Apache Kafka 实践:消息分发语义
2017-08-17
1.概要
实际场景中,大家总会疑惑:
- Kafka 到底怎么样?
- 能用到生产环境吗?
- 会不会重复发送数据?
- 会不会丢失数据?
本文,重点讨论:Kafka 会不会重复发送数据?又会不会丢数据?如果数据已经存储到 Kafka Cluster 中,在磁盘中存储的数据,是否会平白无故的丢失?或则平白无故的重复?
2.结论
针对上述疑问,逐个先回答一下结论:
1.Kafka 会不会重复发送数据?
Re:会,消息传送的整个链路 Producer → Kafka → Consumer,极低概率会出现消息的重复发送。
2.从 Kafka Cluster 自身角度,会不会丢数据?
Re:不会,如果数据存入了 Kafka,不会平白无故的丢失,就如果你电脑上的文件一样,除非磁盘坏掉,文件始终存在;实际上 Kafka 集群,多副本分布在不同机器上,仅当所有副本的机器都出现故障,才会出现数据丢失,此时,机器早已报警。
3.如果数据已经存储到 Kafka Cluster 中,在磁盘中存储的数据,是否会平白无故的丢失?或则平白无故的重复?
Re:不会,Kafka Cluster 数据持久化在磁盘中,磁盘上 OS 暴露给我们的是文件,OS 的文件系统会保证,文件不会平白无故的丢失或者重复;OS 向应用屏蔽这个细节。
4.Consumer 从 Kafka 集群消费数据,是否会出现批量数据丢失?
Re:会,仅当 Consumer 使用默认配置,并且 Consumer 长时间宕机重启后,Consumer 会主动丢弃,本质是 Kafka 的消费方,使用经验不足导致。
最佳实践建议:
- Consumer 主动配置 ‘auto.offset.reset’,尽量避免其默认值
- Kafka 的 Borker 根据业务场景,合理调整参数:log.retention.ms > log.retention.minutes > log.retention.hours (默认 168h ,7天)
- 根据业务场景,调整 Producer 的配置参数 ‘acks’ ,绝大多数场景,都不需要调整 ‘acks’. (订单等核心数据,建议调整)
详细的分析,看下文。
3.分析
3.1.Kafka 的消息分发语义
通常,消息中间件,提供的分发语义,分为 3 个层次:
- 至多一次,At most once—Messages may be lost but are never redelivered.
- 至少一次,At least once—Messages are never lost but may be redelivered.
- 精确一次,Exactly once—this is what people actually want, each message is delivered once and only once.
关于 Kafka 提供的消息分发语义,细节参考:http://kafka.apache.org/documentation/#semantics, 下面整理几个要点:
- Producer 侧,消息可能重复:Producer 发送消息到 Kafka,Kafka 的 ACK 消息丢失,Producer 会重复发送消息
- Consumer 侧,消息可能重复:Consumer 消费数据后,需要 Consumer 更新 offset,Consumer 出于效率考虑,会批量更新 offset,即,消费多条消息,才会更新 offset,但在更新 offset 时,可能会出现 offset 更新失败,此时,Consumer 重启后,会重复消费。
结论:
Kafka 通常情况提供
至少分发一次(At least once)的语义,即,使用 Kafka 分发消息,消息不会丢失,极低概率有可能出现重复。
Note:Kafka 的 0.11+ 版本,Kafka 开始在特定的 Producer 和 Consumer 提供「精确一次」的分发语义,即,Producer\Consumer 侧,消息既不会丢失、也不会重复。底层原理:
- 每个 Producer 分配一个唯一 ID,每个消息分配一个序列号;Kafka 集群以此判断消息是否重复。
- 每个 Consumer,将消息产生的结果和 offset 在一个事务中保存,借助外部存储;如果消息产生的效果更新失败,则 offset 也会丢弃;只要消息产生的效果成功保存,则 offset 成功保存。
3.2.Leader 和 Follower 数据一致性
Kafka Cluster,本质是 Broker Cluster:
- 每个 Topic 划分为多个 Partition
- 每个 Broker 承载多个 Partition
- 每个 Partition 有多个 Replica
- Replica 的角色分为 Leader 和 Follower
Leader 和 Follower 之间数据一致性,本质:Producer 生产的消息,发送到 Kafka 之后,是同步写入、半同步写入,还是异步写入?具体可以在 Producer 侧设置。
- 同步写入:Leader 和所有 Follower 都 commit 数据,Leader 才向 Producer 返回 ACK;
- 半同步写入:Leader 和部分 Follower 都 commit 数据
- 异步写入:只有 Leader commit 数据
如果采用「完全异步写入」,消息写入 Leader 之后,极端情况 Leader 宕机,则,会丢失几条数据。
如何设置,Leader 和 Follower 之间数据一致性的级别?
- Producer 侧,配置参数 ‘acks’,默认为
1,表示「异步写入」,但是 Leader 已经写入到本地 log 中; - 更多细节:http://kafka.apache.org/documentation/#producerconfigs
结论:
Producer 侧,设置的 acks 参数为 1 时,在极端情况下,会出现少量数据丢失。此时,在 leader 选举次数上,能够反映出来。
3.3.Consumer 主动丢弃数据
前文分析了,数据一旦送入 Kafka 集群,就不会丢失,只有在 Producer 的特殊配置情况下,才有可能出现极小概率的少量数据丢失。
但是,是否有可能出现,大量数据丢失呢?
Re:有可能出现,并且,只有一种情况:Consumer 主动丢弃数据。
特别说明:
默认的 Consumer 配置,会出现上述情况(Consumer侧,主动的批量丢弃数据),需要调整 Consumer 的配置,避免出现上述情况。
Kafka 的 Consumer 有 2 类:
- Old Consumer :老版本 Consumer,scala 代码实现, 配置类为 kafka.consumer.ConsumerConfig,依赖 ZK 保存 offset,需要配置参数 ‘zookeeper.connect’
- New Consumer :新版本 Consumer,Java 代码实现;
其中,都有一个配置参数 auto.offset.reset,含义如下:
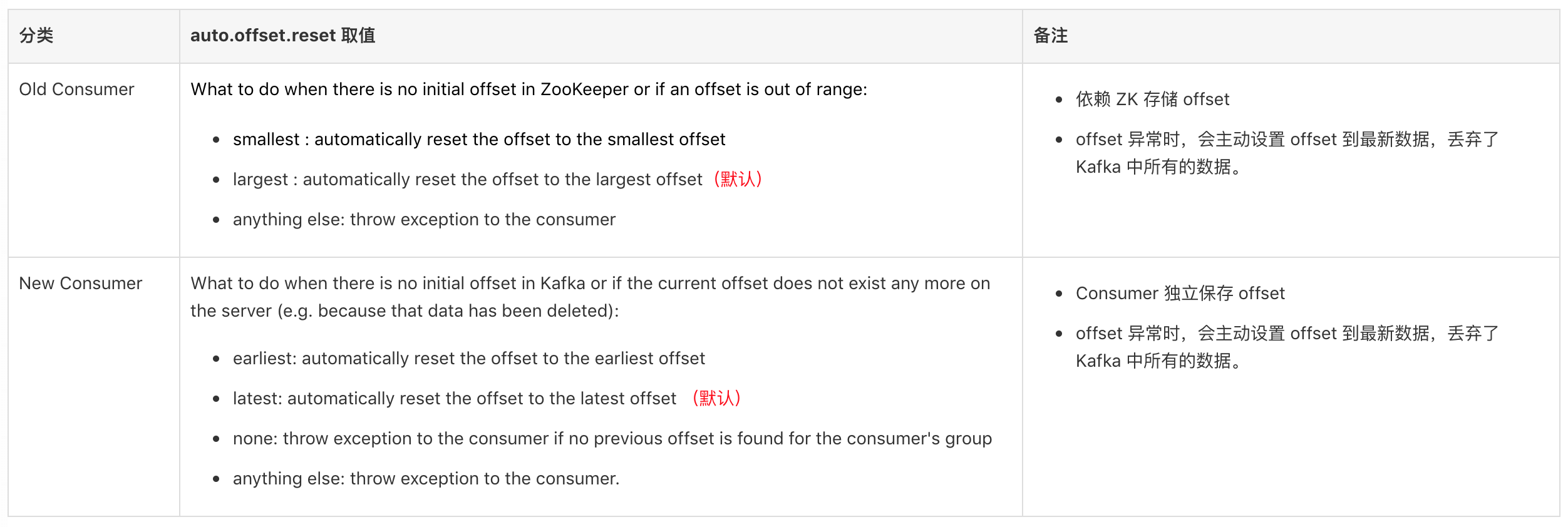
结论:
Consumer 的默认配置中,当 offset 异常时,会主动丢弃 Kafka 中大量数据,从 offset 最大值开始读取数据。
offset 异常的情况:
Consumer 宕机时间过长,Kafka 只保留一段时间的 offset,默认保留 7 天的数据,以及这些数据对应的 offset;
Broker 上设置数据保留时长的参数 ‘log.retention.ms’,默认为 7 天;
如果 Consumer 宕机超过 7 天,Consumer 重启后,会主动丢弃大量数据。
补充说明:Kafka 0.10.1 版本,配置参数:
log.retention.ms > log.retention.minutes > log.retention.hours (默认 168h ,7天)
log.retention.bytes
实践建议:
- Consumer 侧,设置 ‘auto.offset.reset’ 为
none - 当 offset 异常时,需要人工介入分析,而不是程序自动丢弃 Kafka 中已存的大量数据
- 如果能够在 Consumer 侧,实现消息消费的幂等,则,设置 ‘auto.offset.reset’ 为
smallest/earliest.
当前 Kafka 集群配置:
- 当前 Kafka 集群配置数据保留时长:1 天。
4.参考资料
- Kafka: a Distributed Messaging System for Log Processing,NetDB’11, Jun. 12, 2011, Athens, Greece.
- http://kafka.apache.org/documentation Kafka 0.11.x
- http://kafka.apache.org/0101/documentation.html Kafka 0.10.1
原文地址:https://ningg.top/apache-kafka-practice-msg-delivery-semantics/