AI 系列:MLOps Engines
2023-11-04
Work in Progress
This chapter is still being written & reviewed. Please do post links & discussion in the comments below, or open a pull request!
Some ideas:
-
7 Frameworks for Serving LLMs “comprehensive guide & detailed comparison”
-
Python Bindings and More
-
PyTorch Toolchain – From C/C++ to Python
-
Apache TVM
本章重点关注最近开源的MLOps引擎开发,这在很大程度上是由于大型语言模型的兴起所驱动的。尽管MLOps通常关注模型训练,但 LLMOps 专注于模型微调。在生产中,两者都需要良好的推理引擎。
Table 10 Comparison of Inference Engines#
| Inference Engine | Open-Source | GPU optimisations | Ease of use |
|---|---|---|---|
| Nvidia Triton | 🟢 Yes | Dynamic Batching, Tensor Parallelism, Model concurrency | 🔴 Difficult |
| Text Generation Inference | 🟢 Yes | Continuous Batching, Tensor Parallelism, Flash Attention | 🟢 Easy |
| vLLM | 🟢 Yes | Continuous Batching, Tensor Parallelism, Paged Attention | 🟢 Easy |
| BentoML | 🟢 Yes | None | 🟢 Easy |
| Modular | 🔴 No | N/A | 🟡 Moderate |
| LocalAI | 🟢 Yes | 🟢 Yes | 🟢 Easy |
Feedback
Is the table above outdated or missing an important model? Let us know in the comments below, or open a pull request!
Nvidia Triton Inference Server#
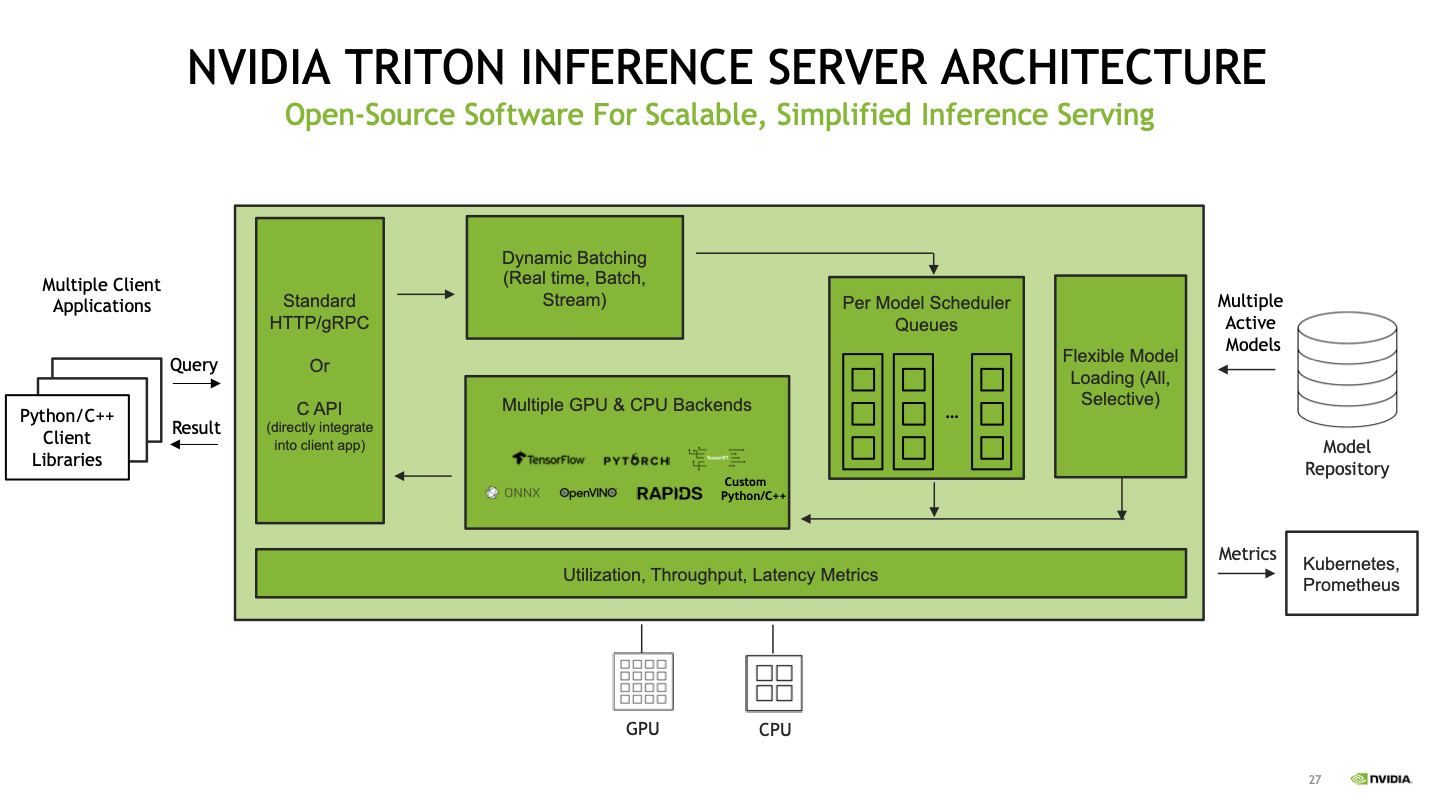
Fig. 59 Nvidia Triton Architecture#
这个inference server, 推理服务器 支持多种模型格式,如PyTorch、TensorFlow、ONNX、TensorRT等。它有效地利用GPU来提升深度学习模型的性能。
-
并发模型执行(Concurrent model execution):这允许在一个或多个GPU上并行执行多个模型。多个请求,被路由到每个模型以并行执行任务。
-
动态批处理(Dynamic Batching):将多个推理请求
组合成一个批次,以增加吞吐量。每个批次中的请求可以并行处理,而不是按顺序处理每个请求。
Pros:
-
High throughput, low latency for serving LLMs on a GPU
-
Supports multiple frameworks/backends
-
Production level performance
-
Works with non-LLM models such as image generation or speech to text
Cons:
-
Difficult to set up
-
Not compatible with many of the newer LLMs
Text Generation Inference#
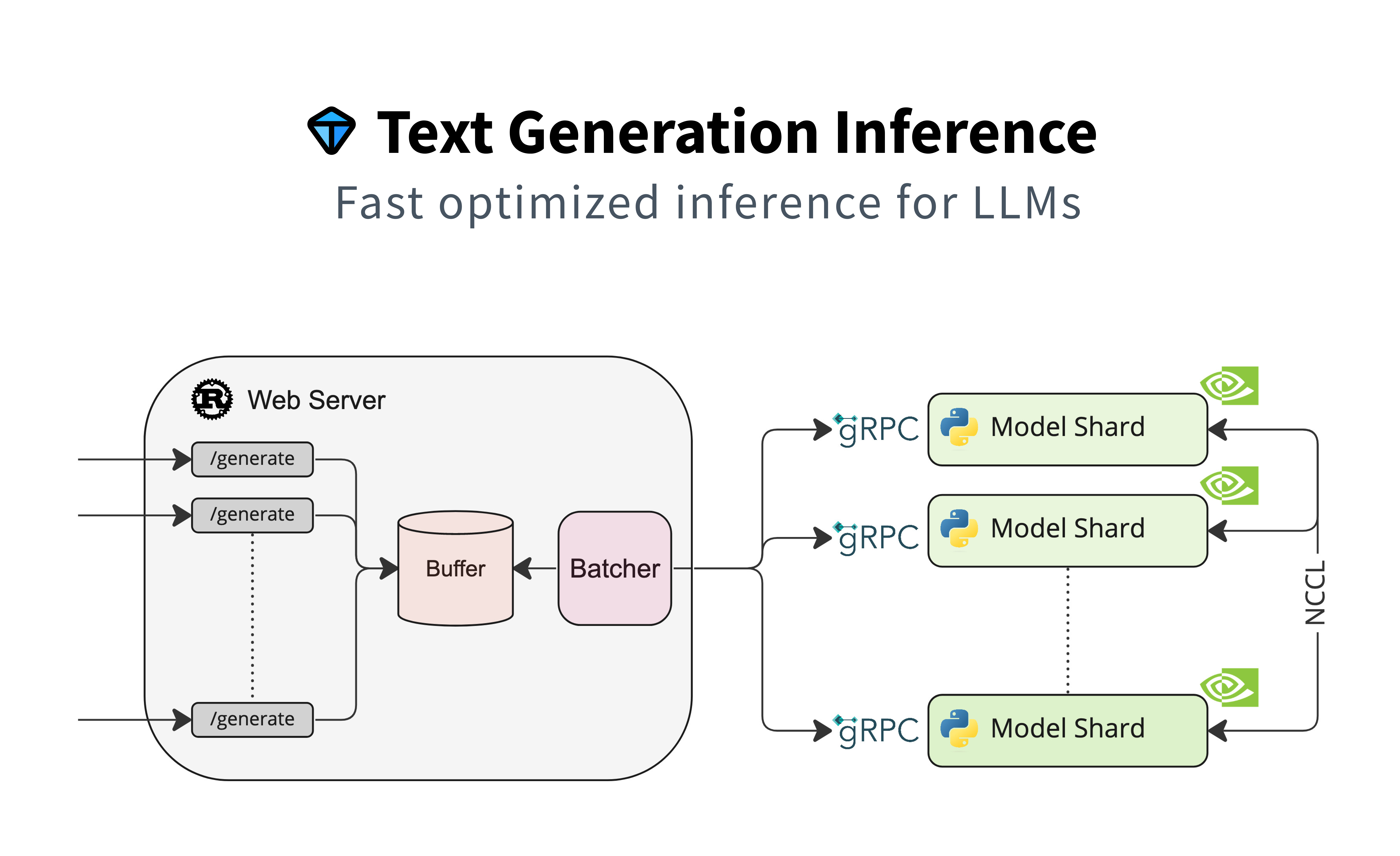
Fig. 60 Text Generation Inference Architecture#
Compared to Triton, huggingface/text-generation-inference is easier to setup and supports most of the popular LLMs on Hugging Face.
Pros:
-
Supports newer models on Hugging Face
-
Easy setup via docker container
-
Production-ready
Cons:
-
Open-source license has restrictions on commercial usage
-
Only works with Hugging Face models
vLLM#
This is an open-source project created by researchers at Berkeley to improve the performance of LLM inferencing. vLLM primarily optimises LLM throughput via methods like PagedAttention and Continuous Batching. The project is fairly new and there is ongoing development.
Pros:
-
Can be used commercially
-
Supports many popular Hugging Face models
-
Easy to setup
Cons:
- Not all LLM models are supported
BentoML#
BentoML is a fairly popular tool used to deploy ML models into production. It has gained a lot of popularity by building simple wrappers that can convert any model into a REST API endpoint. Currently, BentoML does not support some of the GPU optimizations such as tensor parallelism. However, the main benefit BentoML provides is that it can serve a wide variety of models.
Pros:
-
Easy setup
-
Can be used commercially
-
Supports all models
Cons:
- Lacks some GPU optimizations
张量并行(tensor parallelism),是指在深度学习模型中,同时处理和计算多个张量数据的能力。
- 这种技术允许模型同时对多个张量执行操作和计算,以提高训练速度和效率。
- 通过并行处理张量,可以更有效地利用硬件资源(如GPU或多个GPU),加快模型的训练过程,并提升整体性能。
Modular#
Modular is designed to be a high performance AI engine that boosts the performance of deep learning models. The secret is in their custom compiler and runtime environment that improves the inferencing of any model without the developer needing to make any code changes.
The Modular team has designed a new programming language, Mojo, which combines the Python friendly syntax with the performance of C. The purpose of Mojo is to address some of the shortcomings of Python from a performance standpoint while still being a part of the Python ecosystem. This is the programming language used internally to create the Modular AI engine’s kernels.
Pros:
-
Low latency/High throughput for inference
-
Compatible with Tensorflow and Pytorch models
Cons:
-
Not open-source
-
Not as simple to use compared to other engines on this list
This is not an exhaustive list of MLOps engines by any means. There are many other tools and frameworks developer use to deploy their ML models. There is ongoing development in both the open-source and private sectors to improve the performance of LLMs. It’s up to the community to test out different services to see which one works best for their use case.
LocalAI#
LocalAI from mudler/LocalAI (not to be confused with local.ai from louisgv/local.ai) is the free, Open Source alternative to OpenAI. LocalAI act as a drop-in replacement REST API that’s compatible with OpenAI API specifications for local inferencing. It can run LLMs (with various backend such as ggerganov/llama.cpp or vLLM), generate images, generate audio, transcribe audio, and can be self-hosted (on-prem) with consumer-grade hardware.
Pros:
-
support for functions (self-hosted OpenAI functions)
Cons:
-
binary version is harder to run and compile locally. mudler/LocalAI#1196.
-
high learning curve due to high degree of customisation
Challenges in Open Source#
MLOps solutions come in two flavours [144]:
-
Managed: a full pipeline (and support) is provided (for a price)
-
Self-hosted: various DIY stitched-together open-source components
Some companies (e.g. Hugging Face) push for open-source models & datasets, while others (e.g. OpenAI, Anthropic) do the opposite.
The main challenges with open-source MLOps are Maintenance, Performance, and Cost.

Fig. 61 Open-Source vs Closed-Source MLOps#
Maintenance#
使用开源组件,大部分的设置和配置必须手动完成。
- 这可能包括查找和下载
模型models和数据集datasets,设置微调fine-tuning,执行评估evaluations和推理Inference等, - 所有这些组件,由自行维护的定制“粘合”代码,连接在一起。
需要负责监控管道pipeline的运行情况,并迅速解决问题,以避免应用程序的停机。特别是在项目的早期阶段,当鲁棒性和可伸缩性尚未实施时,开发人员需要进行大量的问题排查工作。
Performance#
Performance could refer to:
-
output quality: e.g. accuracy – how close is a model’s output to ideal expectations (see Evaluation & Datasets), or
-
operational speed: e.g. throughput & latency – how much time it takes to complete a request (see also Hardware, which can play as large a role as software [145]).
By comparison, closed-source engines (e.g. Cohere) tend to give better baseline operational performance due to default-enabled inference optimisations [146].
Cost#
自行维护的开源解决方案,如果实施得当,无论是在设置还是长期运行方面,都可以非常便宜。然而,许多人低估了使开源生态系统无缝运行所需的工作量。
例如,一个能够运行一个36GB开源模型的单个GPU节点,从主要云提供商那里很容易每月花费超过2000美元。由于这项技术仍然很新,尝试和维护自托管基础设施可能会很昂贵。相比之下,封闭源的价格模型通常根据使用(例如令牌)而不是基础设施(例如ChatGPT每千个令牌的费用约为0.002美元,足够用于一页文本),使它们在小规模的探索性任务中更便宜。
Inference#
推理是当前LLMs领域的热门话题之一。像ChatGPT这样的大型模型具有非常低的延迟和出色的性能,但随着使用量的增加,成本也会更高。
与此相反,像LLaMA-2或Falcon这样的开源模型有更小的变体,但很难在仍然具有成本效益的同时,匹配ChatGPT提供的延迟和吞吐量 [147]。
使用Hugging Face管道运行的模型,没有必要的优化来在生产环境中运行。开源LLM推理市场仍在不断发展,所以目前还没有能以高速运行任何开源LLM的灵丹妙药。
推理 inference 速度慢,一般是下面几个原因:
Models are growing larger in size#
- 模型越大,神经网络(
neural networks)执行速度也就越慢。
Python as the choice of programming language for AI#
-
Python, is inherently slow compared to compiled languages like C++
-
The developer-friendly syntax and vast array of libraries have put Python in the spotlight, but when it comes to sheer performance it falls behind many other languages
-
To compensate for its performance many inferencing servers convert the Python code into an optimised module. For example, Nvidia’s Triton Inference Server can take a PyTorch model and compile it into TensorRT, which has a much higher performance than native PyTorch
-
Similarly, ggerganov/llama.cpp optimises the LLaMA inference code to run in raw C++. Using this optimisation, people can run a large language model on their laptops without a dedicated GPU.
相比于像C++这样的编译型语言,Python天生速度较慢。
- Python是一种解释型语言,而不是编译型语言。
- 解释型语言需要在运行时逐行解释代码,这使得它在某些情况下的执行速度相对较慢。
- 相比之下,编译型语言在运行前会先将代码转换成机器语言,这通常会带来更高的执行效率。
- 尽管Python的速度较慢,但其简单易用、灵活性和广泛的库支持使其成为数据分析、机器学习等领域中流行的语言之一。
Larger inputs#
-
Not only do LLMs have billions of parameters, but they perform millions of mathematical calculations for each inference
-
To do these massive calculations in a timely manner, GPUs are required to help speed up the process. GPUs have much more memory bandwidth and processing power compared to a CPU which is why they are in such high demand when it comes to running large language models.
Future#
由于运行大型语言模型(LLMs)存在挑战/门槛,企业可能选择使用推理服务器而不是自行将模型容器化/本地化。LLMs推理优化,需要高水平的专业知识,而大多数公司可能并不具备。推理服务器可以通过提供简单且统一的界面,并且规模化部署AI模型,来获得成本优势。
另一个正在出现的模式是,模型将移至数据所在地,而不是将数据传输到模型中。目前,在调用ChatGPT API时,数据被发送到模型。在过去的十年中,企业努力在云中建立了稳健的数据基础设施。将模型引入到与数据相同的云环境中更为合理。这就是开源模型,具备云无关性的巨大优势所在。
在“MLOps”这个词出现之前,数据科学家通常会在本地手动训练和运行模型。那时,数据科学家主要是在实验较小规模的统计模型。当他们试图将这项技术应用于生产时,他们遇到了许多与数据存储、数据处理、模型训练、模型部署和模型监控相关的问题。公司开始解决这些挑战,并提出了“MLOps”来运行AI模型的解决方案。
目前,我们处于LLMs的实验阶段。当公司尝试将这项技术应用于生产时,他们将面临一系列新的挑战。解决这些挑战的方案,将基于现有的MLOps概念,同时也可能诞生新的领域知识。
原文地址:https://ningg.top/ai-series-prem-08-mlops-engines/