Apache Kafka 0.10 技术内幕:数据倾斜详解
2016-03-18
数据倾斜
- 数据倾斜:数据分区时,没有均分到各个区中。
- 正视数据倾斜的存在:80%的用户只使用20%的功能 , 20%的用户贡献了80%的访问量,数据也类似,因此,涉及数据分区时,应主动考虑
数据倾斜现象。
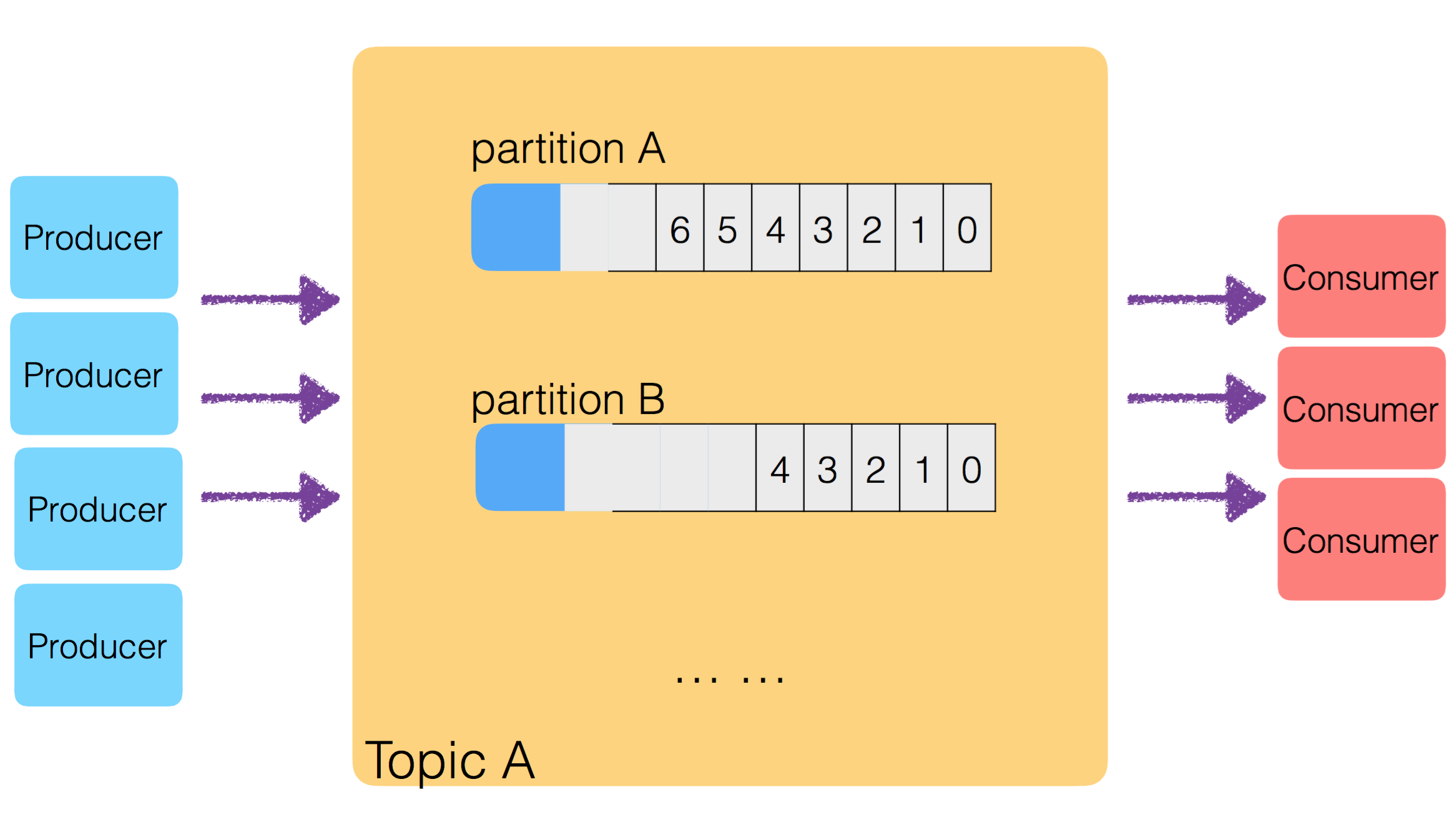
要解决数据倾斜的问题,主要从 Producer 入手,弄清楚 Producer 生成的 Msg,是如何选择传输到哪个 Partition 的。只要让 Producer 把生成的 Msg 均匀的分发到各个 Partition 中,就解决了数据倾斜问题。
Producer 产生的数据,送入哪个 Partition
自定义路由策略:
- partitioner.class:
- 指定 Class 继承 Partitioner 接口,利用 key 计算出
partition index - 默认值:
- Kafka
0.8.1-:kafka.producer.DefaultPartitioner - Kafka
0.8.2+:org.apache.kafka.clients.producer.internals.DefaultPartitioner,即,Utils.abs(key.hashCode) % numPartitions
- Kafka
- 指定 Class 继承 Partitioner 接口,利用 key 计算出
发送 msg 时,需要同时设定:key、msg:
- key 用于计算发送到哪个 partition
- key 不为 null 时,大多数处理方式都以下述方式计算
partition index=key.hashCode % numPartitions - key 为 null 时,随机选择 partition index,NOTE:此处有坑
new Java Producer API
对于 key 的取值不同,new Java Producer API 选定的 partition 不同:
- key 为 null:
轮循partition - key 为非 null:对 key 的 byte 数组进行 hash 运算,然后 numPartitions 取余
new Java Producer API,标志是:send(ProducerRecord()), 示例代码如下:
Producer<String, String> producer = new KafkaProducer(props);
for(int i = 0; i < 100; i++){
String key = Integer.toString(i);
String msg = Integer.toString(i);
producer.send(new ProducerRecord<String, String>("my-topic", key, msg));
}
producer.close();
计算 partition 的过程,源代码:
package org.apache.kafka.clients.producer.internals;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.atomic.AtomicInteger;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import org.apache.kafka.common.utils.Utils;
/**
* The default partitioning strategy:
* <ul>
* <li>If a partition is specified in the record, use it
* <li>If no partition is specified but a key is present choose a partition based on a hash of the key
* <li>If no partition or key is present choose a partition in a round-robin fashion
*/
public class DefaultPartitioner implements Partitioner {
private final AtomicInteger counter = new AtomicInteger(new Random().nextInt());
/**
* A cheap way to deterministically convert a number to a positive value. When the input is
* positive, the original value is returned. When the input number is negative, the returned
* positive value is the original value bit AND against 0x7fffffff which is not its absolutely
* value.
*
* Note: changing this method in the future will possibly cause partition selection not to be
* compatible with the existing messages already placed on a partition.
*
* @param number a given number
* @return a positive number.
*/
private static int toPositive(int number) {
return number & 0x7fffffff;
}
public void configure(Map<String, ?> configs) {}
/**
* Compute the partition for the given record.
*
* @param topic The topic name
* @param key The key to partition on (or null if no key)
* @param keyBytes serialized key to partition on (or null if no key)
* @param value The value to partition on or null
* @param valueBytes serialized value to partition on or null
* @param cluster The current cluster metadata
*/
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
int nextValue = counter.getAndIncrement();
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = DefaultPartitioner.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return DefaultPartitioner.toPositive(nextValue) % numPartitions;
}
} else {
// hash the keyBytes to choose a partition
return DefaultPartitioner.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
public void close() {}
}
legacy Scala Producer API
对于 key 的取值不同,legacy Scala Producer API 选定的 partition 不同:
- key 为 null:随机一个
partition index,缓存起来,缓存期间,所有 key 为 null 的 msg 都发送到同一个 partition,每 10 mins 清除一次缓存 ,随机下一个 partition,并再次缓存 - key 为非 null:对 key 的 byte 数组进行 hash 运算,然后 numPartitions 取余
legacy Scala Producer API,标志是:send(KeyedMessage()), 示例代码如下:
import java.util.*;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
public class TestProducer {
public static void main(String[] args) {
long events = Long.parseLong(args[0]);
Random rnd = new Random();
Properties props = new Properties();
props.put("metadata.broker.list", "broker1:9092,broker2:9092 ");
props.put("serializer.class", "kafka.serializer.StringEncoder");
// 定制的Partitioner,处理 key -- partition 之间的映射关系
props.put("partitioner.class", "example.producer.SimplePartitioner");
props.put("request.required.acks", "1");
ProducerConfig config = new ProducerConfig(props);
Producer<String, String> producer = new Producer<String, String>(config);
for (long nEvents = 0; nEvents < events; nEvents++) {
long runtime = new Date().getTime();
String ip = “192.168.2.” + rnd.nextInt(255);
String msg = runtime + “,www.example.com,” + ip;
KeyedMessage<String, String> data = new KeyedMessage<String, String>("page_visits", ip, msg);
producer.send(data);
}
producer.close();
}
}
计算 partition 的过程,源代码:
class DefaultEventHandler[K,V]
...
if (topicMetadataRefreshInterval >= 0 &&
SystemTime.milliseconds - lastTopicMetadataRefreshTime > topicMetadataRefreshInterval) {
...
sendPartitionPerTopicCache.clear()
...
lastTopicMetadataRefreshTime = SystemTime.milliseconds
}
....
/**
* Retrieves the partition id and throws an UnknownTopicOrPartitionException if
* the value of partition is not between 0 and numPartitions-1
* @param topic The topic
* @param key the partition key
* @param topicPartitionList the list of available partitions
* @return the partition id
*/
private def getPartition(topic: String, key: Any, topicPartitionList: Seq[PartitionAndLeader]): Int = {
val numPartitions = topicPartitionList.size
if(numPartitions <= 0)
throw new UnknownTopicOrPartitionException("Topic " + topic + " doesn't exist")
val partition =
if(key == null) {
// If the key is null, we don't really need a partitioner
// So we look up in the send partition cache for the topic to decide the target partition
val id = sendPartitionPerTopicCache.get(topic)
id match {
case Some(partitionId) =>
// directly return the partitionId without checking availability of the leader,
// since we want to postpone the failure until the send operation anyways
partitionId
case None =>
val availablePartitions = topicPartitionList.filter(_.leaderBrokerIdOpt.isDefined)
if (availablePartitions.isEmpty)
throw new LeaderNotAvailableException("No leader for any partition in topic " + topic)
val index = Utils.abs(Random.nextInt) % availablePartitions.size
val partitionId = availablePartitions(index).partitionId
sendPartitionPerTopicCache.put(topic, partitionId)
partitionId
}
} else
partitioner.partition(key, numPartitions)
if(partition < 0 || partition >= numPartitions)
throw new UnknownTopicOrPartitionException("Invalid partition id: " + partition + " for topic " + topic +
"; Valid values are in the inclusive range of [0, " + (numPartitions-1) + "]")
trace("Assigning message of topic %s and key %s to a selected partition %d".format(topic, if (key == null) "[none]" else key.toString, partition))
partition
}
....
特别说明:
- key 为 null 时,legacy Scala Producer API 将随机计算一个 partition index,然后缓存到 sendPartitionPerTopicCache,下次还用这个 partition index.
- 到源代码中,详细阅读 DefaultEventHandler 类,其中,描述了清除 sendPartitionPerTopicCache 缓存的条件:间隔
topic.metadata.refresh.interval.ms,会清除一次,默认:600000 ms. - Kafka 为什么采取上述策略?为了减少 broker 的socket 数量,节省socket 资源,参考:邮件列表
- 数据量大、并且持续不断时,使用 legacy Scala Producer API 并且 key 为 null,此时,数据倾斜现象不明显.
- 建议:使用 legacy Scala Producer API,一定要设置 key.
key 为 null 时,msg 发送到哪个 Partition
简单回答一下「key 为 null 时,msg 发送到哪个 Partition」答案是:跟使用的 Producer API 有关:
new Java Producer API:轮循,round-robin,每次换一个 partitionlegacy Scala Producer API:随机一个 partition index,并且缓存起来,每 10 mins 清除一次缓存 ,随机下一个 partition index,并再次缓存
特别说明:
new Java Producer API,从 Kafka 0.8.2.x 开始引入,但后续版本中,仍然保留 legacy Scala Producer API
最佳实践建议
为了最大程度减弱数据倾斜现象,最佳策略:
- Producer 发送 msg 时,设置 key
- 对 key 没有特殊要求时,建议设置 key 为随机数
参考资料
- Kafka 官网
- https://cwiki.apache.org/confluence/display/KAFKA/0.8.0+Producer+Example Kafka 0.8.1版本以下,Producer API 的示例
- https://cwiki.apache.org/confluence/display/KAFKA/Consumer+Group+Example High Level Consumer API 示例 (offset 未及时提交到 zookeeper 导致数据重复消费)
- https://cwiki.apache.org/confluence/display/KAFKA/0.8.0+SimpleConsumer+Example Simple Consumer API
- http://kafka.apache.org/082/documentation.html Kafka 0.8.2 版本文档
- https://cwiki.apache.org/confluence/display/KAFKA/FAQ
- http://stackoverflow.com/q/25896109
- http://stackoverflow.com/a/30650787
- http://www.confluent.io/blog/whats-coming-in-apache-kafka-0-8-2/
- Kafka 0.9.0 源码
原文地址:https://ningg.top/apache-kafka-10-best-practice-tips-data-skew-details/