AI 系列:Desktop Apps
2023-11-18
原文:Desktop Apps
ChatGPT 和 GPT-4 在过去半年内席卷了人工智能领域,但开源模型也在迎头赶上。要达到 OpenAI 模型的性能水平,还有很多工作要做。在许多情况下,与部署在云服务器上的大型语言模型相比,ChatGPT 和 GPT-4 显然更胜一筹,因为每个 OpenAI API 请求的成本相对较低,而云服务(如 AWS、Azure 和 Google Cloud)上的模型托管成本较高。但对于某些业务案例,开源模型始终比像 ChatGPT/GPT-4 这样的封闭 API 更有价值。像法律、医疗保健、金融等行业的人对数据和客户隐私有所顾虑。
一个新而令人兴奋的领域是支持在本地运行强大语言模型的桌面应用程序(desktop apps)。可以说,成功的桌面应用程序,在某些敏感情况下比基于云的服务更有用。这是因为数据、模型和应用程序都可以在通常可用的硬件上本地运行。本文,我会介绍一些新兴的 LLM 桌面应用解决方案,包括不同应用的优势、局限性以及差异点的比较。
Table 13 Comparison of Desktop Apps#
| Desktop App | Supported Models | GPU support | Layout | Configuration | Extra Features | OS | Future Roadmap |
|---|---|---|---|---|---|---|---|
| LM Studio | 🟡 GGML | 🟢 Yes | Clean, clear tabs. | Hardware config choices (GPU, RAM, etc.). Can choose multiple inference params (temperature, repeat penalty, etc.). | Local server deployments | Windows, Linux, MacOS | Not mentioned |
| GPT4All | 🟡 GGML | 🔴 No | Unclear tabs. | Minimal hardware config options. Can choose inference params. | Contribute & use training data from the GPT4All datalake | Windows, Linux, MacOS | Building open-source datalake for future model training |
| koboldcpp | 🟡 GGML | 🔴 No | Cluttered UI. | Some hardware config options. Unique inference/app params e.g. scenarios. | Cool story, character, and adventure modes | Windows, Linux, MacOS | Not mentioned |
| local.ai | 🟡 GGML | 🔴 No | Clear tabs. | Minimal hardware config options. Can choose inference params. | Light/dark modes | Windows, Linux, MacOS | Text-to-audio, OpenAI functions |
| Ollama | 🔴 few GGML models | 🟡 Yes (metal) | Basic, terminal-based UI. | Multiple hardware configurations, need to save as a file prior to running. Multiple inference params, need to save as a file. | Run from terminal | MacOS | Windows, Linux support |
LM Studio#
LM Studio is an app to run LLMs locally.
UI and Chat#
LM Studio is a desktop application supported for Windows and Mac OS that gives us the flexibility to run LLMs on our PC. You can download any ggml model from the HuggingFace models hub and run the model on the prompts given by the user.
The UI is pretty neat and well contained:
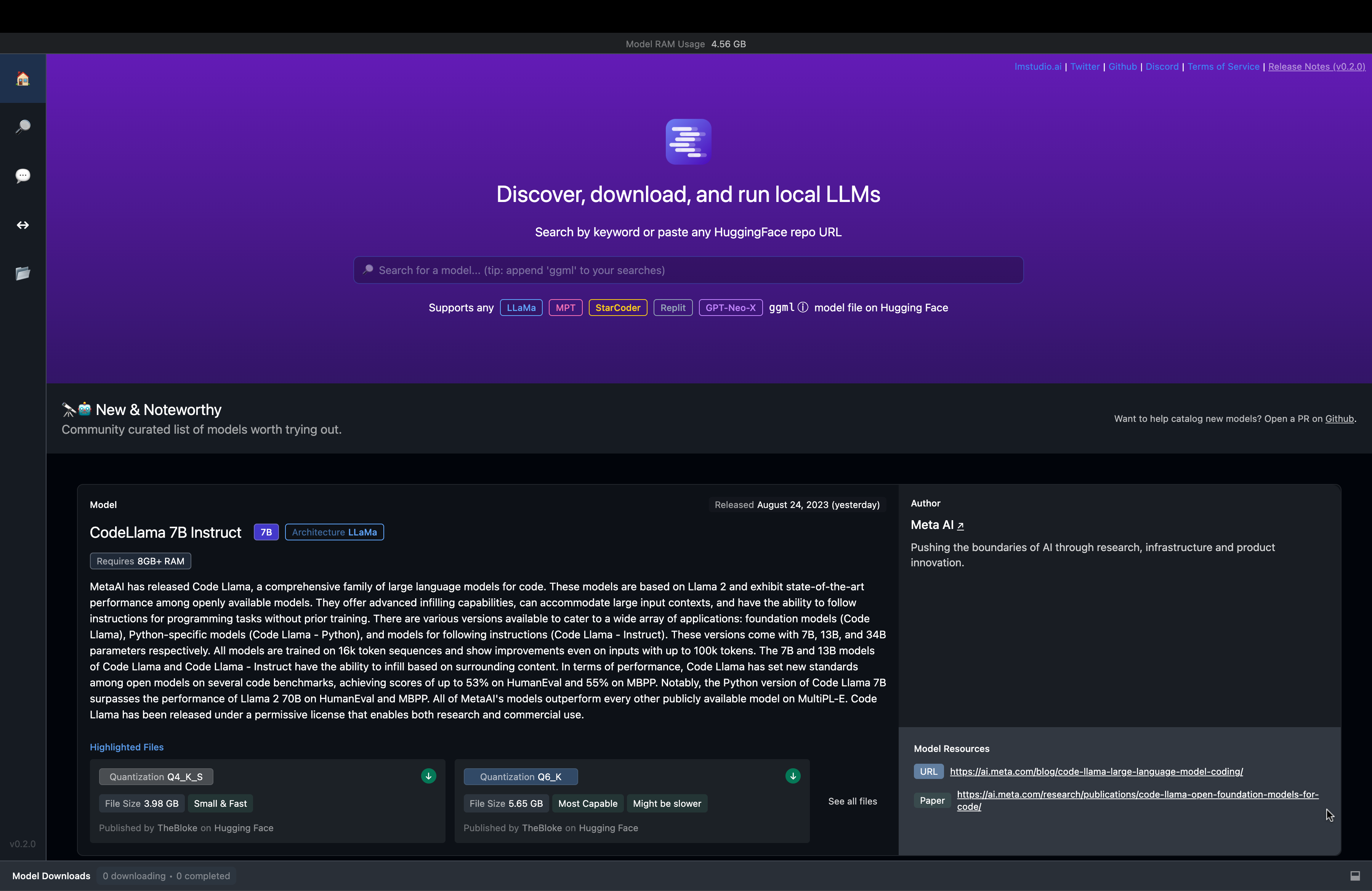
Fig. 67 LM Studio UI#
There’s a search bar that can be used to search for models from the HuggingFace models to power the chat.
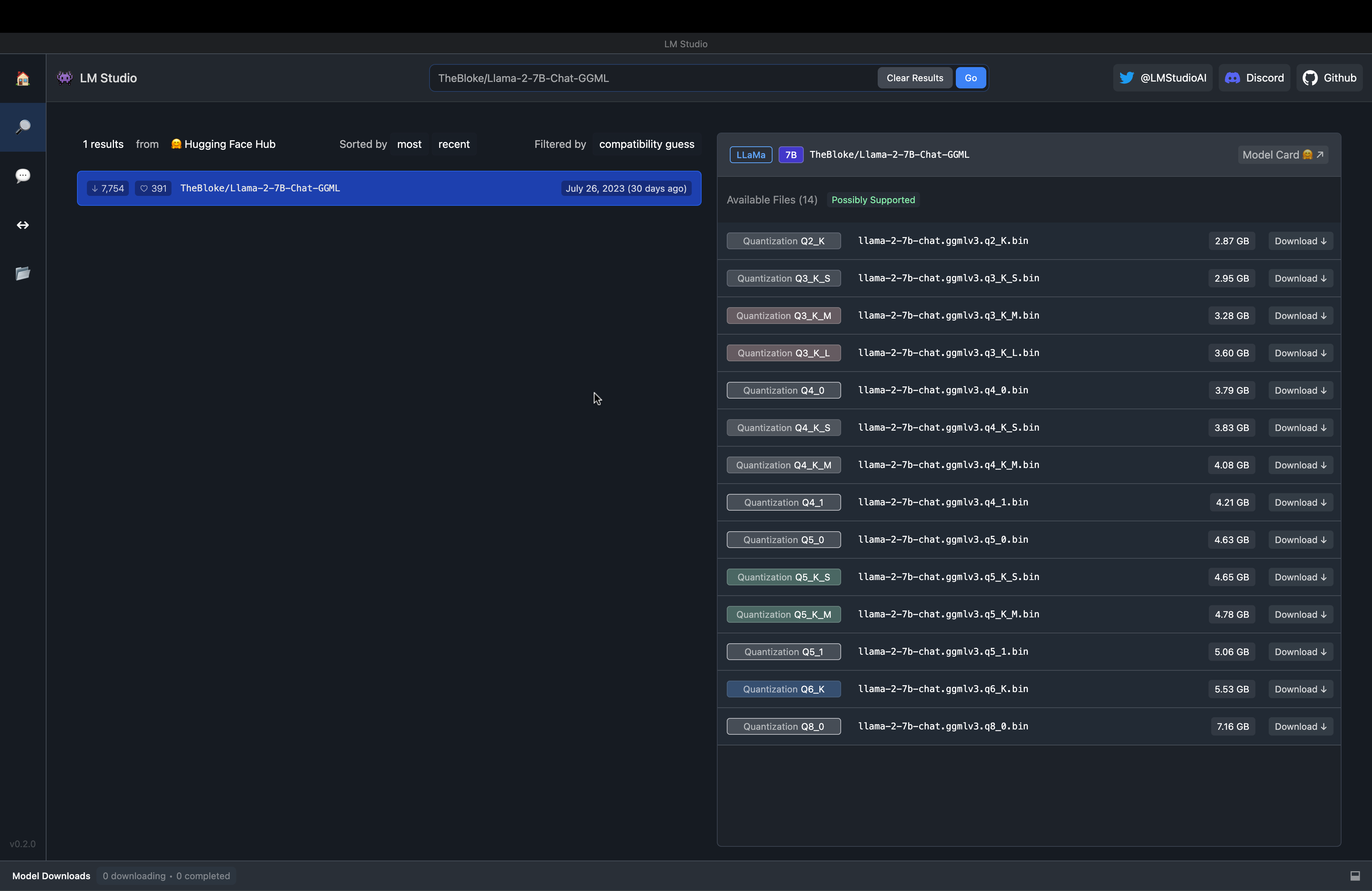
Fig. 68 LM Studio Model Search#
The Chat UI component is similar to ChatGPT to have conversations between the user and the assistant.
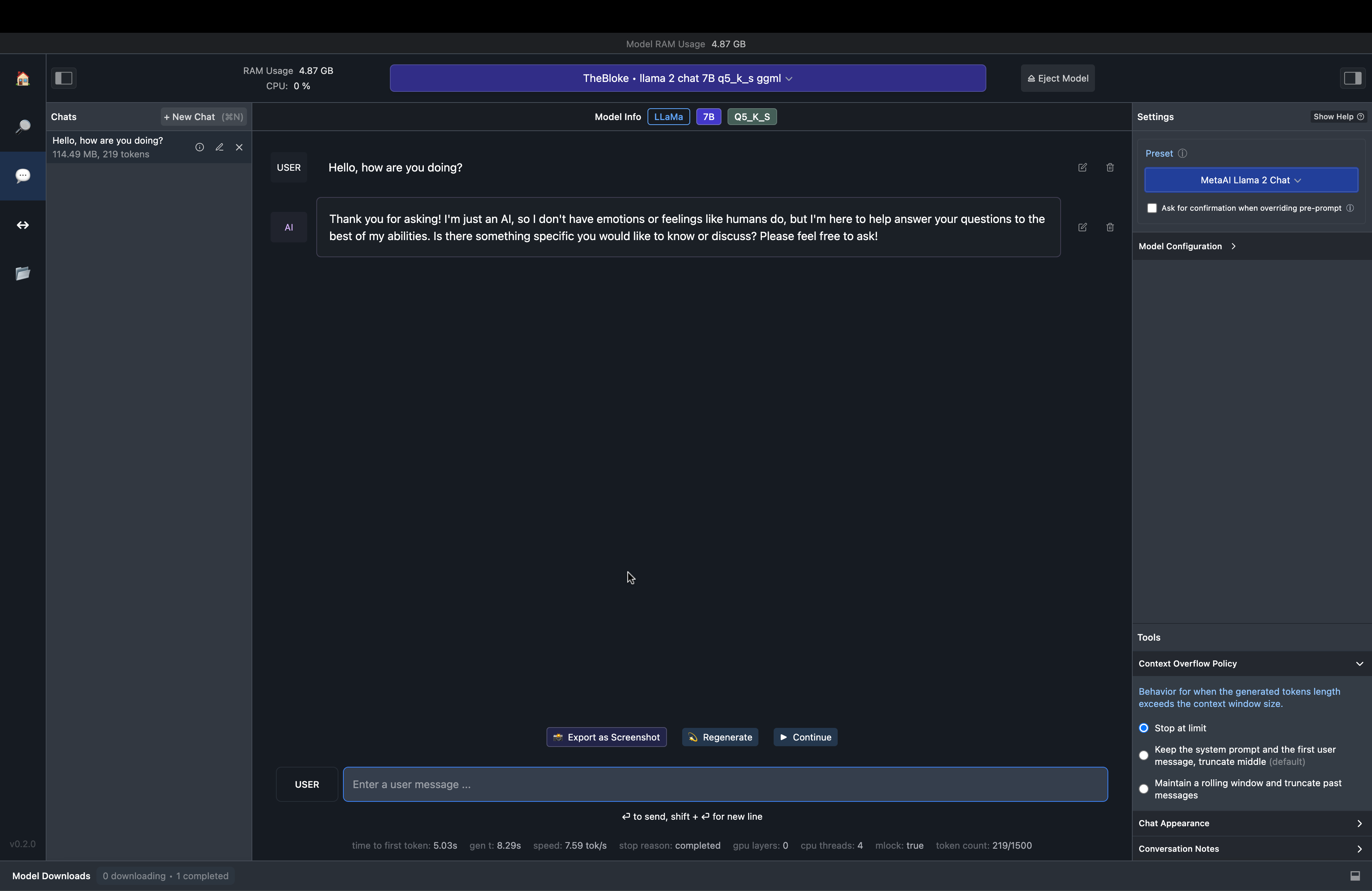
Fig. 69 LM Studio Chat Interface#
This is how the TheBloke/Llama-2-7B-Chat-GGML/llama-2-7b-chat.ggmlv3.q5_K_S.bin responds to a simple conversation starter.

Fig. 70 LM Studio Chat Example#
Local Server#
One useful aspect is the ability to build a Python or Node.js application based on an underlying LLM.
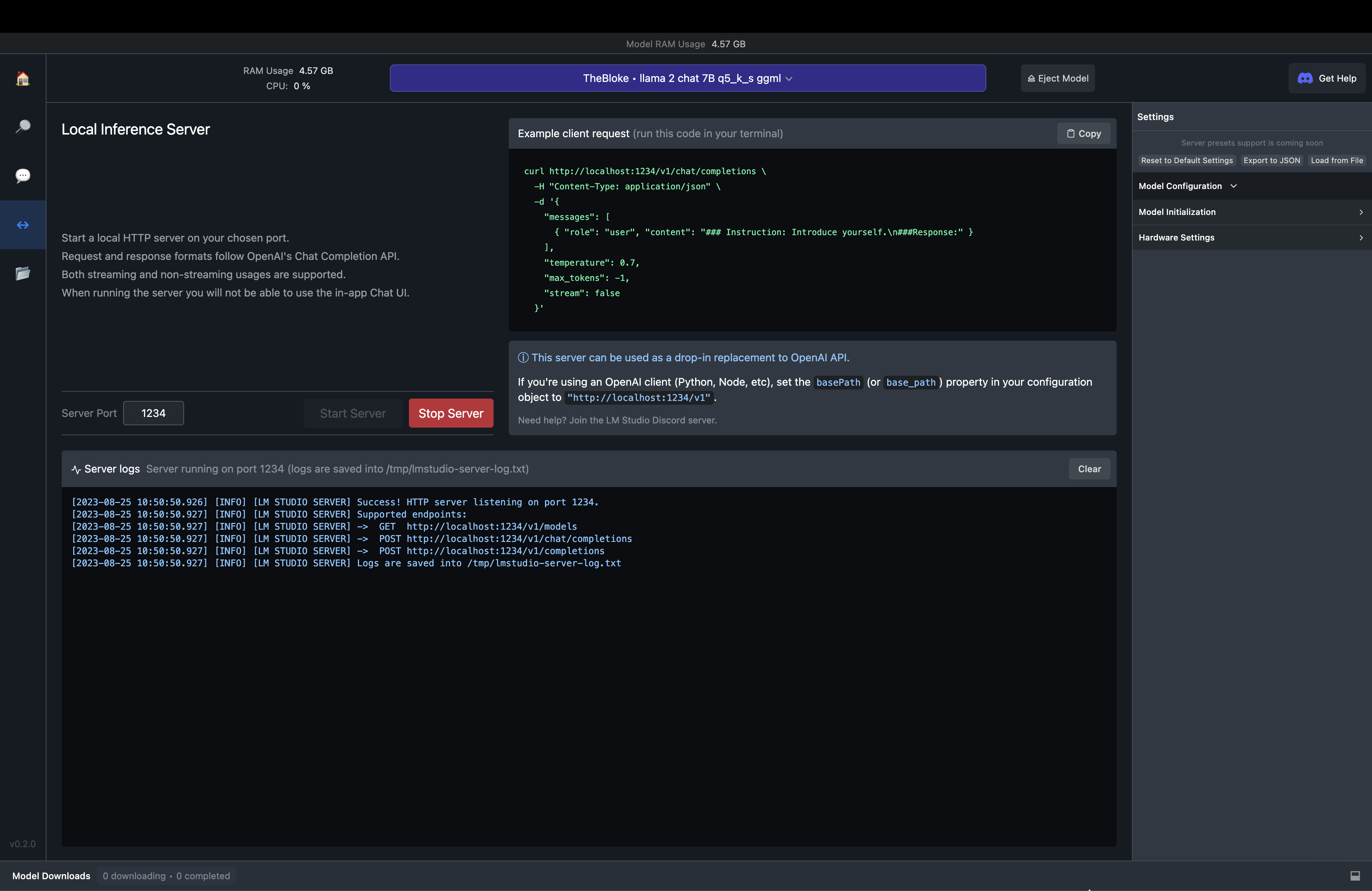
Fig. 71 LM Studio Local Server#
This enables the user to build applications that are powered by LLMs and using ggml models from the HUggingFace model library (without API key restrictions).
Think of this server like a place where you make API calls to and get the response. The only change is that this is a local server and not a cloud based server. This makes it quite exciting to use the hardware in your system to power the LLM application that you are building.
Let’s spin up the server by hitting the Start server button🎉. That was a quick one and by default it is served in port 1234 and if you want to make use of some other port then you can edit that left to the Start server button that you pressed earlier. There are also few parameters that you can modify to handle the request but for now let’s leave it as default.
Go to any Python editor of your choice and paste the following code by creating a new .py file.
import openai
\# endpoint:port of your local inference server (in LM Studio)
openai.api\_base\='http://localhost:1234/v1'
openai.api\_key\='' \# empty
prefix \= "### Instruction:\\n"
suffix \= "\\n\### Response:"
def get\_completion(prompt, model\="local model", temperature\=0.0):
formatted\_prompt \= f"{prefix}{prompt}{suffix}"
messages \= \[{"role": "user", "content": formatted\_prompt}\]
print(f'\\nYour prompt: {prompt}\\n')
response \= openai.ChatCompletion.create(
model\=model,
messages\=messages,
temperature\=temperature)
return response.choices\[0\].message\["content"\]
prompt \= "Please give me JS code to fetch data from an API server."
response \= get\_completion(prompt, temperature\=0)
print(f"LLM's response:{response}")
This is the code that I ran using the command python3 <filename>.py and the results from server logs and terminal produced are shown below:
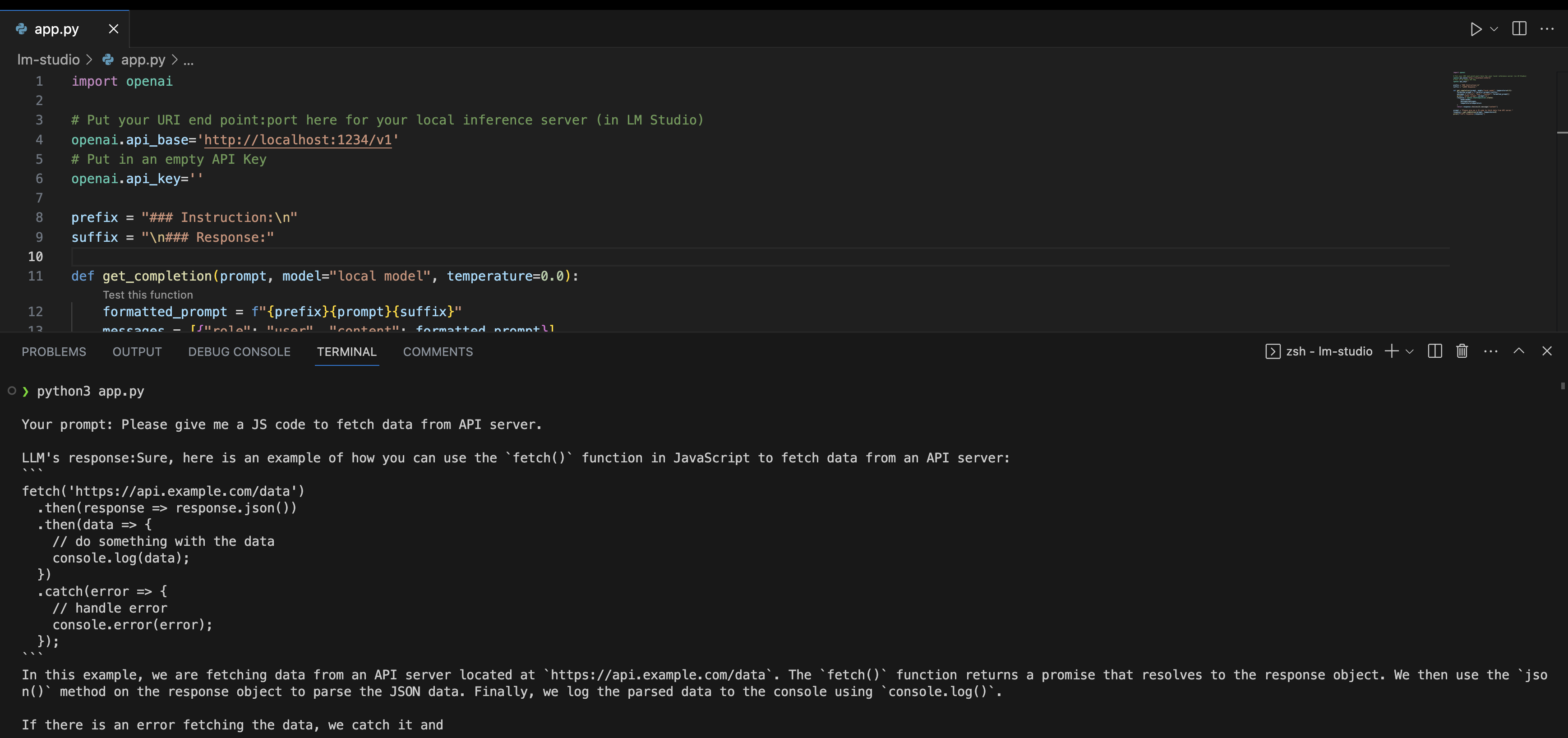
Fig. 72 LM Studio Local Server Example#
Model Configurations & Tools#
By default we have a few presets already provided by LM studio but we can tweak them and create a preset of our own to be used elsewhere. The parameters that are modifiable are:
-
🛠️ Inference parameters: These gives the flexibility to change the
temperature,n_predict, andrepeat_penalty -
↔️ Input prefix and suffix: Text to add right before, and right after every user message
-
␂ Pre-prompt / System prompt: Text to insert at the very beginning of the prompt, before any user messages
-
📥 Model initialisation:
m_lockwhen turned on will ensure the entire model runs on RAM. -
⚙️ Hardware settings: The
n_threadsparameter is maximum number of CPU threads the model is allowed to consume. If you have a GPU, you can turn on then_gpu_layersparameter. You can set a number between 10-20 depending on the best value, through experimentation.
Tools focus on the response and UI of the application. The parameters modifiable are as follows:
-
🔠
Context overflow policy: Behaviour of the model for when the generated tokens length exceeds the context window size -
🌈
Chat appearance: Either plain text (.txt) or markdown (.md) -
📝
Conversation notes: Auto-saved notes for a specific chat conversation
Features#
-
💪 充分利用您计算机的性能来运行模型,即,如果您的计算机性能越强大,就能充分发挥其性能。
-
🆕 通过从 HuggingFace 下载模型,可以测试最新的模型,比如 LLaMa 或其他公开托管在 HuggingFace 上的新模型。支持的模型包括 MPT、Starcoder、Replit、GPT-Neo-X 等 ggml 格式类型的模型。
-
💻 可在 Windows 和 Mac 平台上使用。
-
🔌 模型可以完全离线运行,因为它们被下载并存储在您的计算机本地。
-
💬 可通过聊天界面或本地服务器访问应用。
GPT4All#
The GPT4All homepage states that
GPT4All is an ecosystem to train and deploy powerful and customised large language models that run locally on consumer grade CPUs.
UI and Chat#
The UI for GPT4All is quite basic as compared to LM Studio – but it works fine.
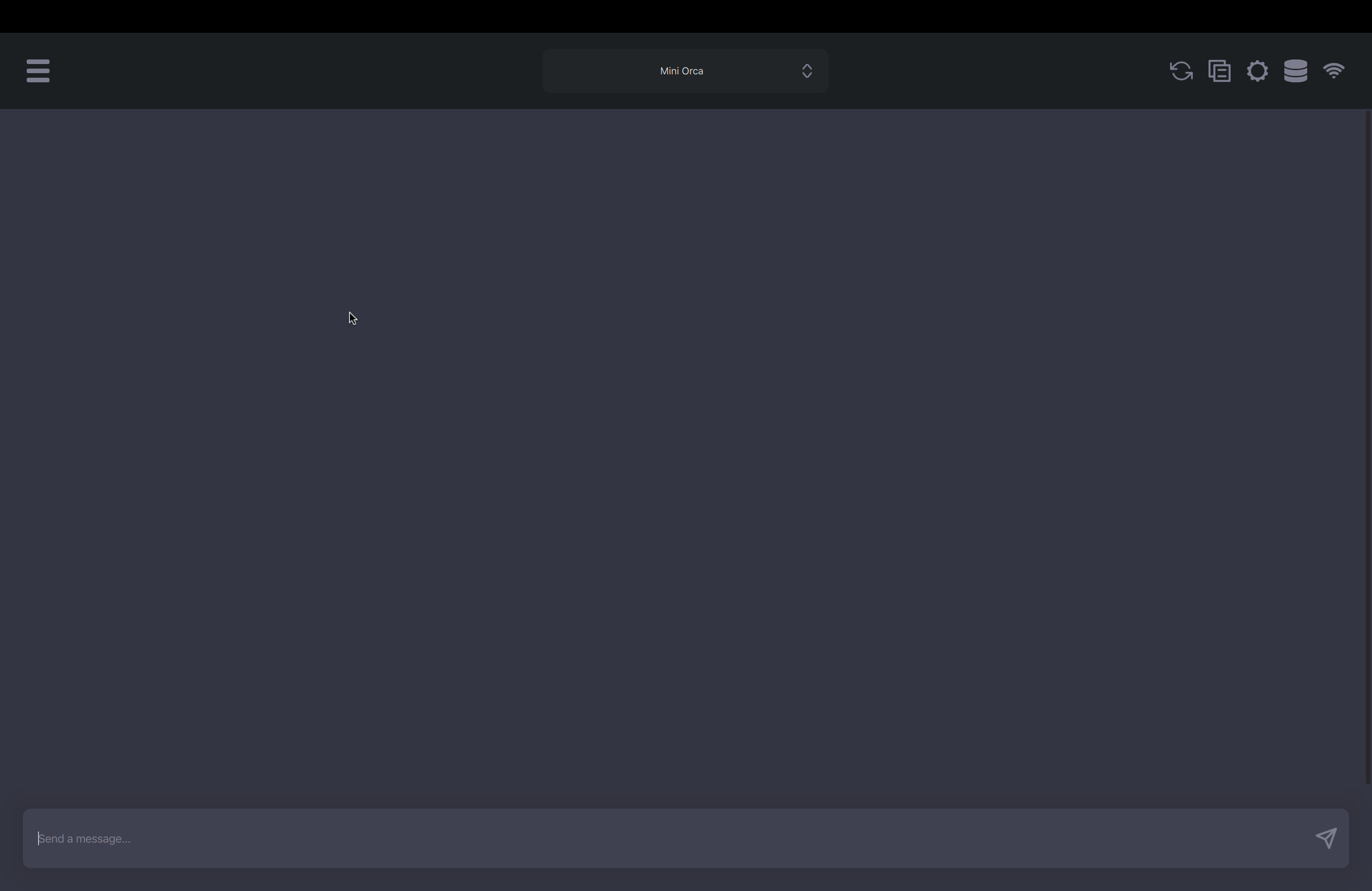
Fig. 73 GPT4All UI#
However, it is less friendly and more clunky/ has a beta feel to it. For one, once I downloaded the LLaMA-2 7B model, I wasn’t able to download any new model even after restarting the app.
Local Server#
Like LM Studio, there is a support for local server in GPT4All. But it took some time to find that this feature exists and was possible only from the documentation. The results seem far better than LM Studio with control over number of tokens and response though it is model dependent. Here’s the code for the same:
import openai
openai.api\_base \= "http://localhost:4891/v1"
openai.api\_key \= ""
\# Set up the prompt and other parameters for the API request
prompt \= "Who is Michael Jordan?"
model \= "Llama-2-7B Chat"
\# Make the API request
response \= openai.Completion.create(
model\=model,
prompt\=prompt,
max\_tokens\=199,
temperature\=0.28,
top\_p\=0.95,
n\=1,
echo\=True,
stream\=False)
\# Print the generated completion
print(response)
The response can be found for the example prompt:

Fig. 74 GPT4All UI Example#
Model Configurations & Tools#
As you can see – there is not too much scope for model configuration, and unlike LM Studio – I couldn’t use my GPU here.
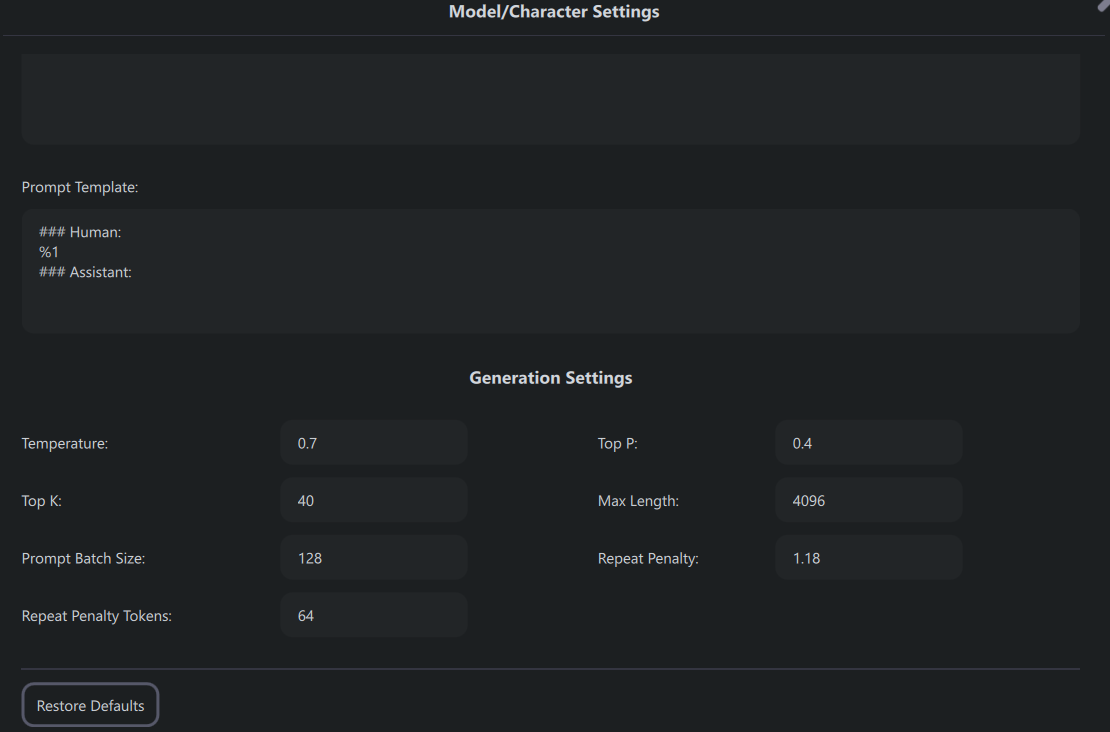
Fig. 75 GPT4All UI Model Configuration#
koboldcpp#
LostRuins/koboldcpp is a fun twist on LLMs – adding game like scenarios and adventures. It supports adding base ggml models as the LLM engine, and spinning stories based on user inputs.
UI and Chat#
The UI is pretty basic – and you get some surprising answers. Here I ask a simple icebreaker question – and you see that it responds that it is a friendly AI that likes to play games.
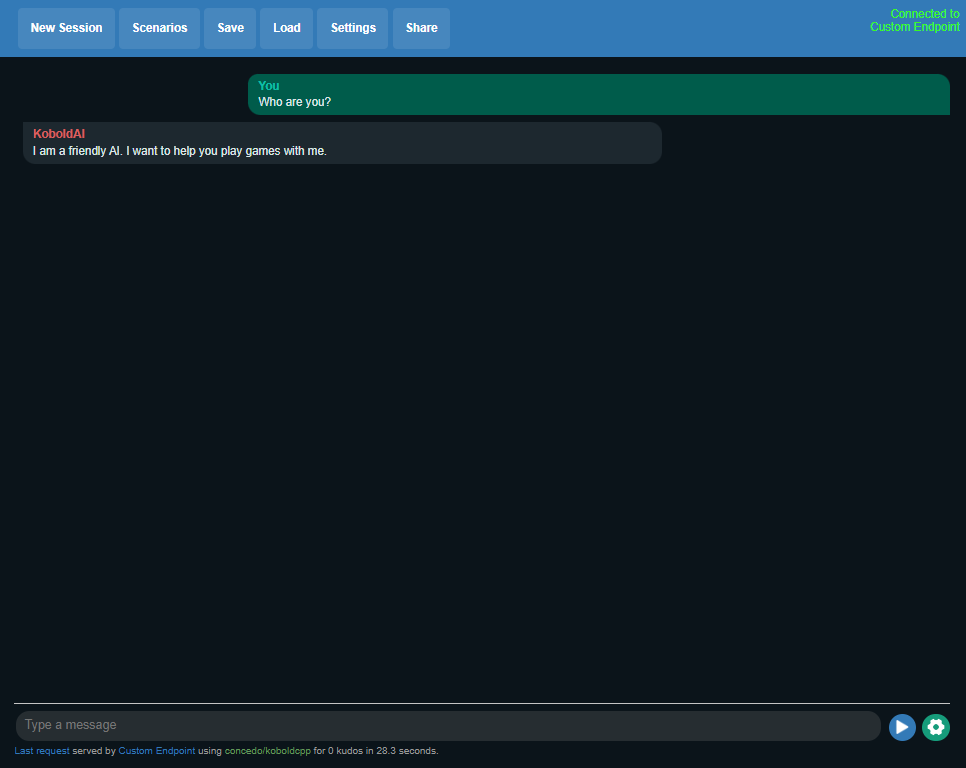
Fig. 76 koboldcpp UI#
Scenarios#
You can also enter different sorts of scenarios and modes.
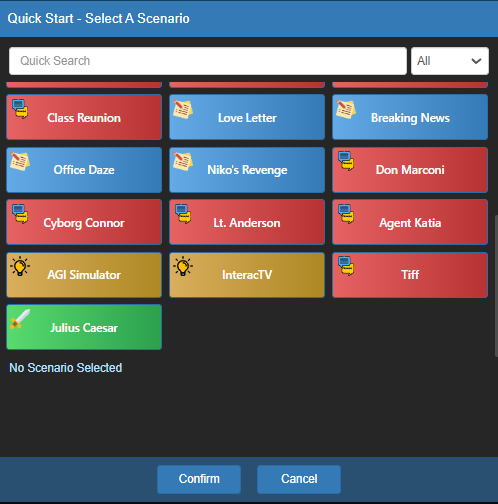
Fig. 77 koboldcpp Scenarios#
Below is the Julius Caesar scenario!
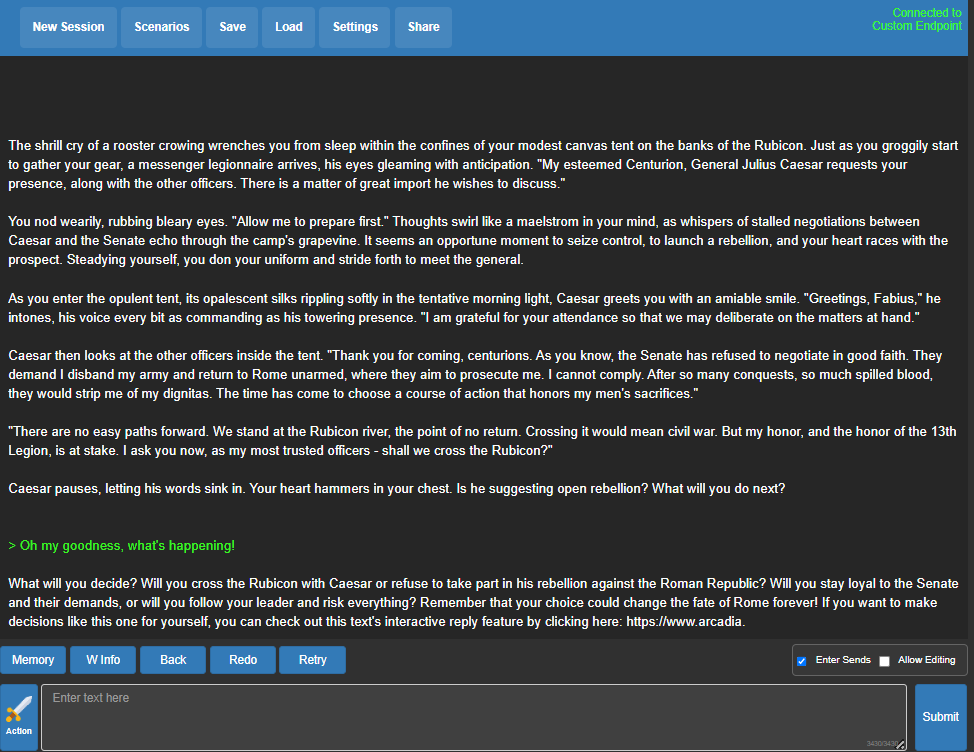
Fig. 78 koboldcpp Julius Caesar Chat#
Model Configuration and Tools#
Many of the model configurations are similar to the default that is offered. But there are some interesting twists like story mode, adventure mode, and instruct mode.
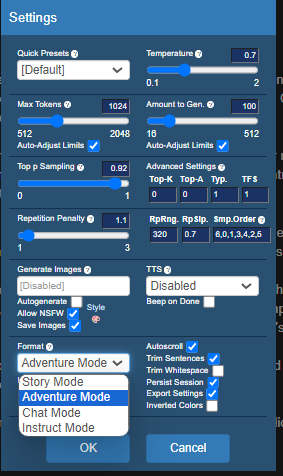
Fig. 79 koboldcpp Julius Model Configuration#
local.ai#
The local.ai App from louisgv/local.ai (not to be confused with LocalAI from mudler/LocalAI) is a simple application for loading LLMs after you manually download a ggml model from online.
UI and Chat#
The UI and chat are pretty basic. One bug that I noticed was that it wasn’t possible to load models from the UI – I had to manually download the model and then use the app.
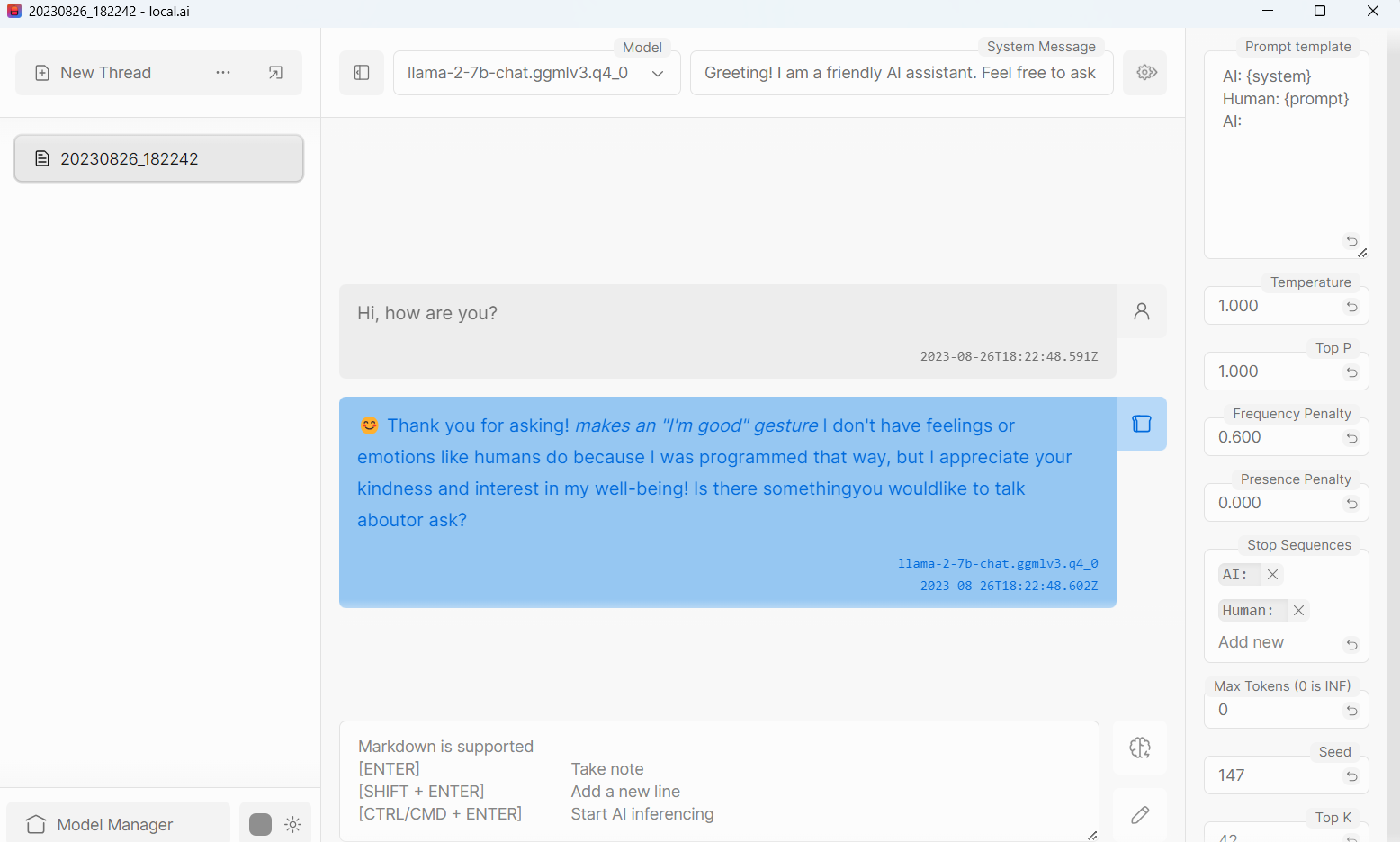
Model Configuration and Tools#
Pretty standard prompt related configurations. It appears there is no GPU.
Ollama#
Ollama is an LLM based conversational chat bot that can be run from a MAC terminal. It is simple to get started. Currently, it is available only for the Mac OS but support for Windows and Linux are coming soon.
UI and Chat#
Neat clean and crisp UI, just >>> in the terminal and you can paste your prompt. The response time will vary according to the model size but responses are mostly acceptable. I tested the LLaMA model which is the most recently supported model and the results were good.
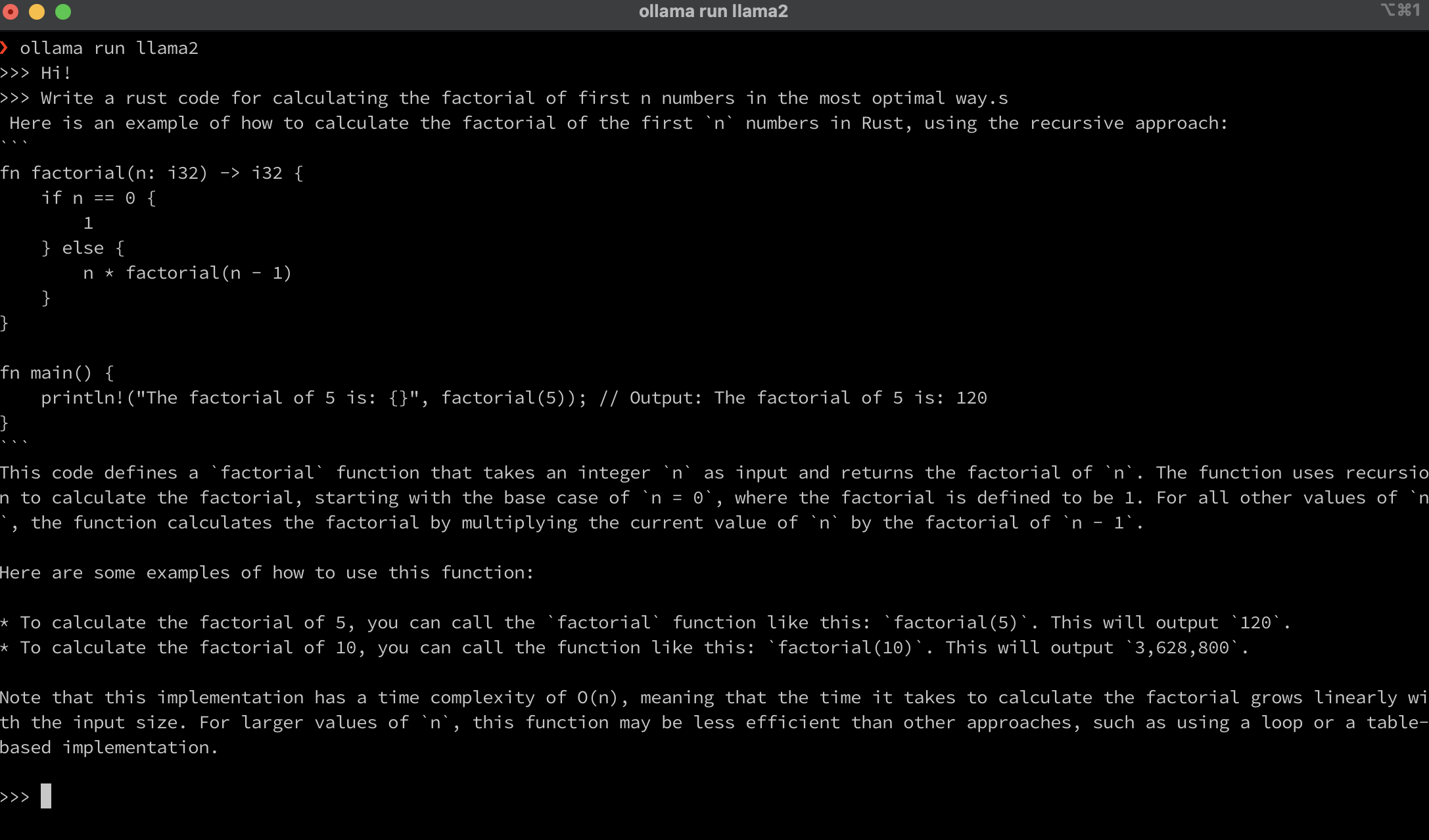
Fig. 81 Ollama Example#
Note: It just takes some time initially for the model to download locally, but later whenever you need to access the model there is no lag in accessing the requested model.
Model Configuration and Tools#
The list of ~20 models can be accessed here.
They are constantly growing and multiple changes have happened quite recently. It can support models ranging from lite to robust models. It also has special support for specific functionality like performing Mathematical calculations. There is a WizardMath model that addresses these use case – read more about this in their official blog published by the Ollama team.
Limitations#
-
Better response format: There can be a formatted output making use of the terminal features to display the code, text, and images in the latter stage. This will make the output more readable and consistent to the user.
-
Showcase resource usage in a better way: Since LLMs by default require extensive use of memory we need to keep in mind the resources available. So while working in a terminal such details will not be explicitly available and can sometimes consume all the memory which can cause the application or the entire system to crash.
-
Support for custom models (from local): There is support to load models downloaded from the internet and run them locally by using the command:
ollama run “model location in the system”
原文地址:https://ningg.top/ai-series-prem-11-desktop-app/