Storm 0.9.2:如何从Kafka读取数据
2014-10-31
背景
之前研读了In-Stream Big Data Processing,组里将基于此实现一个实时的数据分析系统,基本选定三个组件:Flume、Kafka、Storm,其中,Flume负责数据采集,Kafka是一个MQ:负责数据采集与数据分析之间解耦,Storm负责进行流式处理。
把这3个东西串起来,可以吗?可以的,之前整理了Flume与Kafka整合的文章,那Storm能够与Kafka整合吗?Storm官网有介绍: Storm Integrates,其中给出了Storm与Kafka集成的方案。
回顾Storm
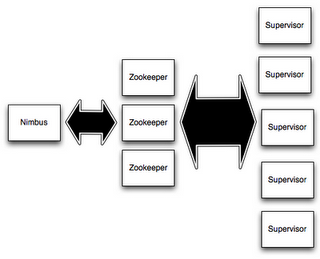
之前都是以原文+注释方式,来阅读Storm的官方文档,现在集中整理一下。Storm集群的构成:
- 包含两种节点:master和worker;
- master上运行
Nimbus,负责:distribute code、assign task、monitor failutes; - worker上运行
Supervisor,负责:监听Nimbus分配的任务,并启停worker precess; - zookeeper负责协调
Nimbus和Supervisor之间的关系,所有状态信息都存储在zookeeper or local host;因此,重启Nimbus or Supervisor进程,对用户来说无影响;
关于 spout 和 bolt ,说几点:
- spout(龙卷风、气旋): source of stream,向topology中拉入数据的原点;
- bolt(闪电):处理 stream,通过run functions、filter tuples、do streaming aggregations、do streaming join、talk to database… 来做任何事情;
- topology:由spout、bolt以及他们之间的关系构成,是client提交给Storm cluster执行的基本单元;
- topology中所有node都是并发运行的,可以配置每个node的并发数;
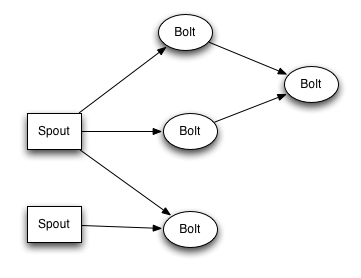
notes(ningg):topology中node是什么概念?spout、bolt?master、worker?jvm process?thread? RE:master、worker对应Storm的node,master负责控制,worker负责具体执行;spout、bolt是逻辑上的,并且分布在不同的worker上;每个spout、bolt可配置并发数,这个并发数对应启动的thread;不同的spout、bolt对应不同的thread,thread间不能共用;这些所有的thread由所有的worker process来执行,举例,累计300个thread,启动了30个worker,则平均每个worker process对应执行10个thread(前面的说法对吗?哈哈)
关于数据模型,即数据的结构,说几点:
- Storm中,使用tuple结构来存储数据,tuple由fields构成,field可以为任意类型;
- topology中spout、bolt必须声明其emit的tuple格式:
declareOutputFields(); setSpout/setBolt用于定义spout和bolt,输入参数:node id、processing logic、amount of parallelism;- processing logic对应类spout/bolt,需要implement
IRichSpout/IRichBolt;
Storm有两种执行模式,local mode和distributed mode,补充几点:
- local mode,在本地的process中通过thread模拟worker,多用于testing和development topology;更多参考资料;
- distributed mode,用户向master提交topology以及运行topology所需的所有code;master向worker分发topology;更多参考资料;
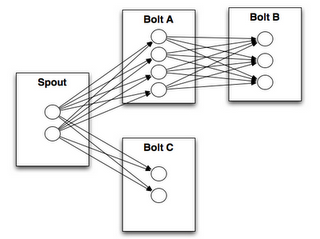
关于Stream groupings,几点:
* stream grouping解决的问题:多个执行spout逻辑的thread都输出tuple,这些tuple要发送给bolt对应的多个thread,问题来了,tuple发给bolt的哪个thread?即,stream grouping解决:tuple在不同task之间传递关系; * shuffle grouping,随机分发;field grouping,根据给定的field进行分发;更多参考;
Strom整合Kafka
版本信息
Storm与Kafka的版本信息:
- Storm:apache-storm-0.9.2-incubating
- Kafka:kafka_2.9.2-0.8.1.1.tgz
基础知识
实现Storm读取Kafka中的数据,参考官网介绍, 本部分主要参考自storm-kafka的README。
Strom从Kafka中读取数据,本质:实现一个Storm中的Spout,来读取Kafka中的数据;这个Spout,可以称为Kafka Spout。实现一个Kafka Spout有两条路:
- core storm spout;
- Trident spout;
无论用哪种方式实现Kafka Spout,都分为两步走:
- 实现BrokerHost接口:用于记录Kafka broker host与partition之间的映射关系;具体两种实现方式:
- ZkHosts类:从zookeeper中动态的获取kafka broker与partition之间的映射关系;初始化时,需要配置zookeeper的
ip:port;默认,每60s从zookeeper中请求一次映射关系; - StaticHosts类:当broker–partition之间的映射关系是静态时,常使用此方法;
- ZkHosts类:从zookeeper中动态的获取kafka broker与partition之间的映射关系;初始化时,需要配置zookeeper的
- 继承KafkaConfig类:用于存储Kafka相关的参数;将上面实例的BrokerHost对象,作为参数传入KafkaConfig,例,Kafka的一个构造方法为
KafkaConfig(BrokerHosts hosts, String topic);当前其实现方式有两个:- SpoutConfig:Core KafkaSpout只接受此配置方式;
- TridentKafkaConfig:TridentKafkaEmitter只接受此配置方式;
KafkaConfig类中涉及到的配置参数默认值如下:
public int fetchSizeBytes = 1024 * 1024;
public int socketTimeoutMs = 10000;
public int fetchMaxWait = 10000;
public int bufferSizeBytes = 1024 * 1024;
public MultiScheme scheme = new RawMultiScheme();
public boolean forceFromStart = false;
public long startOffsetTime = kafka.api.OffsetRequest.EarliestTime();
public long maxOffsetBehind = Long.MAX_VALUE;
public boolean useStartOffsetTimeIfOffsetOutOfRange = true;
public int metricsTimeBucketSizeInSecs = 60;
上面的MultiScheme类型的参数shceme,其负责:将Kafka中取出的byte[]转换为storm所需的tuple,这是一个扩展点,默认是原文输出。两种实现:SchemeAsMultiScheme和KeyValueSchemeAsMultiScheme可将读取的byte[]转换为String。
notes(ningg):几个疑问,列在下面了
ZkHosts类的一个构造方法ZkHosts(String brokerZkStr, String brokerZkPath),其中brokerZkPath的含义,原始给出的说法是:”rokerZkPath is the root directory under which all the topics and partition information is stored. by Default this is/brokerswhich is what default kafka implementation uses.”SpoutConfig(BrokerHosts hosts, String topic, String zkRoot, String id),其中,zkRoot是一个root目录,用于存储consumer的offset;那这个zkRoot对应的目录物理上在哪台机器?
配置实例
Core Kafka Spout
本质是设置一个读取Kafka中数据的Kafka Spout,然后,将从替换原始local mode下,topology中的Spout即可。下面是一个已经验证过的实例
TopologyBuilder builder = new TopologyBuilder();
BrokerHosts hosts = new ZkHosts("121.7.2.12:2181");
SpoutConfig spoutConfig = new SpoutConfig(hosts, "ningg", "/" + "ningg", UUID.randomUUID().toString());
spoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
KafkaSpout kafkaSpout = new KafkaSpout(spoutConfig);
// set Spout.
builder.setSpout("word", kafkaSpout, 3);
builder.setBolt("result", new ExclamationBolt(), 3).shuffleGrouping("word");
Config conf = new Config();
conf.setDebug(true);
// submit topology in local mode
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("test", conf, builder.createTopology());
Trident Kafka Spout(todo)
todo
下面的样例并还没验证:
TridentTopology topology = new TridentTopology();
BrokerHosts zk = new ZkHosts("localhost");
TridentKafkaConfig spoutConf = new TridentKafkaConfig(zk, "test-topic");
spoutConf.scheme = new SchemeAsMultiScheme(new StringScheme());
OpaqueTridentKafkaSpout spout = new OpaqueTridentKafkaSpout(spoutConf);
参考来源
原文地址:https://ningg.top/storm-with-kafka/