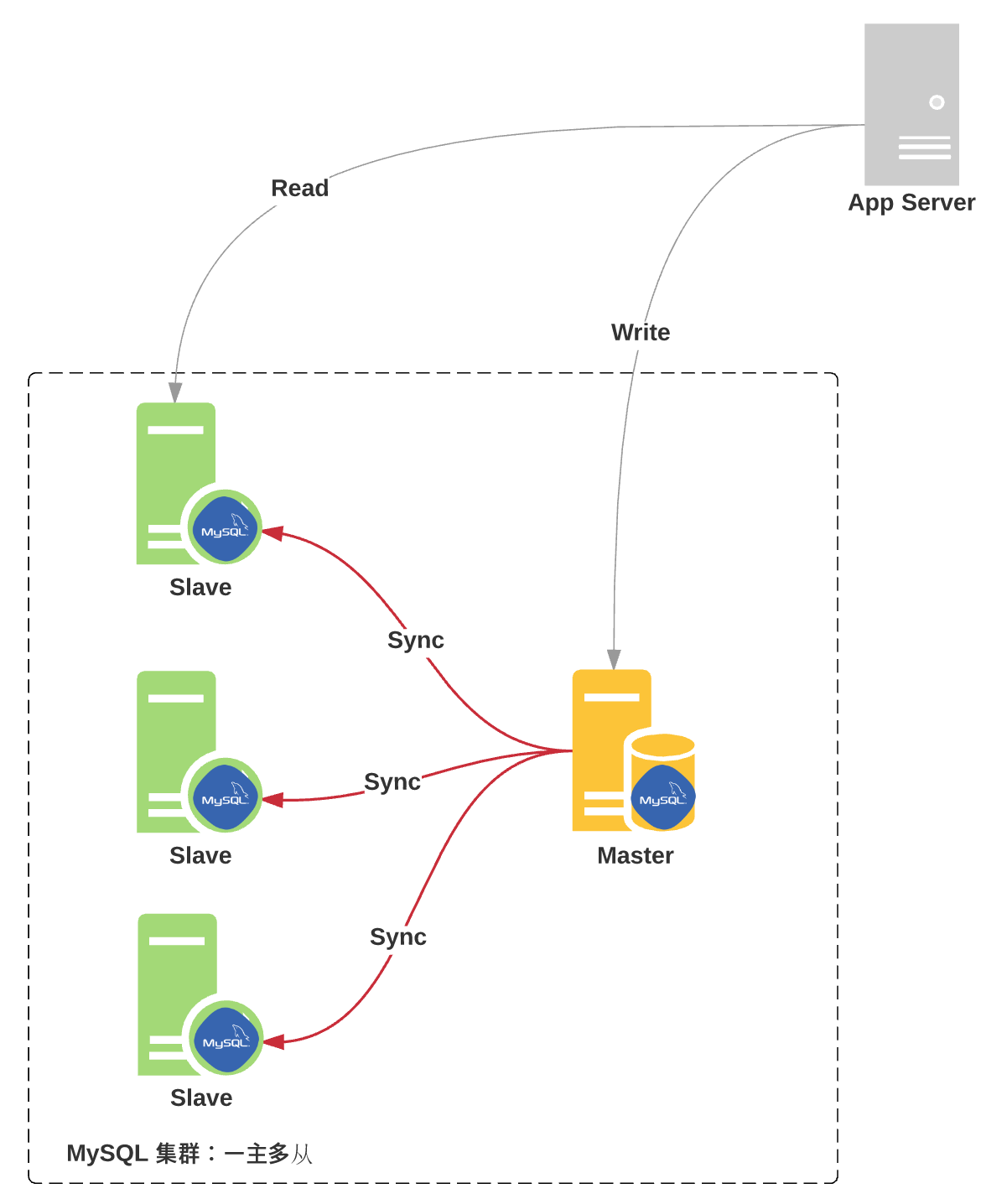
- 一主多从:一个 Master,多个 Slave
具体,参考下图:
2.2. 实现细节
MySQL 在主从同步时,其底层实现细节又是什么?为此后分析主从延迟原因以及优化方案,做好理论准备。
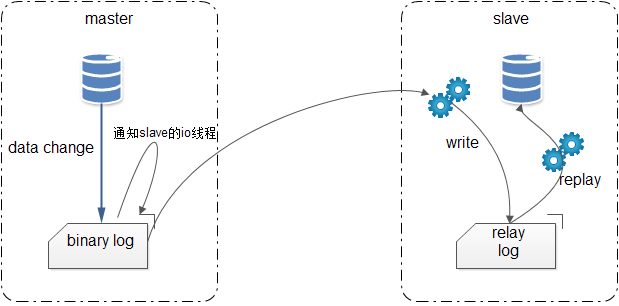
总结来说,MySQL 的主从复制:异步单线程。
Master上 1 个IO线程,负责向Slave传输binary log(binlog)Slave上 2 个线程:IO 线程和执行SQL的线程,其中:IO线程:将获取的日志信息,追加到relay log上;执行SQL的线程:检测到relay log中内容有更新,则在Slave上执行sql;
特别说明:MySQL 5.6.3 开始支持「
多线程的主从复制」,一个数据库一个线程,多个数据库可多个线程。
完整的 Master & Slave 之间主从复制过程:
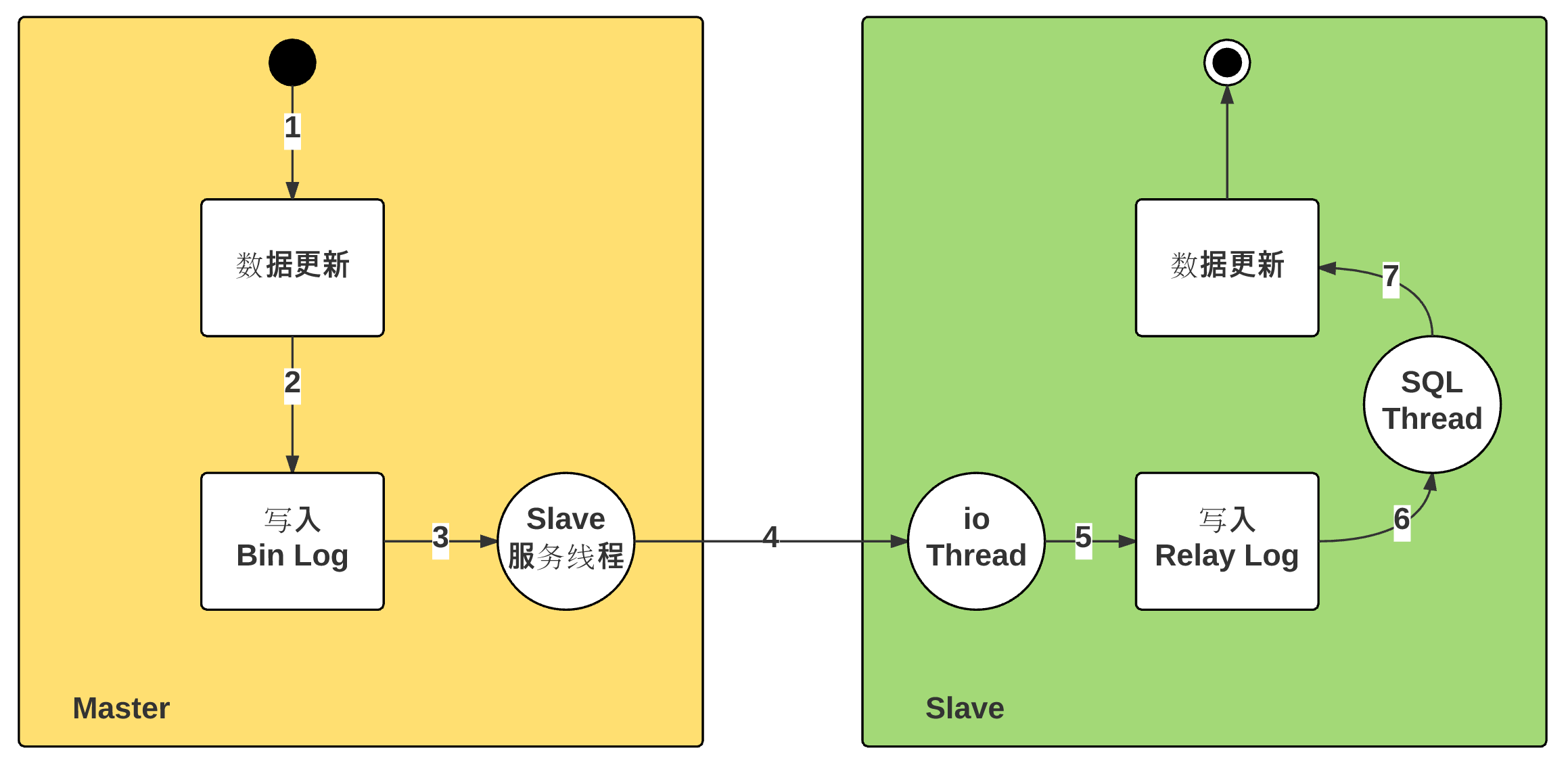
主从延时时间:Master 执行成功,到 Slave 执行成功,时间差。
上述过程:
- 主从延迟:「步骤2」开始,到「步骤7」执行结束。
- 步骤 2:存储引擎处理,时间极短
- 步骤 3:文件更新通知,磁盘读取延迟
- 步骤 4:Bin Log 文件更新的传输延迟,单线程
- 步骤 5:磁盘写入延迟
- 步骤 6:文件更新通知,磁盘读取延迟
- 步骤 7:SQL 执行时长
通过上面分析,MySQL 主从复制是典型的生产者-消费者模型:整体耗时,分为几类
- 磁盘的读写耗时:步骤 3、步骤 5、步骤6
- 网络传输耗时:步骤 4
- SQL 执行耗时:步骤 7 (地点:Slave 上 relay log 执行过程)
- 排队耗时:步骤 3(地点:Master 上 bin log 中排队,生产者-消费者)
2.3. 客观认识:主从架构
Master 数据写入后, Slave 一定要及时写入数据,这个本质是:主从架构下的强一致性。
Master 与 Slave 之间的延迟,是客观存在的。
一般对主从架构的定位:
- 提升系统的
可用行:Master 宕机后,数据不丢失,可以使用 Slave 临时替换 Master - 不要求 Slave 跟 Master 的强一致,而只要求最终一致
- 通常,对
数据一致性要求很高的场景下,并不建议采用:主从结构,分担高并发访问压力。
2.3.1. 同步复制
如果要满足主从架构的强一致性,采取「同步复制」的 2PC 策略即可:
- 第一阶段:Master 收到 Client 的写入数据请求,在本地写入数据;
- 第二阶段:Master 收到 Slave 写入成功的消息,再向 Client返回数据写入成功;
主流数据库均支持这种完全的同步模式,MySQL的Semi-sync功能(从MySQL 5.6开始官方支持),就是基于这种原理。
「同步复制」对数据库的写性能影响很大,适用场景:
银行等严格要求强一致性的应用,对于写入延迟一般没什么要求(延迟几个小时都可以接受,数据不出错就行)。
2.3.2. 异步复制
异步复制:Master 数据写入成功后,Slave 上异步进行数据写入,只要保证数据最终一致性即可。
3. 主从延迟
3.1. 如何监控
监控主从延迟的方法有多种:
- Slave 使用本机当前时间,跟 Master 上 binlog 的时间戳比较
pt-heartbeat、mt-heartbeat
本质:同一条 SQL,Master 上执行结束的时间 vs. Slave 上执行结束的时间。
3.2. 主从延迟的影响
Slave 延迟的影响:
- 异常情况下,
HA 无法切换: HA 软件需要检查数据的一致性,延迟时,主备不一致。(什么意思?) - 备库 Hang 会引发备份失败:flush tables with read lock 会 900s 超时(什么含义?)
- 以 Slave 为基准进行的备份,数据不是最新的,而是延迟的。
简单来说,恶化的主从延迟,将丧失 MySQL 集群带来的优势:
- 读写分离失效:读写分离,降低单机压力,提升系统瓶颈上限,如果延迟恶化,则失效。
- 主备容灾失效:主备切换,提升系统可用性,如果延迟恶化(1h以上),则失效。
3.3. 产生原因
常见的主从延迟原因:
- Master 上,
大事务,耗时长:优化业务,拆分为小事务- Master 上,SQL 执行速度慢:优化索引,提升索引区分度(事务内部有查询操作)
- Master 上,批量 DML 操作:建议延迟至业务低峰期操作
- Master 上,
多线程写入频繁, Slave 单线程速度跟不上:提升 Slave 硬件性能、借助中间件,改善主从复制的单线程模式
3.4. 如何解决
整体上 2 个策略,齐头并进:
- 内部解决:减弱主从复制的延迟
- 外部解决:缓存层,在前端访问和数据库之间,添加缓存,优先从缓存读取,减弱数据库的并发压力,Slave 只作为数据备份,不分担访问流量;
减弱主从延迟,采取措施:
- 细化事务:将大事务拆为小事务,不必要的地方移除事务
- 提升 SQL 执行速度:优化索引
- 减少批量操作:批量 DML 的耗时较多,减少不必要的批量 DML
- 降低
多线程大事务并发的概率:优化业务逻辑
4. 参考资料
- https://www.percona.com/
- https://www.mysql.com/
- MySQL_transfer.ppt 阿里丁奇
- http://www.cnblogs.com/lyhabc/p/3838764.html 《MySQL 技术内幕:InnoDB 存储引擎》
- http://blog.itpub.net/22664653/viewspace-775928/
- http://blog.csdn.net/jiao_fuyou/article/details/15027447
- http://database.51cto.com/art/201107/275032_all.htm MySQL 在 Master 上,先更新数据,再写 binlog
- http://blog.itpub.net/22664653/viewspace-1146808/ MySQL 中日志机制
- http://blog.csdn.net/hguisu/article/details/7325124/ 《高性能 MySQL》
原文地址:https://ningg.top/inside-mysql-master-slave-delay/