AI 系列:Fine-tuning
2023-10-28
原文:Fine-tuning
Work in Progress
This chapter is still being written & reviewed. Please do post links & discussion in the comments below, or open a pull request!
Some ideas:
https://gist.github.com/veekaybee/be375ab33085102f9027853128dc5f0e#training-your-own
Why You (Probably) Don’t Need to Fine-tune an LLM (instead, use few-shot prompting & retrieval-augmented generation)
Fine-Tuning LLaMA-2: A Comprehensive Case Study for Tailoring Models to Unique Applications (fine-tuning LLaMA-2 for 3 real-world use cases)
Easy-to-use LLM fine-tuning framework (LLaMA-2, BLOOM, Falcon, Baichuan, Qwen, ChatGLM2)
h2oai, etc.
The History of Open-Source LLMs: Better Base Models (part 2) (LLaMA, MPT, Falcon, LLaMA-2)
For bespoke applications, models can be trained on task-specific data. However, training a model from scratch is seldom required. The model has already learned useful feature representations during its initial (pre) training, so it is often sufficient to simply fine-tune. This takes advantage of transfer learning, producing better task-specific performance with minimal training examples & resources – analogous to teaching a university student without first reteaching them how to communicate.
对于定制应用,可以根据特定任务的数据训练模型。然而,很少需要从头开始训练模型。
- 模型在初始(预)训练期间已经学到了有用的特征表示,因此通常只需
微调就足够了。 - 这充分利用了
迁移学习,可以在最小的训练示例和资源下,产生更好的特定领域的模型,类似于,大学期间不会再从头教学生如何说话,默认大家都会说话了。
1.How Fine-Tuning Works#
-
预训练:Start with a pre-trained model that has been trained on a large generic dataset.
-
定义独立的分类层:Take this pre-trained model and add a new task-specific layer/head on top. For example, adding a classification layer for a sentiment analysis task.
-
冻结预训练的权重:Freeze the weights of the pre-trained layers so they remain fixed during training. This retains all the original knowledge.
-
训练自定义的独立分层的权重:Only train the weights of the new task-specific layer you added, leaving the pre-trained weights frozen. This allows the model to adapt specifically for your new task.
-
训练过程中,给出反馈/校正:Train on your new downstream dataset by passing batches of data through the model architecture and comparing outputs to true labels.
-
循环几次,每次启用部分预训练的分层权重,参与训练:After some epochs of training only the task layer, you can optionally unfreeze some of the pre-trained layers weights to allow further tuning on your dataset.
-
持续迭代,直到达到最佳权重:Continue training the model until the task layer and selected pre-trained layers converge on optimal weights for your dataset.
关键在于,在训练期间大多数原始模型权重保持不变。只有一小部分权重会根据新数据进行更新,从而将通用知识传递过去,实现了针对特定任务的局部调整。
2.Fine-Tuning LLMs#
当一个LLM没有产生期望的输出时,工程师们认为通过对模型进行微调,可以使它变得“更好”。但在这种情况下,“更好”到底是什么意思呢?在对新数据集进行微调之前,找出问题的根本原因非常重要。
常见的LLM问题包括:
- 模型对某些
主题缺乏知识:可以使用RAG来解决这个问题 - 模型的回应,没有用户
期望的风格或结构:这里可以使用微调或少量提示的方法。
检索增强生成(Retrieval Augmented Generation,简称RAG)是一种人工智能技术,它结合了信息检索和生成模型,以生成与查询相关的文本或回答问题。RAG模型通常包括两个关键组件:
- 生成模型:这是一个语言生成模型,例如大型语言模型(LLM),它可以生成文本或回答问题。
- 检索模型:这是用于从
大型文本数据库中,检索相关信息的模型。通常,它会根据查询,找到相关的文本段落或文档。
RAG模型通过结合这两个组件,可以更好地理解问题并生成更具信息价值的答案。它可以用于各种任务,包括问答系统、自然语言生成、信息检索等领域。这种方法使生成模型能够借助大规模的知识库来提供更准确、更全面的回答。
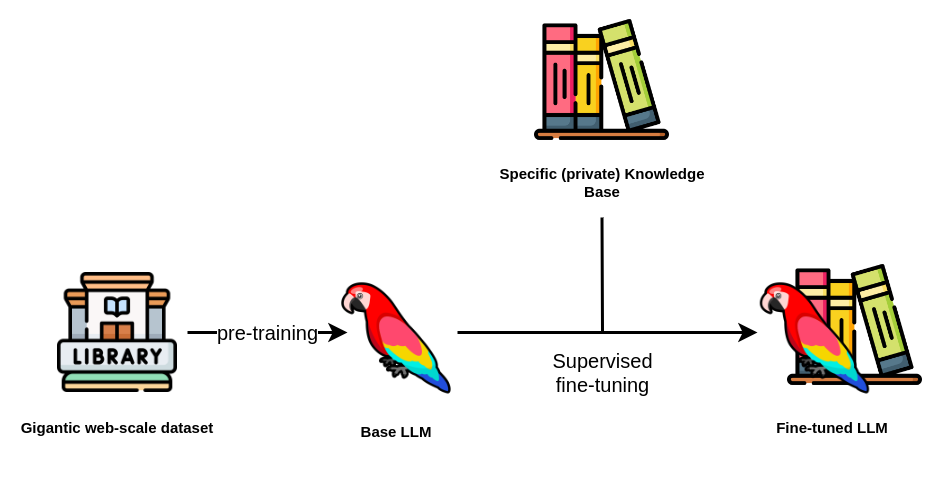
Fig. 52 Fine-Tuning LLMs#
基本的大型语言模型(LLM)无法回答关于它未经过训练的内容的问题[139]。
- LLM会编造答案,即“幻觉”。
- 为了解决这类问题,RAG是一个不错的工具,因为它为LLM提供了回答问题所需的
上下文。 - 另一方面,如果LLM需要生成
准确的SQL查询,RAG在这里不会有太大帮助。生成的输出格式非常重要,因此对于这种用例,微调将更有用。
Here are some examples of models that have been fine-tuned to generate content in a specific format/style:
-
Gorilla LLM - This LLM was fine-tuned to generate API calls.
-
LLaMA-2 chat - The “chat” version of LLaMA is fine-tuned on conversational data.
-
Code LLaMA - A fine-tuned LLaMA-2 model designed for code generation.
3.RAG#
检索增强生成(Retrieval Augmented Generation,简称RAG)是一种用于提高LLM准确性的方法,它通过将相关背景信息注入到LLM提示中来实现。
- 它通过连接到
向量数据库,仅提取与用户查询最相关的信息。 - 使用这种技术,LLM将获得
足够的背景知识,以适当地回答用户的问题而不会产生幻觉。
RAG is not a part of fine-tuning, because it uses a pre-trained LLM and does not modify it in any way. However, there are several advantages to using RAG:
-
Boost model accuracy:提升
准确度,依赖提供准确的上下文,降低模型输出的幻觉。- Leads to less hallucinations by providing the right context
-
Less computing power required:减少计算资源,跟
fine-tuning不同,RAG 并没有改变模型,本质是改变了prompt 提示词.- Unlike fine-tuning, RAG does not need to re-train any part of the model. It’s only the models prompt that changes.
-
Quick and easy setup:降低使用成本,无需关注 LLM 领域的专业知识,不需要找到培训数据或相应的标签。大多数文本片段可以按原样上传到向量数据库,无需进行重大修改。
- RAG does not require much domain expertise about LLMs. You don’t need to find training data or corresponding labels. Most pieces of text can be uploaded into the vector db as is, without major modifications.
-
Connect to private data:连接到私有数据,使用RAG,工程师可以将来自SaaS应用程序(如Notion、Google Drive、HubSpot、Zendesk等)的数据连接到他们的LLM。现在,LLM可以访问私有数据,并帮助回答有关这些应用程序中的数据的问题。
- Using RAG, engineers can connect data from SaaS apps such as Notion, Google Drive, HubSpot, Zendesk, etc. to their LLM. Now the LLM has access to private data and can help answer questions about the data in these applications.
RAG 使得 LLMs 模型更易用,但是设置 RAG 有些繁琐,当前有很多开源项目(例如 run-llama/llama_index)在解决这个问题。
4.Fine-Tuning Image Models#
Fine tuning computer vision based models is a common practice and is used in applications involving object detection, object classification, and image segmentation.
计算机视觉的模型的微调(fine-tuning)是一种常见的做法,用于涉及对象检测、对象分类和图像分割的应用中。
对于这些非生成型的人工智能场景,可以在标记的数据上对基线模型(如Resnet或YOLO)进行微调,以侦测新对象。尽管基线模型最初没有为新对象进行训练,但它已经学到了特征表示。微调使模型能够快速获取新对象的特征,而无需从头开始。
数据准备在为视觉模型进行微调的过程中起着重要作用。
- 同一对象的图像可以从多个角度、不同的光照条件、不同的背景等多个角度进行拍摄。
- 为了构建用于微调的健壮数据集,应考虑所有这些图像变化。
4.1.Fine-Tuning AI image generation models#
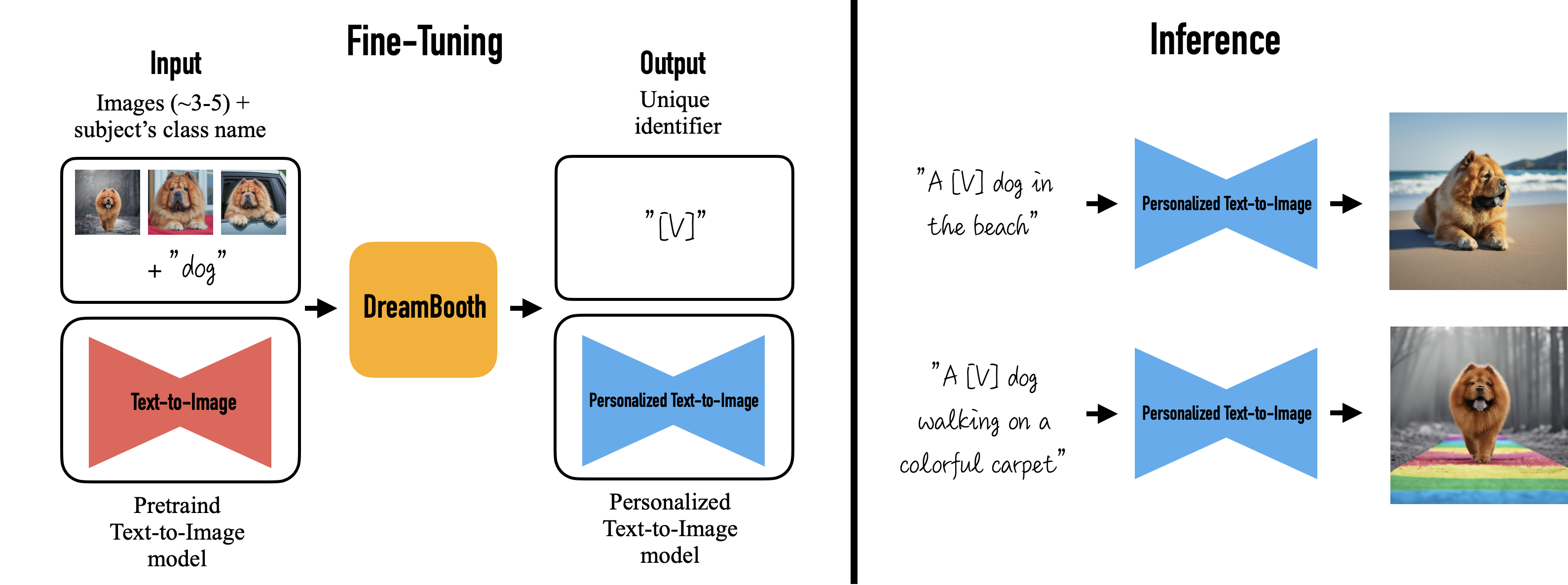
Fig. 53 Dreambooth Image Generation Fine-Tuning#
模型,例如 Stable Diffusion ,也可以通过微调来生成特定的图像。例如,通过提供宠物图片的数据集并对其进行微调,Stable Diffusion 模型可以生成特定宠物的各种风格的图像。
用于微调图像生成模型的数据集需要包含两个要素:
- 文本:图像中的对象是什么
- 图像:图片本身
文本提示描述了每张图像的内容。在微调过程中,文本提示被传递到 Stable Diffusion 的文本编码器部分,而图像被传递到图像编码器。基于数据集中的这种文本-图像配对,模型学会生成与文本描述相匹配的图像。[140].
5.Fine-Tuning Audio Models#

Fig. 54 Audio Generation Fine-Tuning#
类似于微调图像生成模型, Whisper 等语音转文本模型也可以进行微调。与建立微调模型相关的关键点有两点数据:
-
Audio recording,音频录制
-
Audio transcription,音频转录
准备强大的数据集对于构建微调模型至关重要。对于音频相关的数据,有一些需要考虑的事项:
声学条件:
- 背景噪声水平 - 噪声越大,转录越困难。模型可能需要增强噪声鲁棒性。
- 音质 - 高音质的音频和清晰的语音更容易转录。低比特率音频具有挑战性。
- 说话口音和声音类型 - 培训数据中说话者的多样性有助于泛化。
- 音频领域 - 每个领域,如会议、呼叫中心、视频等,都具有独特的声学特性。
数据集创建:
- 训练示例的数量 - 更多的音频-文本对提高准确性,但需要付出努力。
- 数据收集方法 - 转录服务、抓取、内部录制。质量不同。
- 转录准确性 - 高精度的转录至关重要。糟糕的转录会降低微调效果。
- 数据增强 - 随机噪声、速度、音高变化可以使模型更加健壮。
6.Importance of data#
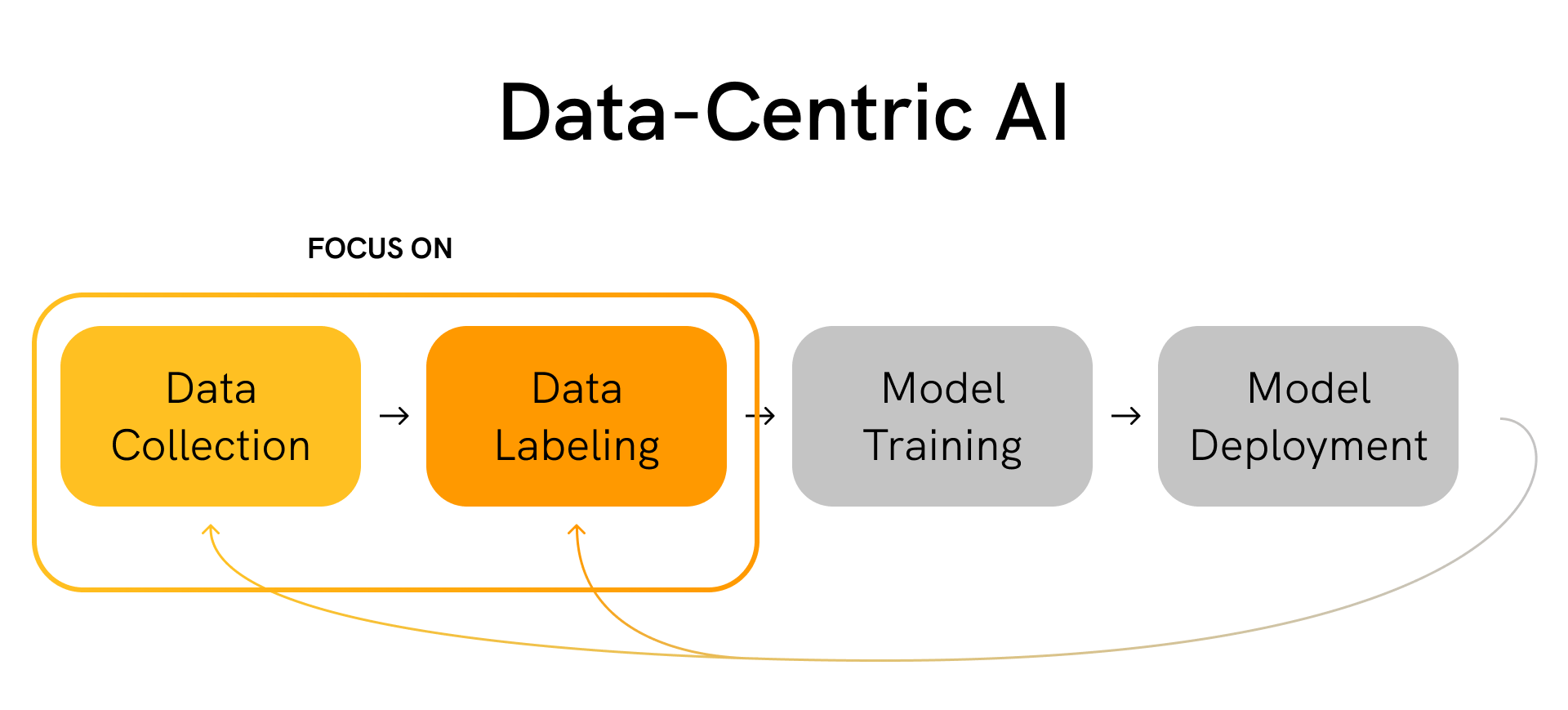
Fig. 55 Data centric AI#
The performance of a fine-tuned model largely depends on the quality and quantity of training data.
For LLMs, the quantity of data can be an important factor when deciding whether to fine-tune or not. There have been many success stories of companies like Bloomberg [141], Mckinsey, and Moveworks that have either created their own LLM or fine-tuned an existing LLM which has better performance than ChatGPT on certain tasks. However, tens of thousands of data points were required in order to make these successful AI bots and assistants. In the Moveworks blog post, the fine-tuned model which surpasses the performance of GPT-4 on certain tasks, was trained on an internal dataset consisting of 70K instructions.
In the case of computer vision models, data quality can play a significant role in the performance of the model. Andrew Ng, a prominent researcher and entrepreneur in the field of AI, has been an advocate of data centric AI in which the quality of the data is more important than the sheer volume of data [142].
To summarise, fine-tuning requires a balance between having a large dataset and having a high quality dataset. The higher the data quality, the higher the chance of increasing the model’s performance.
Table 7 Estimates of minimum fine-tuning Hardware & Data requirements#
| Model | Task | Hardware | Data |
|---|---|---|---|
| LLaMA-2 7B | Text Generation | GPU: 65GB, 4-bit quantised: 10GB | 1K datapoints |
| Falcon 40B | Text Generation | GPU: 400GB, 4-bit quantised: 50GB | 50K datapoints |
| Stable Diffusion | Image Generation | GPU: 6GB | 10 (using Dreambooth) images |
| YOLO | Object Detection | Can be fine-tuned on CPU | 100 images |
| Whisper | Audio Transcription | GPU: 5GB (medium), 10GB (large) | 50 hours |
GPU memory for fine-tuning
Most models require a GPU for fine-tuning. To approximate the amount of GPU memory required, the general rule is around 2.5 times the model size. Note that quantisation to reduce the size tends to only be useful for inference, not training-fine-tuning. An alternative is to only fine-tune some layers (freezing and quantising the rest), thus greatly reducing memory requirements.
For example: to fine-tune a
float32(i.e. 4-byte) 7B parameter model:7×109 params×4 B/param×2.5=70 GB
7.Future#
Fine-tuning models has been a common practice for ML engineers. It allows engineers to quickly build domain specific models without having to design the neural network from scratch.
Developer tools for fine-tuning continue to improve the overall experience of creating one of these models while reducing the time to market. Companies like Hugging Face are building open-source tools to make fine-tuning easy. On the commercial side, companies like Roboflow and Scale AI provide platforms for teams to manage the full life-cycle of a model.
总的来说,微调已经成为将大型预训练的AI模型适应自定义数据集和用例的关键技术。尽管在不同领域的具体实施细节有所不同,但核心原则相似:
- 利用在
大量数据上预训练的模型 冻结大多数参数添加一个针对特定数据集定制的可调组件,并更新一些权重以使模型适应。
正确应用微调,使从业者能够使用领先的大型AI模型,构建现实世界的解决方案。
原文地址:https://ningg.top/ai-series-prem-06-fine-turning/