AI 系列:Models
2023-10-28
原文:Models
Work in Progress
This chapter is still being written & reviewed. Please do post links & discussion in the comments below, or open a pull request!
Some ideas:
-
The History of Open-Source LLMs: Better Base Models (part 2) (LLaMA, MPT, Falcon, LLaMA-2)
-
Papers I’ve read this week, Mixture of Experts edition (conditional routing models)
-
end of open source AI [14]
-
futures section in Survey of LLMs [90]
-
Human/GPT-4 evals
-
RLHF vs RLAIF?
The emergence of Large Language Models, notably with the advent of GPT-3, ChatGPT, Midjourney, Whisper helped bloom a new era. Beyond revolutionising just language models, these models also pushed innovation in other domains like Vision (ViT, DALL-E, Stable Diffusion SAM, etc), Audio Wave2vec [91], Bark) or even Multimodal models.
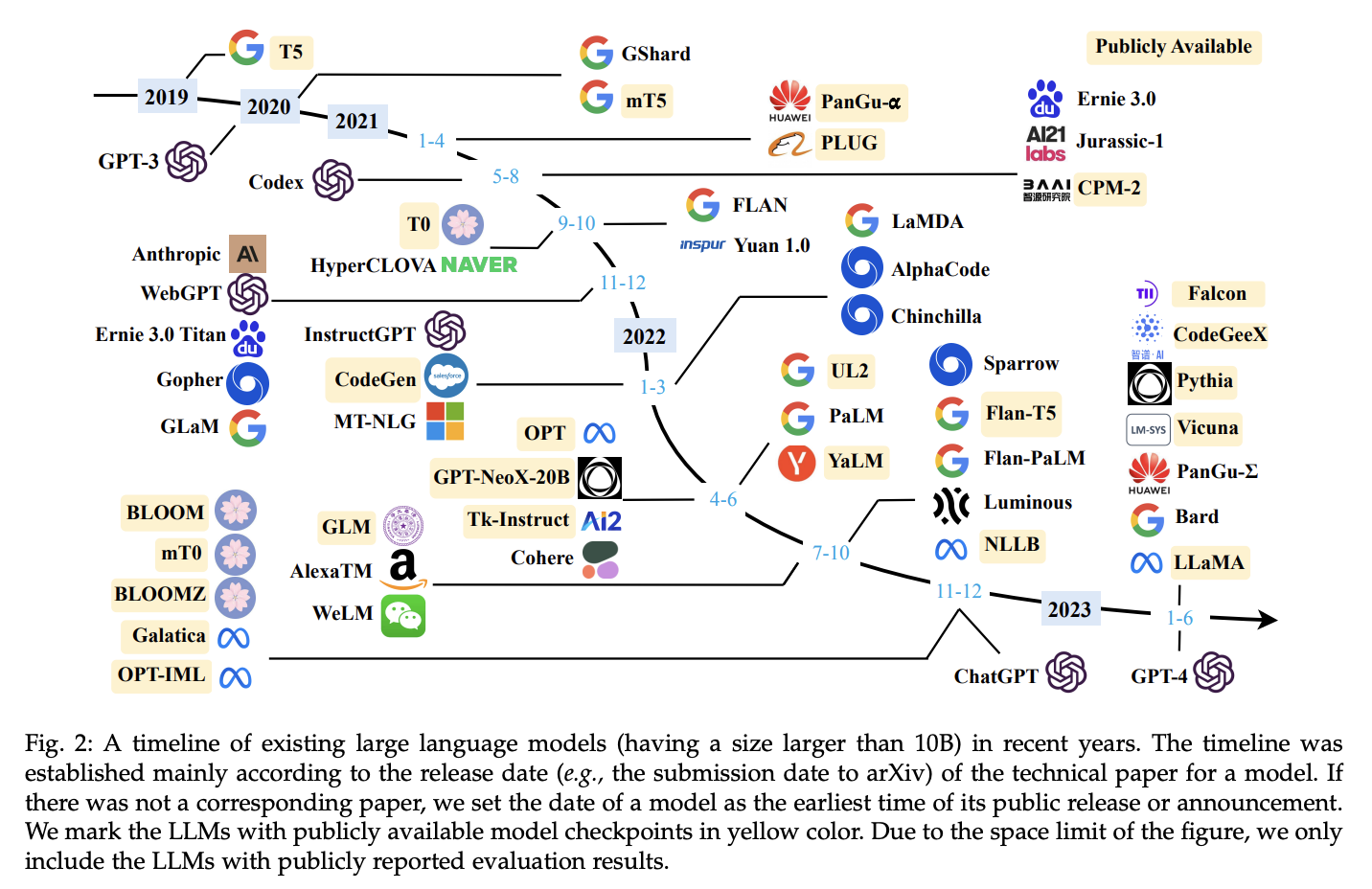
Fig. 27 Page 7, A Survey of Large Language Models [90]#
1.Proprietary Models 专有模型#
1.1.Text#
For performance comparisons, Chatbot Arena helps (though it’s a bit old and doesn’t reflect latest results).
PaLM-2#
PaLM-2是谷歌的下一代大型语言模型,经过深度训练,包括100多种语言的多语言文本。
PaLM-2在高级推理、翻译和代码生成等任务方面也表现出色。与其前身PaLM相比,PaLM-2体积更小,但效率更高,性能更出色,包括更快的推理速度、更少的参数供服务和更低的服务成本。
PaLM-2在某些领域的推理任务方面表现出比OpenAI的GPT-4更强的结果。PaLM-2的多语言能力使其能够理解来自各种语言的成语、谜语和影射文本。此外,PaLM-2具有快速响应的优势,可以一次提供三个响应。他们还发布了一篇论文,提供更多详细信息。
ChatGPT#
ChatGPT is a language model developed by OpenAI. It is fine-tuned from a model in the GPT-3.5 series and was trained on an Azure AI supercomputing infrastructure. ChatGPT is designed for conversational AI applications, such as chatbots and virtual assistants.
ChatGPT is sensitive to tweaks to the input phrasing or attempting the same prompt multiple times. It’s still not fully reliable and can “hallucinate” facts and make reasoning errors.
GPT-4#
GPT-4 is a language model developed by OpenAI. It is the successor to GPT-3 and has been made publicly available via the paid chatbot product ChatGPT Plus and via OpenAI’s API.
它是一款多模态模型,可以接受图像和文本输入,并输出文本输出,尽管多模态能力尚未向公众发布。
它在各种专业和学术基准上表现出与人类水平相当的性能,可以遵循自然语言中的复杂指令,并以高准确度解决困难问题。
它可以处理长达 32k 个标记的输入提示,这相比于GPT-3.5的 4k 个标记有了显著增加。
它可以解决比GPT-3.5更复杂的数学和科学问题,例如高级微积分问题,或者比其前身更有效地模拟化学反应。它更可靠、富有创造力,能够处理比GPT-3.5更加微妙的指令。
Despite its capabilities, GPT-4 still sometimes “hallucinates” facts and makes reasoning errors.
Claude#
Claude 2 是由Anthropic开发的一款语言模型。它于2023年7月11日宣布推出,与其前身Claude相比,具有更好的性能和更长的回应,用户可以通过API和他们的网站访问它。
据Anthropic称,用户发现与Claude进行对话很容易,它能清晰地解释其思维过程,不太可能产生有害的输出,而且具有更长的记忆。在编码、数学和推理方面进行了改进,相对于以前的模型有了提高。
1.2.Audio#
StableAudio#
StableAudio is a proprietary model developed by Stability AI. It is designed to improve the accuracy of audio processing tasks, such as speech recognition and speaker identification.
1.3.Vision#
Midjourney#
Midjourney is a proprietary model for Image generation developed by Midjourney.
2.Open-Source Models#
Note: “Open source” does not necessarily mean “open licence”.
| Subsection | Description |
|---|---|
| Before Public Awareness | Pre-ChatGPT; before widespread LLMs use, and a time of slow progress. |
| Early Models | Post-ChatGPT; time of Stable Diffusion and LLaMA |
| Current Models | Post-LLaMA leak; open-source LLMs quickly catching up to closed-source, new solutions emerging (e.g. GPU-poor), Alpaca 7B, LLaMA variants, etc. |
如果把这个情景看作是大型语言模型(LLMs)如何快速改进的故事,ChatGPT将发挥重要作用。
早期性能出色的LLMs都是专有的,只能通过组织的付费API访问,这限制了透明度,引发了关于数据隐私、偏见、模型对齐和鲁棒性的担忧,使得满足特定领域用例的可能性受到限制,而不受 RLHF 对齐(alignment)的干扰。
2.1.Before Public Awareness#
认识到需要开放性,LLM研究社区做出了回应,创建了开源变种,奠定了提高透明度和开发更强大模型的基础。
There has been few notable open LLMs pre-ChatGPT era like BLOOM, GPT-NewX 20B [93], GPT-J 6B, OPT [94].
GPT-J 6B#
GPT-J 6B is an early English-only casual language model, which at the time of its release was the largest publicly available GPT-3 style language model. Code and weights are open sourced along with a blog by Aran Komatsuzaki, one of the authors of the model.
Uniqueness#
-
It belongs to the GPT-J class of models, and has 6 billion trainable parameters.
-
Uses same tokeniser as GPT-2/3.
-
Uses Rotary Position Embedding (RoPE) [95]
-
Used open sourced dataset for training – Pile [96], a large scale dataset curated by EleutherAI.
-
The dimension of each attention head is set to 256, which is twice larger than that of GPT-3 of comparable size, which improved throughput with minimal performance degradation.
-
Places the attention layer and the feed-forward layer in parallel for decreased communication.
Limitations#
-
It’s trained on an English-only dataset.
-
The Pile [96] dataset which was used for training is known to contain profanity, lewd and abrasive language too.
Before ChatGPT‘s (GPT-3.5) public release we had GPT-3 being one of the “best” Base Language Model which released ~2.1 years before ChatGPT. And following that we’ve had LLMs like Bard, Claude, GPT-4 and others.
2.2.Early Models#
There has been a few visible marks across modalities of AI models, highly catalysing growth of open source:
-
Meta AI launches LLaMA, open sourcing the code but not the weights.
Stable Diffusion#
Stable Diffusion is a latent text-to-image diffusion model [97]. Created by Stability AI and support from LAION, where they used 512x512 images from a subset of the LAION 5B database for training. Similar to Google’s Imagen [98], this model uses a frozen CLIP ViT-L/14 [99] text encoder to condition the model on text prompts. With its 860M UNet and 123M text encoder, the model is relatively lightweight and runs on a GPU with at least 10GB VRAM.
Uniqueness#
While training:
-
Text prompts are encoded through a ViT-L/14 text-encoder
-
UNet backbone of the latent diffusion model takes non-pooled output of the text encoder via cross-attention.
-
Loss is reconstruction objective between prediction made by UNet and noise added to the latent.
Limitations#
-
The model does not achieve perfect photorealism, or render legible text and performs poorly on difficult prompt like “A blue cube on top of a red sphere”.
-
The model was trained mainly with English captions.
-
No measures were used to deduplicate the dataset before usage.
LLaMA#
Under LLaMA [100], Meta AI released a collection of foundation language models ranging from 7B to 65B parameters, pre-trained over a corpus containing more than 1.4 trillion tokens. It was designed to be versatile and applicable for many different use cases, and possibly fine-tuned for domain specific tasks if required.
It showed better performance across domains compared to its competitors.
Fig. 28 LLaMA: Open and Efficient Foundation Language Models [100]#
LLaMA 13B outperforms GPT-3 (175B) on most benchmarks while being more than 10x smaller, and LLaMA 65B is competitive with models like Chinchilla 70B [101] and PaLM 540B. LLaMA 65B performs similarly to the closed-source GPT-3.5 on the MMLU and GSM8K benchmarks [100].
Uniqueness#
LLaMA架构,从其他LLMs中汲取了一些关键灵感:
- 预规范化(GPT-3):使用
RMSNorm来规范化 Transformer子层的输入[102]。 - SwiGLU激活函数(PaLM):用
SwiGLU代替ReLU激活函数[103]。 1.** 旋转嵌入(GPTNeo)**:用旋转位置嵌入替代绝对位置嵌入 [95]。
Limitations#
-
It was released under a non-commercial license focused on usage for research use cases only.
-
LLaMA is a foundation model and not fine-tuned for specific tasks, which may limit its performance on certain tasks
-
LLaMA seemed not as competitive as other models on certain benchmarks, such as BoolQ and WinoGrande.
Interestingly within a week from LLaMA’s launch, its weights were leaked to the public. facebookresearch/llama#73 created a huge impact on the community for all kinds innovations coming up, even though there was still license restrictions not permitting commercial usage.
2.3.Current Models#
After 2 weeks from the LLaMa weights leak, Stanford releases Alpaca 7B.
Alpaca 7B#
It’s a 7B parameter model fine-tuned from LLaMA 7B model on 52K instruction-following data-points. It performs qualitatively similarly to OpenAI’s text-davinci-003 while being smaller and cheaper to reproduce i.e taking only < 600 USD. Github repository here.
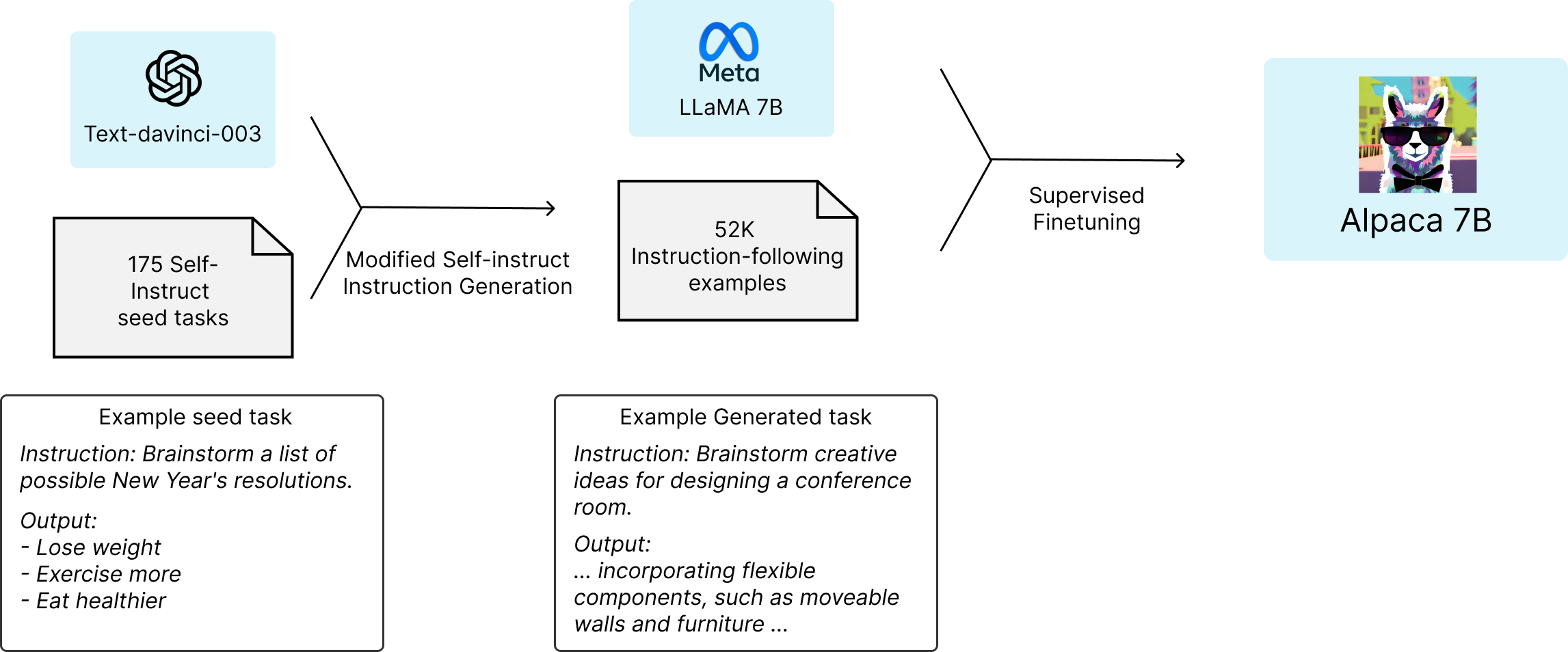
Fig. 29 Alpaca 7B fine-tuning strategy#
Uniqueness#
-
Unique Data Source: Alpaca 7B is distinct for being fine-tuned from LLaMA 7B using 52K instruction-following demonstrations coming from self-instruct [104], in the style of text-davinci-003, enabling research into instruction-following scenarios.
-
Cost-Efficient Alternative: Alpaca 7B offers similar performance to text-davinci-003 but at a lower cost, making it accessible for academic research.
Limitations#
-
Non-commercial Usage: This limitation arises from the non-commercial license of LLaMA, upon which Alpaca is based.
-
Quality: Alpaca 7B may occasionally produce inaccurate information, including hallucinations, misinformation, and toxic content.
-
Evaluation Scope: While Alpaca performs well in some evaluations, its performance may vary in unexplored scenarios.
Right after that alpaca-lora came out, using low rank fine-tuning it made possible to reproduce Alpaca within hours on a single NVIDIA RTX 4090 GPU with inference being possible even on a Raspberry PI.
Things moved fast from here when first promising inference speed was achieved without GPU for LLaMA using 4 bit quantisation by the LLaMA GGML. A new wave of quantised models started coming from the community.
In a day after, Vicuna came in.
Vicuna#
Vicuna was released under a joint effort by UC Berkeley, CMU, Stanford, UC San Diego, and MBZUAI. It was trained by fine-tuning LLaMA on user-shared conversations collected from ShareGPT. GPT-4 was used for its evaluation. They released a demo and code, weights under non-commercial license following LLaMa.
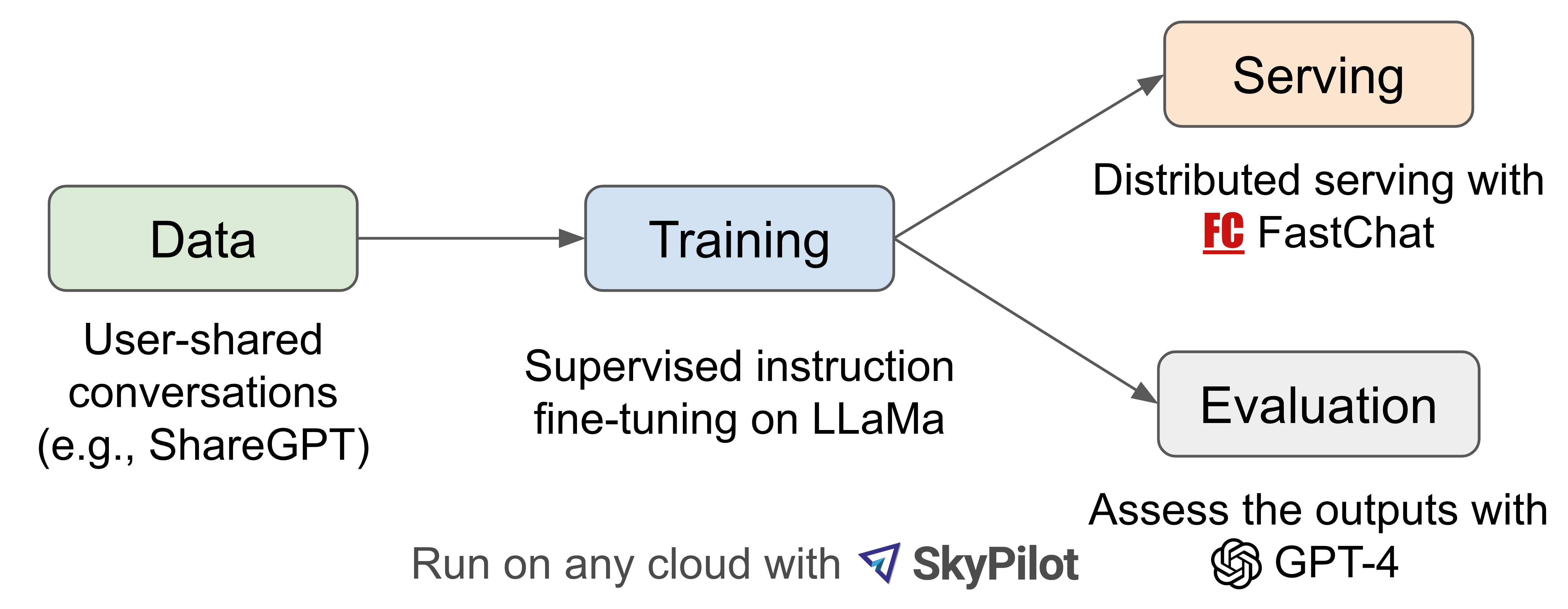
Fig. 30 Vicuna fine-tuning strategy#
Uniqueness#
-
Impressive Quality: Vicuna 13B achieved over 90% quality compared to ChatGPT and Google Bard, surpassing other models like LLaMA and Stanford Alpaca in more than 90% of cases.
-
For training:
-
Training loss was adjusted to account for multi-turn conversations and compute the fine-tuning loss solely on the chatbot’s output.
-
Expanded max context length from 512 in Alpaca to 2048, gradient checkpointing [105] and flash attention [106] utilisation helping handle memory pressure.
-
Used SkyPilot managed spot to reduce the cost for training the 7B model from $500 to around $140 and the 13B model from around $1k to $300.
-
-
Cost-Efficiency: The cost of training was around $300, making it a cost-effective choice for research purposes.
-
Enhanced Dataset: Vicuna is fine-tuned using 70K user-shared ChatGPT conversations from ShareGPT, enabling it to provide detailed and well-structured answers, with performance on par with ChatGPT.
Limitations#
-
Reasoning and Safety: Vicuna may struggle with tasks involving reasoning or mathematics and may not always ensure factual accuracy. It has not been fully optimised for safety or to mitigate potential toxicity or bias.
-
Evaluation Framework: The proposed evaluation framework, based on GPT-4, is not yet a rigorous or mature approach, as large language models can sometimes produce hallucinated responses.
-
No Dataset release.
-
Non-commercial usage only following the LLaMA model’s license, OpenAI’s data terms and Privacy Practices of ShareGPT.
After the release they also conducted a deeper study on GPT4-based evaluation approach.
Then came in updates like LLaMa-Adapter [107], Koala and in less than a month Open Assistant launches a model and a dataset for Alignment via RLHF [108].
Overall the LLaMA variants landscape looked somewhat like this, even though it doesn’t show all the variants:
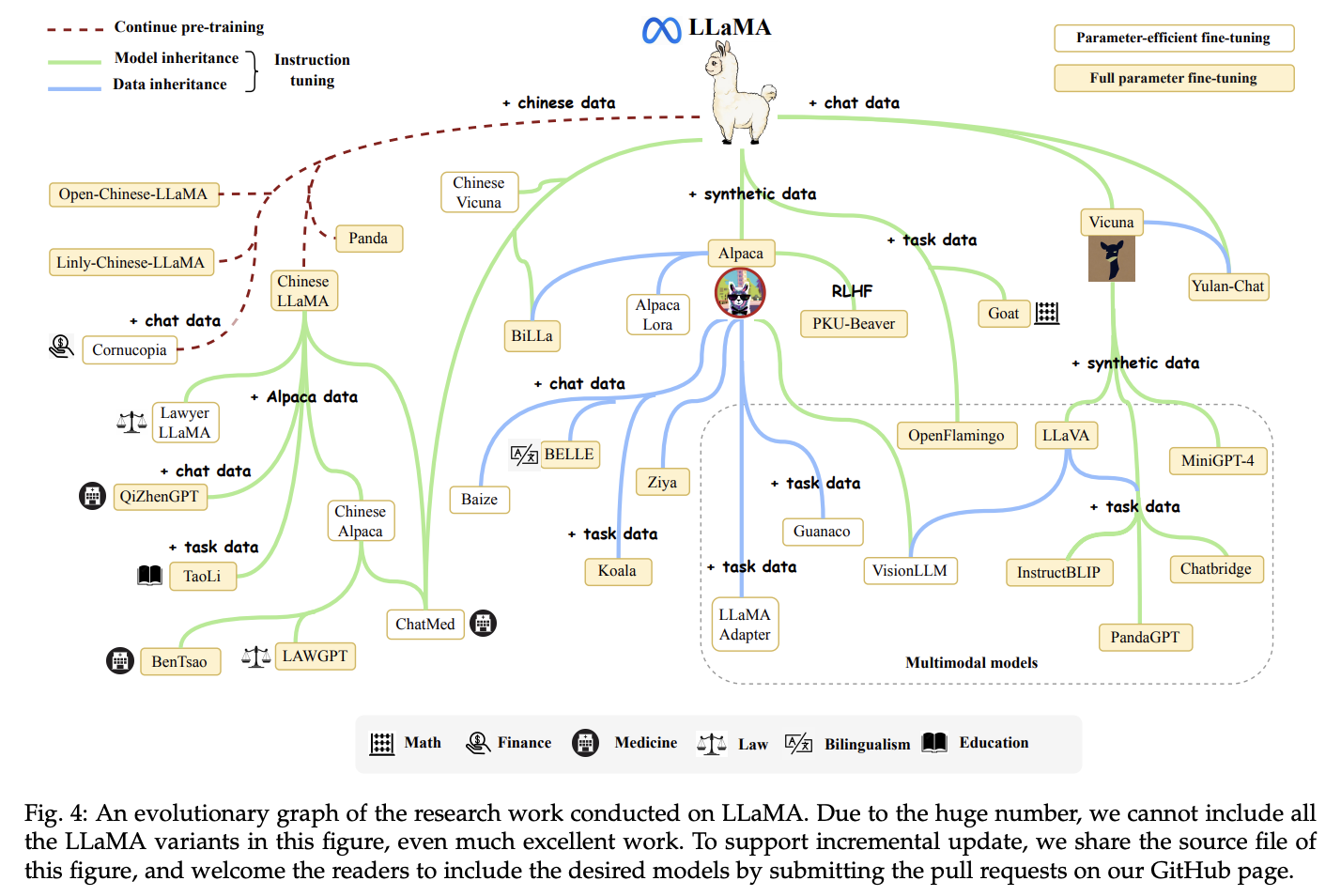
Fig. 31 Page 10, A Survey of Large Language Models [90]#
After a month, WizardLM dropped in which gained a lot of popularity mainly due to its ground breaking performances compared to other open LLMs. And in next few days the community did an open reproduction of LLaMA, named OpenLLaMA.
WizardLM#
WizardLM is created by fine-tuning LLaMA on a generated instruction dataset which was created by Evol-Instruct [109].
Uniqueness#
-
Proposed Evol-Instruct – method using LLMs instead of humans to automatically mass-produce open-domain instructions of various difficulty levels, to improve the performance of LLMs.
-
It achieves better response quality than Alpaca and Vicuna on the automation evaluation using GPT-4.
-
Shows Evol-Instruct method for creating instruction tuning datasets are superior to the ones from human-created ShareGPT.
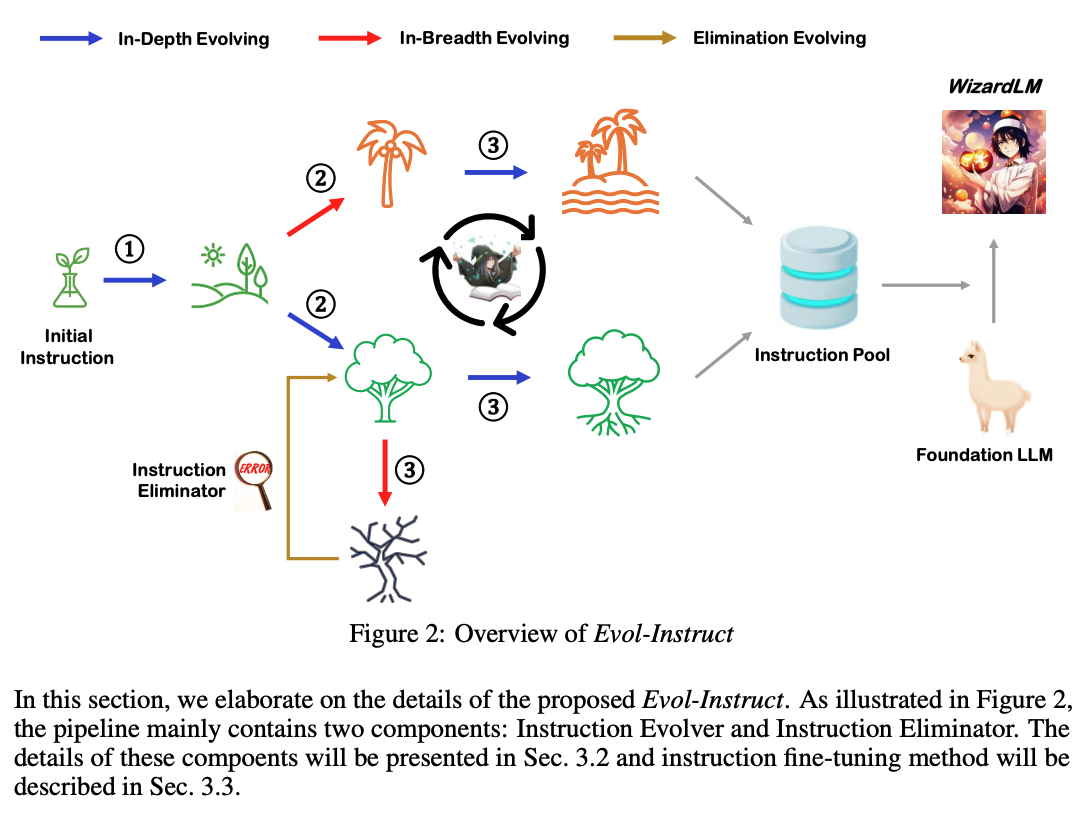
Fig. 32 Page 4, WizardLM: Empowering Large Language Models to Follow Complex Instructions [109]#
Limitations#
- Overall does not outperform ChatGPT except in few cases.
OpenLLaMA#
Students at UC Berkeley started OpenLM Research group through which they trained in collaboration with Stability AI to release OpenLLaMA v1, a permissively licensed open source reproduction of Meta AI’s LLaMA. They released a series of 3B, 7B and 13B models trained on different mix of datasets. And the weights released can serve as drop in replacement of LLaMA.
Uniqueness#
-
Model is trained on open sourced RedPajama dataset by Together.
-
All steps for training are kept same as mentioned in LLaMA [100].
-
Model is trained on 1T tokens.
-
Weights released under Apache 2.0 license, in two formats:
-
EasyLM format to be use with young-geng/EasyLM framework
-
PyTorch format to be used with the Hugging Face transformers library
-
Limitations#
- Dataset Difference: OpenLLaMA uses open datasets instead of the original LLaMA dataset. While training procedures, architecture, and other parameters remain the same, there may be differences in performance on certain tasks.
Around same time MosaicML released its MPT models series, and TII also released Falcon models.
MPT#
MosaicML released MPT (MosaicML Pretrained Transformer) models series consisting:
-
7B variants:
-
30B variants:
Uniqueness#
-
Licensed for commercial usage (not all variants in the series): MPT 7B base, MPT 7B-StoryWriter-65k+, MPT 30B were only released under Apache-2.0 license.
-
Uses ALiBi [110] to handle long inputs till 84k tokens context size, whereas trained using upto 65k tokens context.
-
Uses FlashAttention [106] and NVIDIA/FasterTransformer to optimise for fast training and inference.
-
They also released an entire framework, the MosaicML LLM Foundry.
Limitations#
-
Not all variants were released under permissive commercial usage license.
-
Combinations of open sourced datasets was used for training the models and mentioned which ones with proportions, but haven’t released the combined dataset yet.
Falcon#
TII released Falcon series of 40B, 7.5B and 1.3B parameters LLMs, trained on their open sourced and curated RefinedWeb dataset. After the release it has dominated the Huggingface’s open llm leaderboard for the State of the Art open sourced LLM for more than 2 months.
Uniqueness#
-
Falcon 40B has data from a variety of English, German, Spanish, French, Italian, Portuguese, Polish, Dutch, Romanian, Czech, and Swedish languages inserted into its pre-training set.
-
They released all the model and its instruction tuned and chat variants under Apache 2.0 license, permitting commercial usage.
-
The model uses only 75 percent of GPT-3’s training compute, 40 percent of Chinchilla AI’s, and 80 percent of PaLM 62B’s.
-
Falcon 40B pre-training dataset contained around 5 Trillion tokens gathered from public web crawls (~80%), research papers, legal text, news, literature, and social media conversations.
- Subset of this dataset containing 600 Billion tokens [111] was open sourced.
-
Model uses decoder-only architecture with Flash Attention [106], Multi-Query Attention [112], Parallel Attention and Feed Forward [113].
Limitations#
-
Full dataset used for pre-training the 40B variant wasn’t released.
-
Falcon 40B is trained using a sequence length of 2K, which is smaller compared to MPT, XGen, but context size can be increased using RoPE embeddings [95] within a model’s architecture, allowing it to generalise to longer sequence lengths (might require some Fine-tuning).
-
A paper detailing Falcon models specifically has not yet been released.
LLaMA-2#
On 18th July, Meta AI released LLaMA-2, breaking most SotA records on open sourced LLMs performances.
Meta AI facebookresearch/llama with both pre-trained and fine-tuned variants for a series of 7B, 13B and 70B parameter sizes.
Some win rate graphs on LLaMA-2 after evaluation comparisons against popular LLMs where it roughly ties with GPT-3.5 and performs noticeably better than Falcon, MPT and Vicuna.
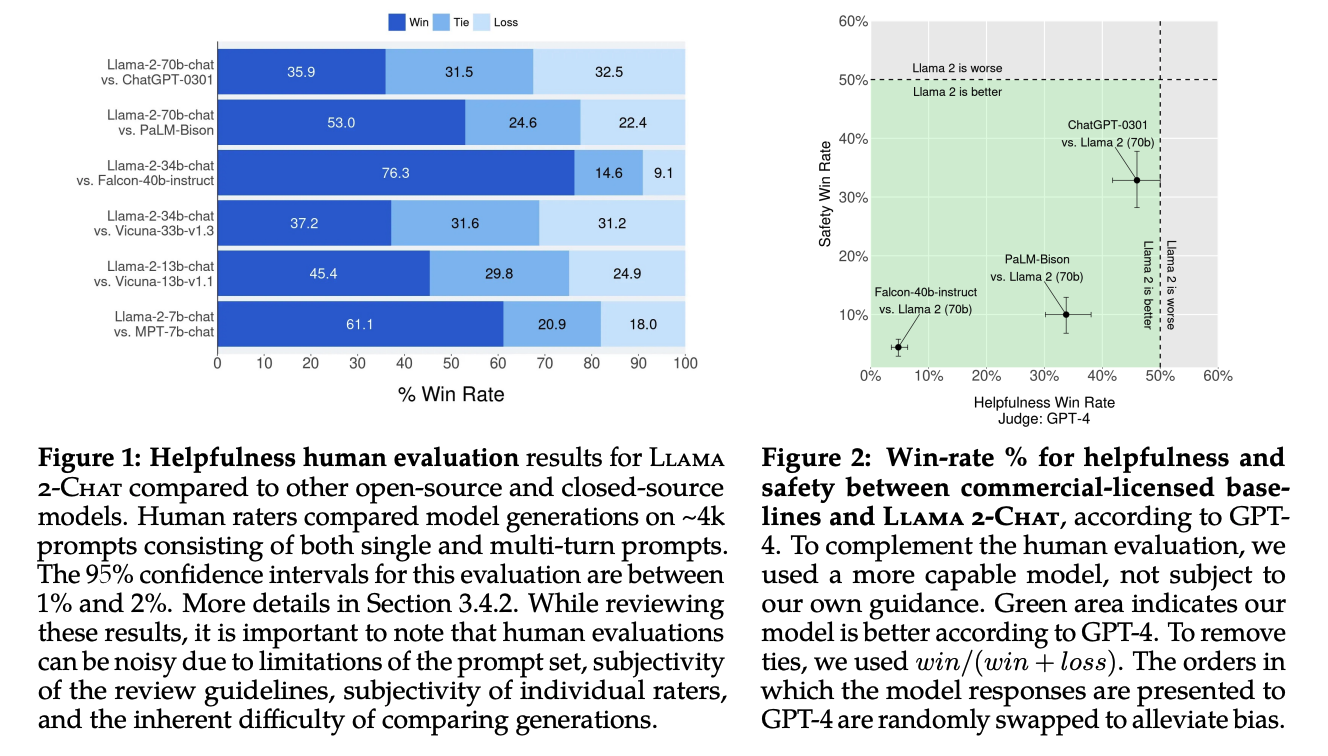
Fig. 33 Page 3, LLaMA 2: Open Foundations and Fine-Tuned Chat Models [114]#
Uniqueness#
-
LLaMA-2 models are pre-trained over 2 trillion tokens dataset in total, compared to 1.4 trillion tokens dataset for LLaMA-1.
-
LLaMA-2 models are trained with a 4k context length, whereas it’s 2k for LLaMA-1.
-
Larger variants use grouped query attention (GQA) [115] within their underlying architecture, helping improve inference efficiency.
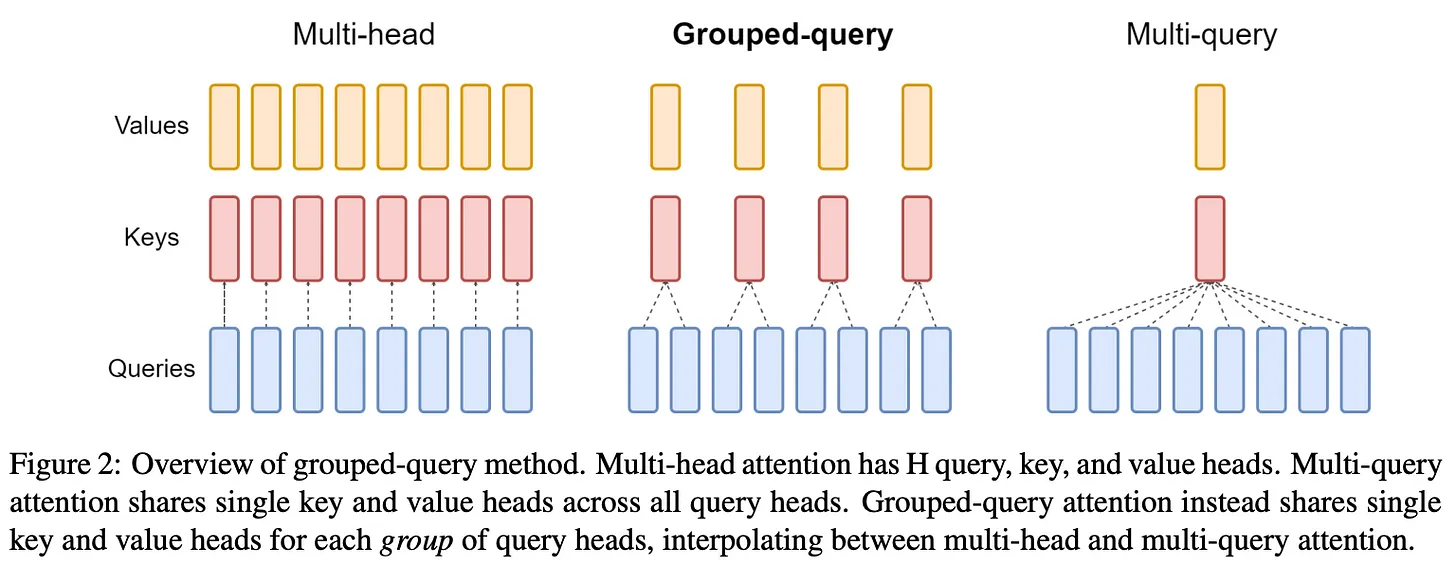
Fig. 34 GQA: Training Generalised Multi-Query Transformer Models from Multi-Head Checkpoints [115].#
-
LLaMA-2 70B became new state-of-the-art among open-source LLMs on all tasks considered.
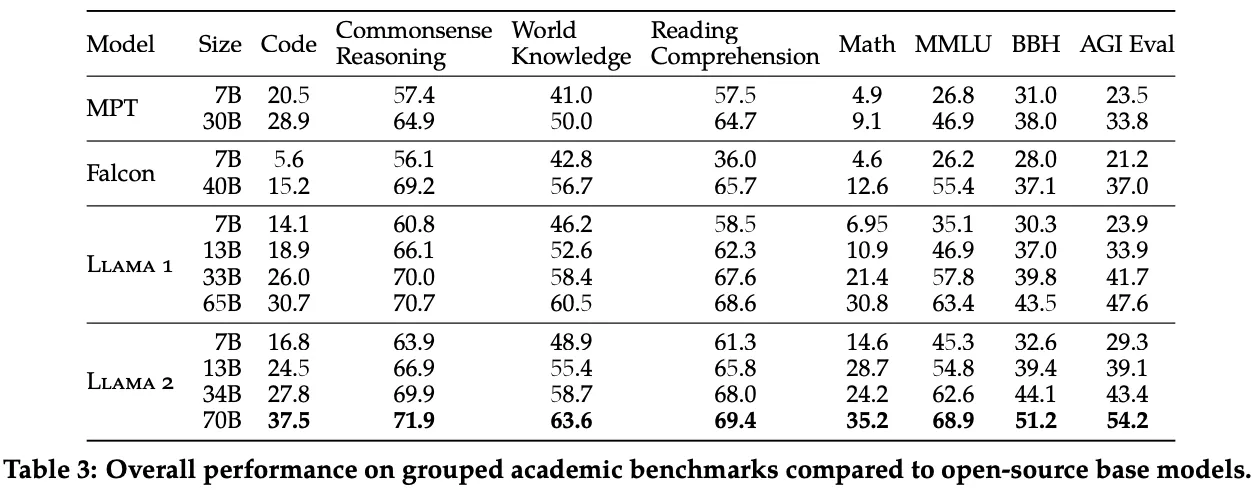
Fig. 35 Page 8, LLaMA 2: Open Foundations and Fine-Tuned Chat Models [114]#
-
They released chat variants from base models using instruction tuning and high scale RLHF, also proposed a Ghost Attention (GAtt) which helps control dialogue flow over multiple turns.
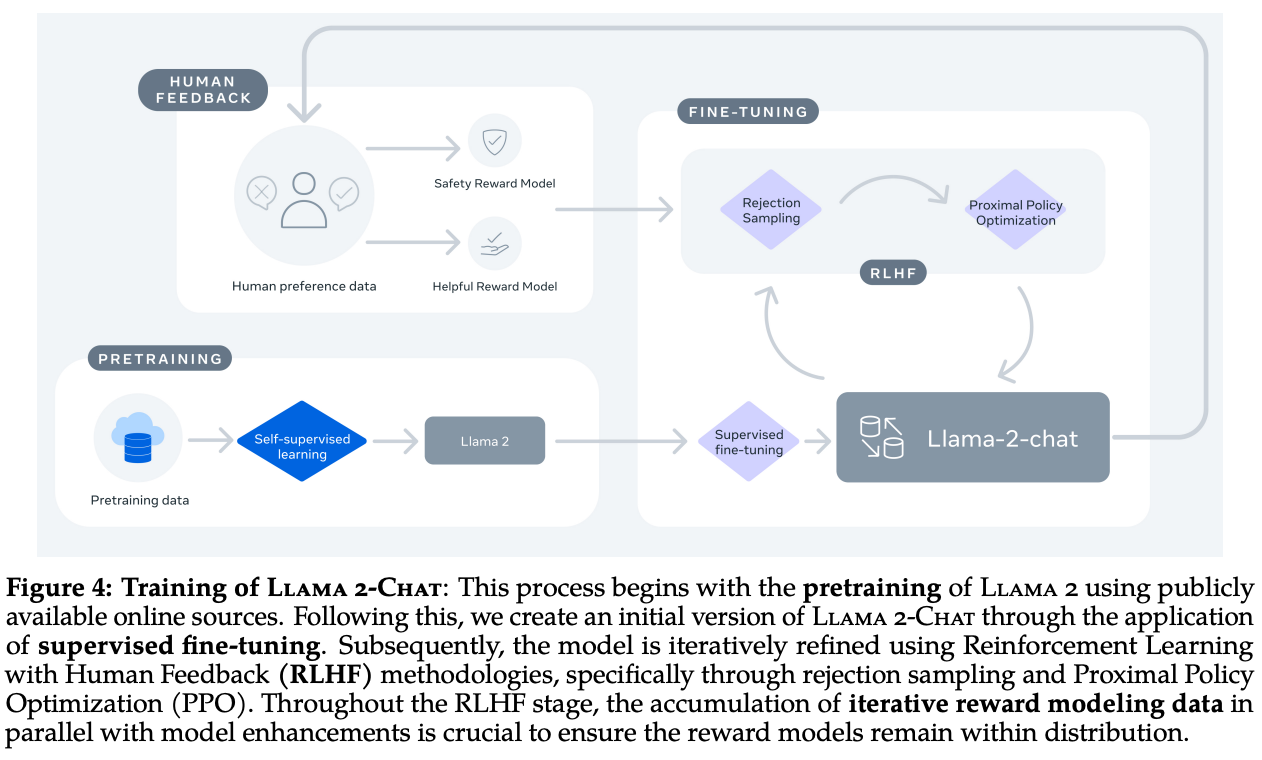
Fig. 36 Page 5, LLaMA 2: Open Foundations and Fine-Tuned Chat Models [114]#
-
For Alignment uses a two-stage RLHF approach, starting with Rejection Sampling, then doing Rejection Sampling + Proximal Policy Optimisation (PPO)
-
All model variants under LLaMA-2 are released under LLaMA-2 License, permitting commercial usage unless it’s facing 700 million monthly active users then the entity must obtain a license from Meta.
-
Meta’s team does quite some work for mitigating AI safety issues in the model.
- Released a responsible Use Guide.
Limitations#
-
LLaMA-2基础模型在性能上不如对齐的专有模型,但与流行的基础LLM(如PaLM)相比,表现出色。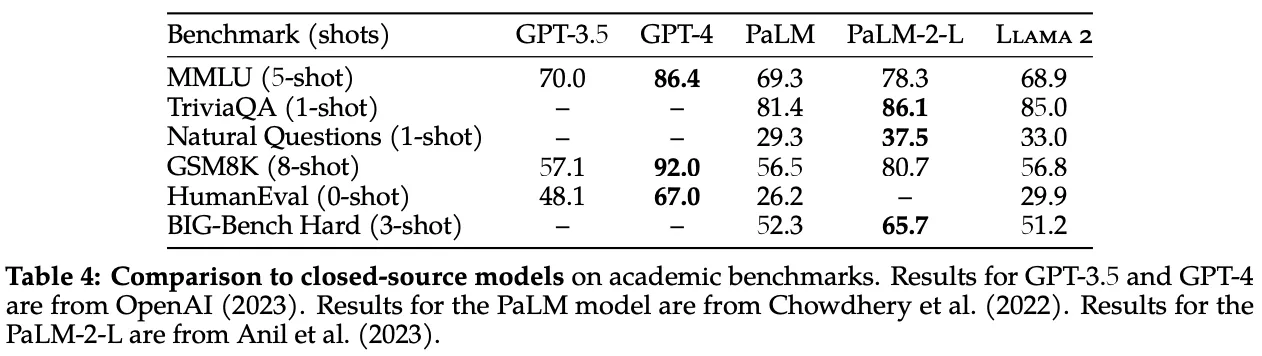
Fig. 37 Page 8, LLaMA 2: Open Foundations and Fine-Tuned Chat Models [114]#
-
LLaMA-2 Chat模型的变种,有时可能会因为对模型进行了高度的安全调整,而给出过于谨慎的回应。
-
在模型对齐步骤中(model alignment steps),使用的奖励模型(
Reward models)尚未开源。
Till now we’ve mostly been looking at LLMs in general and not other models, let’s look at the vision domain now.
Stable Diffusion XL#
StabilityAI released Stable Diffusion XL 1.0 (SDXL) models on 26th July, being current State of the Art for text-to-image and image-to-image generation open sourced models. They released a base model and a refinement model which is used to improve the visual fidelity of samples generated by SDXL.
Few months back they released Stable-diffusion-xl [117] base and refinement models versioned as 0.9, where license permitting only research purpose usages.
SDXL consistently surpasses all previous versions of Stable Diffusion models by a significant margin:
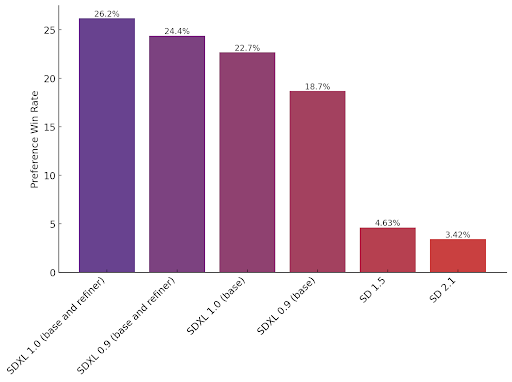
Fig. 38 SDXL Winrate#
Uniqueness#
-
Works effectively on GPUs with 8GB or more VRAM.
-
3x larger UNet-backbone compared to previous Stable Diffusion models.
-
Introduces a two-stage model process; the base model (can work standalone) generates an image as an input to the refiner model which adds additional high-quality details.
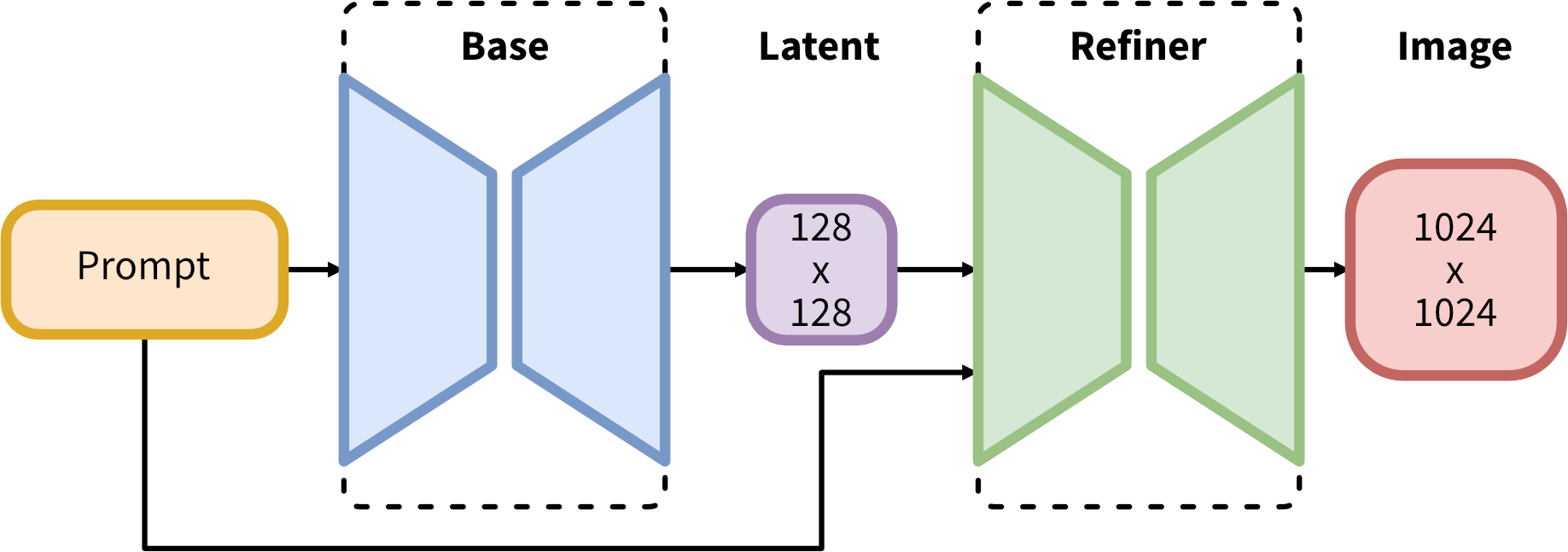
Fig. 39 SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis [117]#
-
Proposed two additional model conditioning techniques to preserve training data from being discarded and gain more control over how a generated image should be cropped:
-
Conditioning the Model on Image Size.
-
Conditioning the Model on Cropping Parameters.
-
-
Commercial usage allowed by SDXL License.
-
They also released a processed TensorRT variant of SDXL, which can give upto 41% latency and 70% throughput improvements.
-
Clipdrop provides free SDXL inference.
Limitations#
-
For high quality generations from SDXL, a two-stage approach is required i.e using an additional refinement model, having to load two large models into memory hampers accessibility and sampling speed.
-
Generations are sometimes poor when synthesising intricate structures, such as human hands, or while rendering long legible text.
-
Model achieves a remarkable level of realism in its generated images but does not attain perfect photorealism.
-
Model’s training process heavily relies on large-scale datasets, possibly introducing social and racial biases.
In the domain of Image generation currently Midjourney is one of the most popular proprietary solutions for simple users.
Following the timeline and going back to text domain, coder models are gaining lot of popularity too, specially looking at the code generation or code analysis capabilities of OpenAI’s codex and GPT-4, there has been few releases on code LLMs like WizardCoder [118], StarCoder, Code LLaMA (state of the art) and many more.
Code LLaMA#
Code LLaMA release by Meta AI (right after ~1.5 month from LLaMA 2’s release) caught lot of attention being full open source. And currently its fine-tuned variants are state of the art among open source coder models.
Uniqueness#
-
Outperforms GPT-3.5 on code generation capabilities.
-
Uses LLaMA-2 as foundation model.
-
Released three variants for each model sizes:
-
Code LLaMA: constitute foundation models for code generation. They come in three model sizes: 7B, 13B and 34B parameters. The 7B and 13B models are trained using an infilling objective, appropriate for code generation in an IDE. The 34B model was trained without the infilling objective
-
Code LLaMA – Python: specialised for Python code generation and also come in sizes of 7B, 13B, and 34B parameters. Trained on 500B tokens from the Code LLaMA dataset and further specialised on 100B tokens using a Python-heavy dataset. Python variants are trained without infilling and subsequently fine-tuned to handle long contexts.
-
Code LLaMA – Instruct: based on Code LLaMA and fine-tuned with an additional approx. 5B tokens to better follow human instructions.
Fig. 40 Page 3, Code LLaMA: Open Foundation Models for Code [119]#
-
-
Reached state-of-the-art performance among open models on several code benchmarks, with scores of up to 53% and 55% on HumanEval and MBPP, respectively.
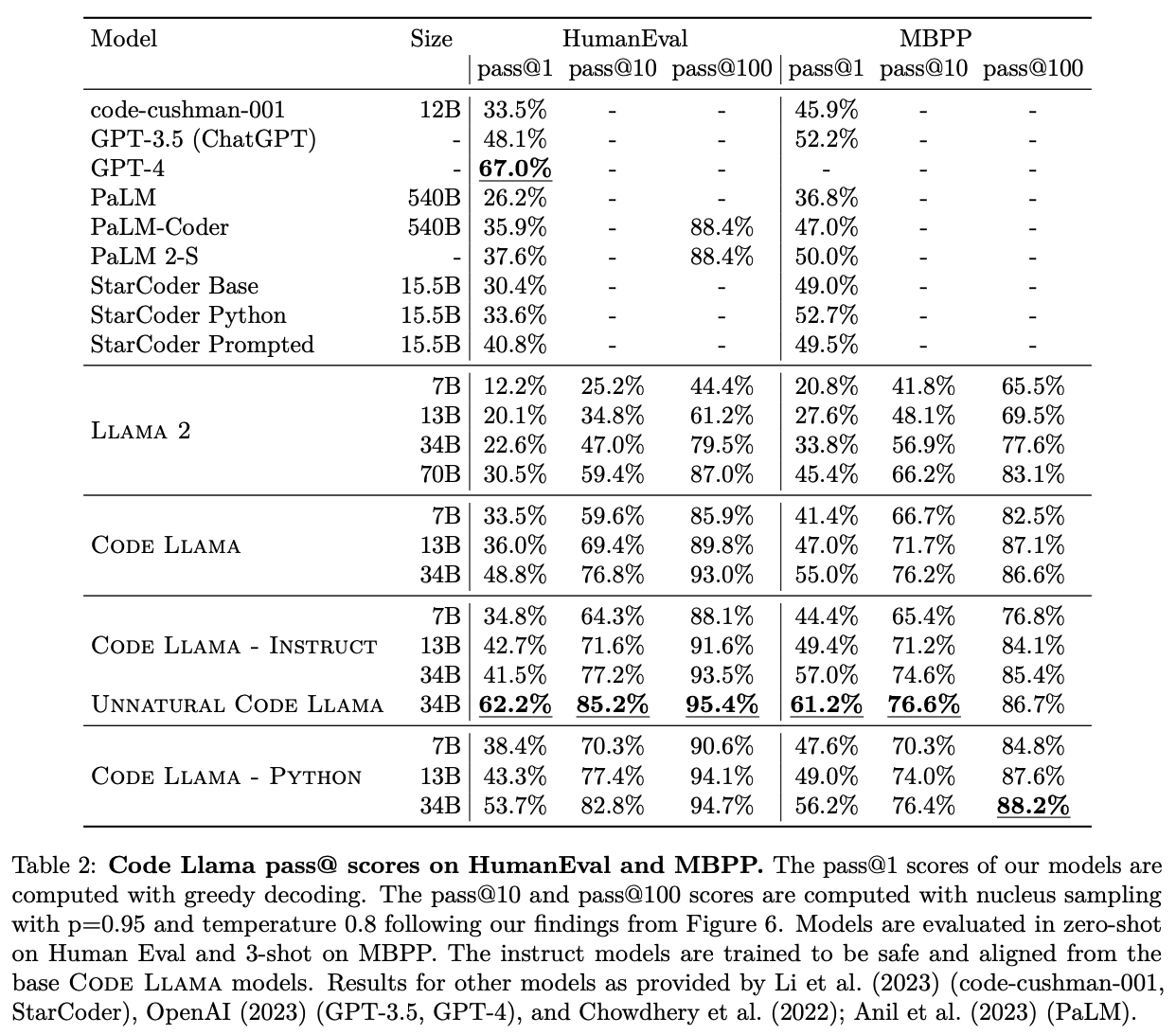
Fig. 41 Page 7, Code LLaMA: Open Foundation Models for Code [119]#
-
Supports code infilling.
-
All models are trained on sequences of 16k tokens and show improvements on inputs with up to 100k tokens.
-
Data is tokenised via byte pair encoding, using the same tokeniser as LLaMA and LLaMA 2.
-
Instruction tuning dataset combines thousands of Supervised Fine-Tuning and millions of Rejection Sampling examples.
-
Have been trained between January 2023 and July 2023.
-
Commercial usage: released under permissive license that allows for both research and commercial use, same as LLaMA 2.
Limitations#
-
Proprietary dataset: No Code LLaMA dataset open source release yet.
-
For 7B and 13B variants’ large context fine-tuning and infilling comes at a cost on standard benchmarks.
-
Performs worse compared to GPT-4.
Persimmon 8B#
Persimmon 8B is a standard decoder-only transformer model released under an Apache-2.0 license. Both code and weights are available at persimmon-ai-labs/adept-inference.
Uniqueness#
-
It has a large context size of 16K, four times that of LLaMA2 and eight times that of GPT-3 and MPT models.
-
It is a fully permissively licensed under Apache 2.0 and under 10 Billion parameters, making it highly suitable for commercial usage.
-
It includes 70k unused embeddings for potential multimodal extensions and incorporates sparse activations.
-
It’s trained on 0.37x as much data as LLaMA2 and despite that exceeds other ~8B models and matches LLaMA2 performance. Training dataset consists ~25% code and 75% text.
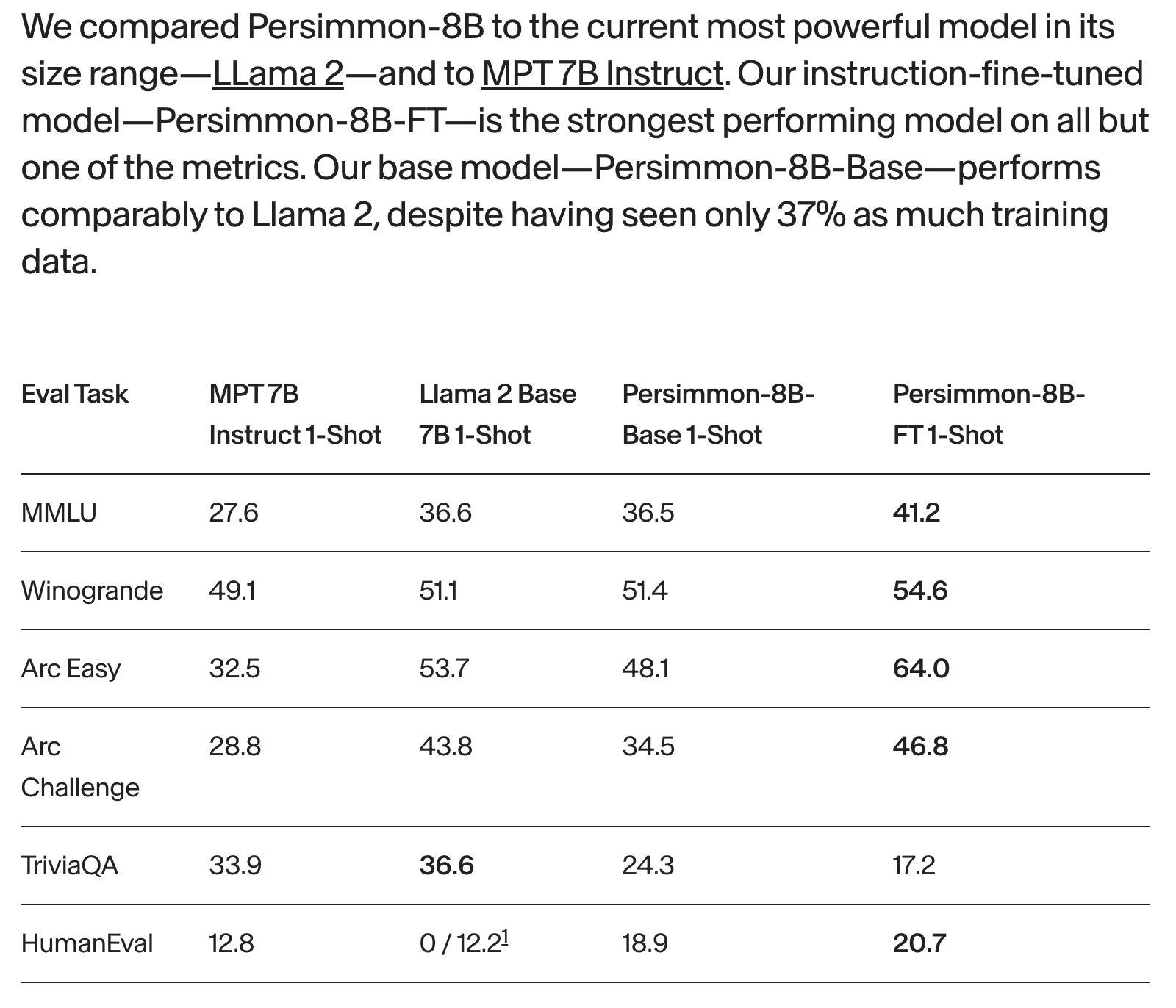
Fig. 42 Pers 8B Results#
-
Uses a vocabulary of 262k tokens, built using a unigram sentencepiece model.
-
Architecture is skinnier and deeper than LLaMA-2 7B.
-
They developed an improved version of FlashAttention.
-
Inference optimisations possible.
-
In the model architecture it uses:
Limitations#
- Normally it’s not recommended to train from scratch with 16k context size, as depending on dataset, simply increasing context length will cause model to attend across more unrelated documents.
Mistral 7B#
Mistral 7B is released by Mistral AI, a french startup which recently raised a good seed round. The team comprises of ex-Deepmind and ex-Meta researchers, who worked on LLaMA, Flamingo [122] and Chinchilla projects.
Uniqueness#
-
Mistral 7B outperforms LLaMA-2 13B on all and LLaMA-1 34B on code, math, and reasoning benchmarks.
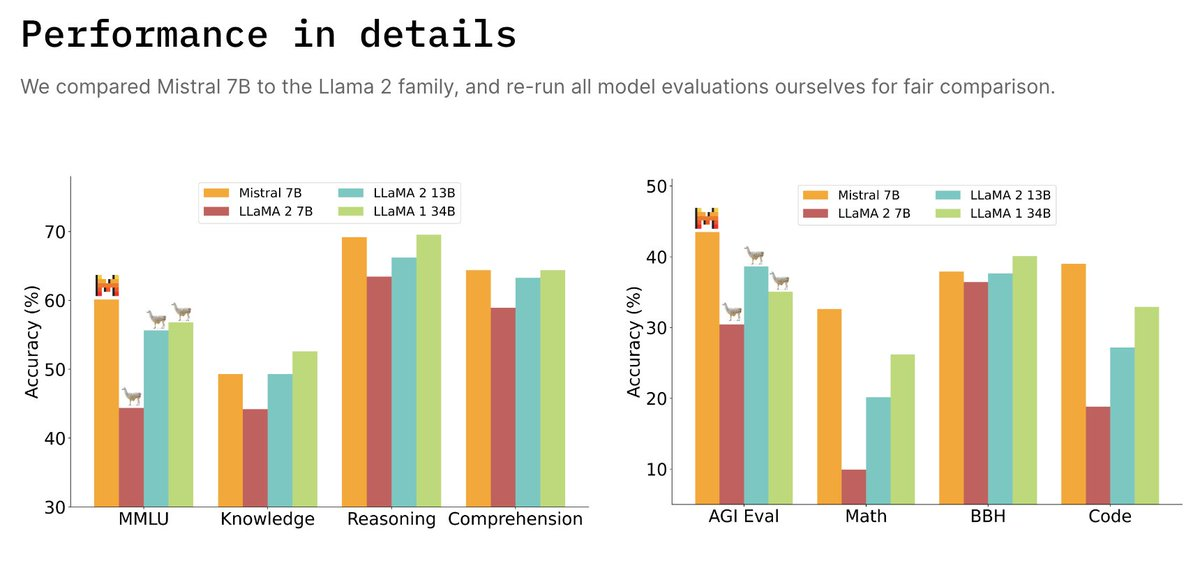
Fig. 43 Mistral 7B Comparison#
-
Close to Code LLaMA 7B performance on code, while remaining good at English tasks.
-
Uses Grouped-query attention (GQA) [115] for faster inference.
-
Uses Sliding Window Attention (SWA) [123, 124] to handle longer sequences at smaller cost.
-
Uses Byte-fallback BPE tokenizer.
-
Released 7B base model and 7B Instruct model which outperforms all 7B models on MT-Bench [53] and outperforms LLaMA-2 13B-Chat.
-
Both models released under Apache 2.0 license, with no restrictions.
-
Released a codebase which documents how to run and explains some concepts used in the model.
Limitations#
-
No training/fine-tuning code or paper has been released yet.
-
No training or fine-tuning dataset has been released even though they mentioned usage of datasets publicly available on HuggingFace for fine-tuning.
3.Comparisons#
在这里,我们回顾了文本和视觉领域中流行模型的特性。
将大型语言模型与一个唯一的真实标准进行比较是一项非常困难的任务,而比较视觉模型则更加困难。因为在一般化能力的同时,非常重要的是要注意模型可能存在的种族、性别、宗教和其他偏见。有许多流行的排行榜,用来跟踪这些模型的综合或特定性能:基于社区筛选的评估数据集/任务,可以衡量各种能力。
我们当前的比较方法包括在每个数据集上评估每个模型,并计算数据集之间的平均分数。结合人工评估和GPT-4的比较,可以得到一种相对可信赖的分数,用于追踪当前的最佳模型。但是,当前的方法还不足以完全满足需求,即使像GPT-4这样的支柱模型也会出现问题,而且很难确定评估集中有多少相似的数据实际上是训练集的一部分。
3.1.Language#
Open LLM Leaderboard shows us that Falcon 180B is currently just ahead of Meta’s LLaMA-2 70B, and TII claims that it ranks just behind OpenAI’s GPT 4, and performs on par with Google’s PaLM-2 Large, which powers Bard, despite being half the size of the model. But it required 4x more compute to train and it’s 2.5 times larger compared to LLaMA-2, which makes it not so cost-effective for commercial usages.
For practical commercial usage models ranging below 14B parameters has been a good candidate, and Mistral 7B, LLaMA-2 7B, Persimmon 8B does a great job showing that.
Overall let’s take look at the few discussed LLMs’ attributes to get the bigger picture.
Table 5 Under 15 Billion Parameters#
| LLMs | Params/[B] | Dataset | Release Details | Tokens/[B] | VRAM/[GB] | License | Commercial Usage |
|---|---|---|---|---|---|---|---|
| Mistral 7B | 7.3 | - | Blog | - | 17+ | Apache-2.0 | ✅ |
| LLaMA-2 13B | 13 | - | [114] | 2000 | 29+ | LLaMA-2 | ✅ |
| LLaMA-2 7B | 7 | - | [114] | 2000 | 15.8+ | LLaMA-2 | ✅ |
| Persimmon 8B | 9.3 | - | Blog | 737 | 20.8+ | Apache-2.0 | ✅ |
| WizardLM 13B | 13 | evol-instruct | [109] | ~2000 | 30+ | LLaMA-2 | ✅ |
| WizardLM 7B | 7 | evol-instruct | [109] | ~2000 | 15.8+ | Non-Commercial | ❌ |
| Falcon 7B | 7 | RefinedWeb (partial) | - | 1500 | 16+ | Apache-2.0 | ✅ |
| MPT 7B | 6.7 | RedPajama | Blog | 1000 | 15.5+ | Apache-2.0 | ✅ |
3.2.Vision#
StabilityAI’s SDXL vs Midjourney comparison shows that it is on par with favourability.
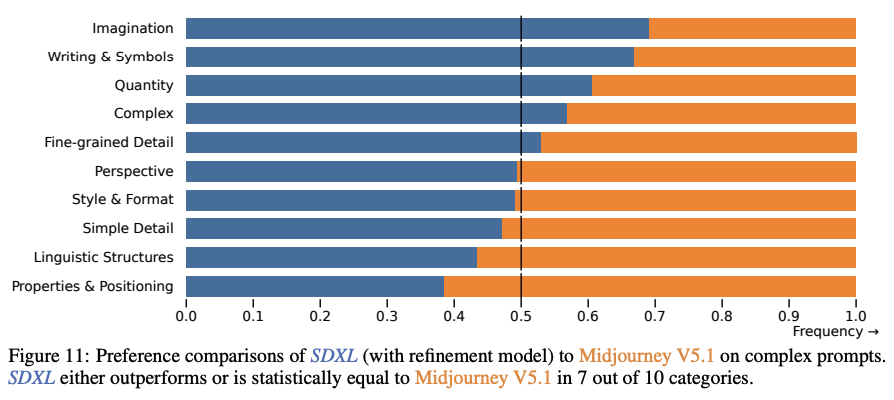
Fig. 44 Page 14, SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis [117]#
Note
Above experiment is against Midjourney v5.1, whereas current latest is Midjourney v5.2.
Future#
To recap current advancements we can see that few key moments were:
-
Release of Stable Diffusion models by StabilityAI.
-
Creation and release of RLHF recipes.
-
a few smaller moments.
Even though Open Source AI is advancing, it is evident that it remains heavily regulated by major corporations such as Meta, OpenAI, Nvidia, Google, Microsoft, and others. These entities often control critical parameters, creating a myth of open source AI [125], including:
尽管开源人工智(Open Source AI)能正在不断发展,显然,它仍然受到主要跨国公司的严格监管,如Meta、OpenAI、Nvidia、Google、Microsoft等等。这些组织/团队通常掌控关键参数,并构造了关于开源人工智能的神话,其中包括:
-
训练数据:Data required to train these models.
-
软件架构:Control of Software frameworks required to build such models
-
底层算力:Compute power required to train these models.
Returning to actual state, there are significant gaps that need to be addressed to achieve true progress in the development of intelligent models. For instance, recent analyses have revealed the limited generalization capabilities [126], current LLMs learn things in the specific direction of an input context window of an occurrence and may not generalize when asked in other directions.
回到实际情况,有一些重要的问题需要解决,来推动 AI 的向前发展。例如,最近的分析显示了有限的泛化能力 [126],当前的LLMs在出现的输入上下文窗口的特定方向中学习东西,当在其他方向提出问题时可能无法泛化。
MoE(Mixture-of-Experts)模型的崛起引起了人们的关注和研究兴趣,尤其是在有关GPT-4架构的传闻之后。开源社区已经在实现各种MoE变体方面取得了进展(例如XueFuzhao/OpenMoE),展示了朝着更多功能的模型架构的发展方向。
另一方面,使用模型的量化版本的各种应用正在涌现,因为它使在低精度上运行大型模型(>30B参数)成为可能,即使在只有CPU的机器上也可以运行。Specially lots of contributions in this area is coming up by ggerganov/ggml community and TheBloke.
原文地址:https://ningg.top/ai-series-prem-04-models/