Chapter 4: Reflection¶
第四章:反思(Reflection)
Reflection Pattern Overview¶
反思模式概览¶
In the preceding chapters, we've explored fundamental agentic patterns: Chaining for sequential execution, Routing for dynamic path selection, and Parallelization for concurrent task execution. These patterns enable agents to perform complex tasks more efficiently and flexibly. However, even with sophisticated workflows, an agent's initial output or plan might not be optimal, accurate, or complete. This is where the Reflection pattern comes into play.
前几章介绍了顺序链式执行、动态路径路由与任务并行化等基础模式,使智能体在处理复杂任务时更高效、更灵活。但即便工作流设计得再完善,首版输出或初始计划仍可能不够准确、不够完整,或
尚未达到最优,这时就需要依靠反思机制来补强。
The Reflection pattern involves an agent evaluating its own work, output, or internal state and using that evaluation to improve its performance or refine its response. It's a form of self-correction or self-improvement, allowing the agent to iteratively refine its output or adjust its approach based on feedback, internal critique, or comparison against desired criteria. Reflection can occasionally be facilitated by a separate agent whose specific role is to analyze the output of an initial agent.
反思(Reflection),是指智能体对自身的产出或过程进行评估,再利用评估结果修正答案、调整策略,属于一种自我纠错与自我改进机制:它可以依据外部反馈、内部批评,或与目标标准之间的偏差不断迭代。实践中,这一步也常由另一个「专职审阅」的智能体来承担。
Unlike a simple sequential chain where output is passed directly to the next step, or routing which chooses a path, reflection introduces a feedback loop. The agent doesn't just produce an output; it then examines that output (or the process that generated it), identifies potential issues or areas for improvement, and uses those insights to generate a better version or modify its future actions.
不同于「输出直接传给下一环」的朴素链式,也不同于单纯路由,
反思显式引入反馈环(Feedback Loop):不只生成一版结果,还要回头看结果(乃至生成过程),标出问题与改进点,再产出修订版或改写后续动作。
The process typically involves:
该过程通常包括:
- Execution: The agent performs a task or generates an initial output.
- Evaluation/Critique: The agent (often using another LLM call or a set of rules) analyzes the result from the previous step. This evaluation might check for factual accuracy, coherence, style, completeness, adherence to instructions, or other relevant criteria.
- Reflection/Refinement: Based on the critique, the agent determines how to improve. This might involve generating a refined output, adjusting parameters for a subsequent step, or even modifying the overall plan.
- Iteration (Optional but common): The refined output or adjusted approach can then be executed, and the reflection process can repeat until a satisfactory result is achieved or a stopping condition is met.
- 执行: 完成任务或给出初稿。
- 评估/批评: 再调一次模型(或走规则引擎)审视上一步产物,核对事实、连贯、风格、完整度、是否遵循提示等。
- 反思/精炼: 据批评决定怎么改——重写、调参、乃至推翻原计划。
- 迭代(可选但常见): 带着新版本再跑执行—批评—精炼,直到达标或触发停止条件。
A key and highly effective implementation of the Reflection pattern separates the process into two distinct logical roles: a Producer and a Critic. This is often called the "Generator-Critic" or "Producer-Reviewer" model. While a single agent can perform self-reflection, using two specialized agents (or two separate LLM calls with distinct system prompts) often yields more robust and unbiased results.
在实践中,一种非常有效的做法,是将流程拆分为两个逻辑角色:生产者与批评者(也称
生成器–批评者、生产者–审阅者)。单一智能体也可以进行自我反思,但拆成两个专用智能体(或同一模型下两套不同的系统提示)通常更稳健,也更不容易出现「自己给自己放水」的问题。
- The Producer Agent: This agent's primary responsibility is to perform the initial execution of the task. It focuses entirely on generating the content, whether it's writing code, drafting a blog post, or creating a plan. It takes the initial prompt and produces the first version of the output.
- The Critic Agent: This agent's sole purpose is to evaluate the output generated by the Producer. It is given a different set of instructions, often a distinct persona (e.g., "You are a senior software engineer," "You are a meticulous fact-checker"). The Critic's instructions guide it to analyze the Producer's work against specific criteria, such as factual accuracy, code quality, stylistic requirements, or completeness. It is designed to find flaws, suggest improvements, and provide structured feedback.
生产者(Producer) 智能体:负责首版交付,专注生成内容——写代码、写文章、出方案等;接收初始提示,产出第一版结果。批评者(Critic) 智能体:其唯一职责是审阅生产者的稿件;系统提示与角色设定均不同于生产者(例如「资深工程师」「严谨的事实核查员」)。对照事实、代码质量、文风、完整度等维度识别问题,并输出结构化改进意见。
This separation of concerns is powerful because it prevents the "cognitive bias" of an agent reviewing its own work. The Critic agent approaches the output with a fresh perspective, dedicated entirely to finding errors and areas for improvement. The feedback from the Critic is then passed back to the Producer agent, which uses it as a guide to generate a new, refined version of the output. The provided LangChain and ADK code examples both implement this two-agent model: the LangChain example uses a specific reflector_prompt to create a critic persona, while the ADK example explicitly defines a producer and a reviewer agent.
将职责拆开之后,可以有效缓解「同时承担生成与评审」所带来的认知偏误:批评者会以发现问题并推动改进为明确目标介入。其反馈再回传给生产者,驱动第二版、第三版乃至更多轮修订……本章的 LangChain 示例通过
reflector_prompt固定批评者角色;ADK 示例则显式定义了生产者与审阅者两个LlmAgent。
Implementing reflection often requires structuring the agent's workflow to include these feedback loops. This can be achieved through iterative loops in code, or using frameworks that support state management and conditional transitions based on evaluation results. While a single step of evaluation and refinement can be implemented within either a LangChain/LangGraph, or ADK, or Crew.AI chain, true iterative reflection typically involves more complex orchestration.
要将反思机制真正落地,就需要在编排层为反馈闭环预留位置:既可以手写迭代循环,也可以借助支持状态管理与条件转移的框架来实现。单轮「评估一次、修改一次」在 LangChain/LangGraph、ADK 或 Crew.AI 中都不难实现;但若要进行真正的多轮迭代反思,通常仍需更完整的编排能力与状态持久化机制。
The Reflection pattern is crucial for building agents that can produce high-quality outputs, handle nuanced tasks, and exhibit a degree of self-awareness and adaptability. It moves agents beyond simply executing instructions towards a more sophisticated form of problem-solving and content generation.
如果目标是实现高质量交付、处理细致复杂的任务,或让系统具备一定程度的自我校正与适应能力,那么反思往往就是不可或缺的一环。它使智能体不再只是机械地执行指令,而是迈向更成熟的问题求解与内容生成方式。
The intersection of reflection with goal setting and monitoring (see Chapter 11) is worth noticing. A goal provides the ultimate benchmark for the agent's self-evaluation, while monitoring tracks its progress. In a number of practical cases, Reflection then might act as the corrective engine, using monitored feedback to analyze deviations and adjust its strategy. This synergy transforms the agent from a passive executor into a purposeful system that adaptively works to achieve its objectives.
反思与目标设定、运行监控(第 11 章)结合起来时,作用尤为明显:目标提供最终的评判标准,监控负责跟踪执行进展,而反思则依据监控反馈分析偏差并调整策略。三者协同作用,才能让系统从被动执行走向面向目标的自适应运行。
Furthermore, the effectiveness of the Reflection pattern is significantly enhanced when the LLM keeps a memory of the conversation (see Chapter 8). This conversational history provides crucial context for the evaluation phase, allowing the agent to assess its output not just in isolation, but against the backdrop of previous interactions, user feedback, and evolving goals. It enables the agent to learn from past critiques and avoid repeating errors. Without memory, each reflection is a self-contained event; with memory, reflection becomes a cumulative process where each cycle builds upon the last, leading to more intelligent and context-aware refinement.
若 LLM 侧还保留
对话记忆(第 8 章),反思往往事半功倍:历史轮次给评估提供上下文,让批评不只盯着当前片段,而能对照先前用户反馈、已声明目标与承诺;也能记住此前曾被指出的问题,减少重复犯错。没有记忆,每轮反思彼此孤立;有了记忆,反思便成为可累积的优化过程,越往后越贴合场景。
Practical Applications & Use Cases¶
实际应用与用例¶
The Reflection pattern is valuable in scenarios where output quality, accuracy, or adherence to complex constraints is critical:
当质量、准确率或复杂约束的满足度比时延更值钱时,
反思特别值得投入:
1. Creative Writing and Content Generation¶
1. 创意写作与内容生成¶
Refining generated text, stories, poems, or marketing copy.
对模型生成的故事、诗稿、营销文案等做多轮打磨。
- Use Case: An agent writing a blog post.
- Reflection: Generate a draft, critique it for flow, tone, and clarity, then rewrite based on the critique. Repeat until the post meets quality standards.
- Benefit: Produces more polished and effective content.
- 用例: 写博文的智能体。
- 反思: 先出草稿,再从行文、语气、清晰度等维度批评,然后重写;循环直到达标。
- 收益: 成稿更顺、更有说服力。
2. Code Generation and Debugging¶
2. 代码生成与调试¶
Writing code, identifying errors, and fixing them.
写代码、跑检查、据结果修补。
- Use Case: An agent writing a Python function.
- Reflection: Write initial code, run tests or static analysis, identify errors or inefficiencies, then modify the code based on the findings.
- Benefit: Generates more robust and functional code.
- 用例: 实现某个 Python 函数的智能体。
- 反思: 先写一版,再跑测试或静态分析,据报错与审查意见迭代修改。
- 收益: 代码更稳、更可维护。
3. Complex Problem Solving¶
3. 复杂问题解决¶
Evaluating intermediate steps or proposed solutions in multi-step reasoning tasks.
在长链条推理里,对中间结论或候选路径做评审与回溯。
- Use Case: An agent solving a logic puzzle.
- Reflection: Propose a step, evaluate if it leads closer to the solution or introduces contradictions, backtrack or choose a different step if needed.
- Benefit: Improves the agent's ability to navigate complex problem spaces.
- 用例: 解逻辑题的智能体。
- 反思: 每推进一步就自检是否逼近答案或制造矛盾,不行就回溯或换路。
- 收益: 在庞大的问题空间中更少走入无效分支。
4. Summarization and Information Synthesis¶
4. 摘要与信息综合¶
Refining summaries for accuracy, completeness, and conciseness.
在准确、完整、简练之间反复权衡,压缩或扩充摘要。
- Use Case: An agent summarizing a long document.
- Reflection: Generate an initial summary, compare it against key points in the original document, refine the summary to include missing information or improve accuracy.
- Benefit: Creates more accurate and comprehensive summaries.
- 用例: 长文摘要智能体。
- 反思: 先出摘要,再逐条对照原文要点,补缺、纠偏。
- 收益: 更少遗漏要点,也更少出现事实性偏差。
5. Planning and Strategy¶
5. 规划与策略¶
Evaluating a proposed plan and identifying potential flaws or improvements.
对拟定计划做可行性审查,标出风险与修订点。
- Use Case: An agent planning a series of actions to achieve a goal.
- Reflection: Generate a plan, simulate its execution or evaluate its feasibility against constraints, revise the plan based on the evaluation.
- Benefit: Develops more effective and realistic plans.
- 用例: 为多步行动做规划的智能体。
- 反思: 先给一版计划,再在脑中或借助工具做推演,对照硬约束评估,然后改版。
- 收益: 计划更接地气、更可执行。
6. Conversational Agents¶
6. 对话智能体¶
Reviewing previous turns in a conversation to maintain context, correct misunderstandings, or improve response quality.
回看前几轮对话,维持语境、消除误解、抬升回复质量。
- Use Case: A customer support chatbot.
- Reflection: After a user response, review the conversation history and the last generated message to ensure coherence and address the user's latest input accurately.
- Benefit: Leads to more natural and effective conversations.
- 用例: 客服机器人。
- 反思: 用户每说一句,就复盘全历史与上一轮机器人回复,检查是否接得上、是否答非所问。
- 收益: 语气更自然,问题解决路径更清晰。
Reflection adds a layer of meta-cognition to agentic systems, enabling them to learn from their own outputs and processes, leading to more intelligent, reliable, and high-quality results.
反思相当于为系统增加了一层「元认知」:它不只是产出答案,还会审视答案的形成过程,从而整体上变得更智能、更可靠。
Hands-On Code Example (LangChain)¶
动手代码示例(LangChain)¶
The implementation of a complete, iterative reflection process necessitates mechanisms for state management and cyclical execution. While these are handled natively in graph-based frameworks like LangGraph or through custom procedural code, the fundamental principle of a single reflection cycle can be demonstrated effectively using the compositional syntax of LCEL (LangChain Expression Language).
要实现
多轮迭代、直至满足停止条件的反思,离不开状态管理与循环驱动。LangGraph 这类图框架开箱即用,也可以手写控制流。若只想理解单轮反思的基本结构,用 LCEL 的组合语法便足够直观。
This example implements a reflection loop using the Langchain library and OpenAI's GPT-4o model to iteratively generate and refine a Python function that calculates the factorial of a number. The process starts with a task prompt, generates initial code, and then repeatedly reflects on the code based on critiques from a simulated senior software engineer role, refining the code in each iteration until the critique stage determines the code is perfect or a maximum number of iterations is reached. Finally, it prints the resulting refined code.
示例基于 LangChain 与 OpenAI GPT-4o,演示如何迭代写出计算阶乘的 Python 函数:先按任务说明生成初稿,再以「资深工程师」角色反复审查代码,直到返回
CODE_IS_PERFECT或达到最大迭代次数,最后打印终稿。
First, ensure you have the necessary libraries installed:
请先安装依赖:
You will also need to set up your environment with your API key for the language model you choose (e.g., OpenAI, Google Gemini, Anthropic).
还要在环境里为所选模型提供商(OpenAI、Google Gemini、Anthropic 等)配置 API 密钥。
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.messages import SystemMessage, HumanMessage
# --- Configuration ---
# Load environment variables from .env file (for OPENAI_API_KEY)
load_dotenv()
# Check if the API key is set
if not os.getenv("OPENAI_API_KEY"):
raise ValueError("OPENAI_API_KEY not found in .env file. Please add it.")
# Initialize the Chat LLM. We use gpt-4o for better reasoning.
# A lower temperature is used for more deterministic outputs.
llm = ChatOpenAI(model="gpt-4o", temperature=0.1)
def run_reflection_loop():
"""
Demonstrates a multi-step AI reflection loop to progressively improve a Python function.
"""
# --- The Core Task ---
task_prompt = """
Your task is to create a Python function named `calculate_factorial`.
This function should do the following:
1. Accept a single integer `n` as input.
2. Calculate its factorial (n!).
3. Include a clear docstring explaining what the function does.
4. Handle edge cases: The factorial of 0 is 1.
5. Handle invalid input: Raise a ValueError if the input is a negative number.
"""
# --- The Reflection Loop ---
max_iterations = 3
current_code = ""
# We will build a conversation history to provide context in each step.
message_history = [HumanMessage(content=task_prompt)]
for i in range(max_iterations):
print("\n" + "=" * 25 + f" REFLECTION LOOP: ITERATION {i + 1} " + "=" * 25)
# --- 1. GENERATE / REFINE STAGE ---
# In the first iteration, it generates. In subsequent iterations, it refines.
if i == 0:
print("\n>>> STAGE 1: GENERATING initial code...")
# The first message is just the task prompt.
response = llm.invoke(message_history)
current_code = response.content
else:
print("\n>>> STAGE 1: REFINING code based on previous critique...")
# The message history now contains the task,
# the last code, and the last critique.
# We instruct the model to apply the critiques.
message_history.append(HumanMessage(content="Please refine the code using the critiques provided."))
response = llm.invoke(message_history)
current_code = response.content
print("\n--- Generated Code (v" + str(i + 1) + ") ---\n" + current_code)
message_history.append(response) # Add the generated code to history
# --- 2. REFLECT STAGE ---
print("\n>>> STAGE 2: REFLECTING on the generated code...")
# Create a specific prompt for the reflector agent.
# This asks the model to act as a senior code reviewer.
reflector_prompt = [
SystemMessage(content="""
You are a senior software engineer and an expert
in Python.
Your role is to perform a meticulous code review.
Critically evaluate the provided Python code based
on the original task requirements.
Look for bugs, style issues, missing edge cases,
and areas for improvement.
If the code is perfect and meets all requirements,
respond with the single phrase 'CODE_IS_PERFECT'.
Otherwise, provide a bulleted list of your critiques.
"""),
HumanMessage(content=f"Original Task:\n{task_prompt}\n\nCode to Review:\n{current_code}"),
]
critique_response = llm.invoke(reflector_prompt)
critique = critique_response.content
# --- 3. STOPPING CONDITION ---
if "CODE_IS_PERFECT" in critique:
print("\n--- Critique ---\nNo further critiques found. The code is satisfactory.")
break
print("\n--- Critique ---\n" + critique)
# Add the critique to the history for the next refinement loop.
message_history.append(HumanMessage(content=f"Critique of the previous code:\n{critique}"))
print("\n" + "=" * 30 + " FINAL RESULT " + "=" * 30)
print("\nFinal refined code after the reflection process:\n")
print(current_code)
if __name__ == "__main__":
run_reflection_loop()
The code begins by setting up the environment, loading API keys, and initializing a powerful language model like GPT-4o with a low temperature for focused outputs. The core task is defined by a prompt asking for a Python function to calculate the factorial of a number, including specific requirements for docstrings, edge cases (factorial of 0), and error handling for negative input. The run_reflection_loop function orchestrates the iterative refinement process. Within the loop, in the first iteration, the language model generates initial code based on the task prompt. In subsequent iterations, it refines the code based on critiques from the previous step. A separate "reflector" role, also played by the language model but with a different system prompt, acts as a senior software engineer to critique the generated code against the original task requirements. This critique is provided as a bulleted list of issues or the phrase CODE_IS_PERFECT if no issues are found. The loop continues until the critique indicates the code is perfect or a maximum number of iterations is reached. The conversation history is maintained and passed to the language model in each step to provide context for both generation/refinement and reflection stages. Finally, the script prints the last generated code version after the loop concludes.
代码先加载环境变量与 API 密钥,以较低 temperature 初始化 GPT-4o,使输出更稳。任务提示要求实现带文档字符串的阶乘函数,覆盖
n=0边界,并对负数抛出ValueError。run_reflection_loop负责整段迭代:第一轮纯生成,之后把上一轮代码与批评一并塞进message_history再精炼。另有一套「反思者」系统提示,让模型扮演资深工程师;若未发现任何问题则返回CODE_IS_PERFECT,否则逐条列出批评意见。循环直到出现完美标记或用尽迭代次数。全程保留对话上下文,供生成与反思两侧复用;收尾打印最后一版代码。
Hands-On Code Example (ADK)¶
动手代码示例(ADK)¶
Let's now look at a conceptual code example implemented using the Google ADK. Specifically, the code showcases this by employing a Generator-Critic structure, where one component (the Generator) produces an initial result or plan, and another component (the Critic) provides critical feedback or a critique, guiding the Generator towards a more refined or accurate final output.
下面是一段概念级 ADK 示例:经典的生成器–批评者布局,前者产出初稿或初版方案,后者给出结构化批评,引导终稿向更准确、更稳健的方向改进。
from google.adk.agents import SequentialAgent, LlmAgent
# The first agent generates the initial draft.
generator = LlmAgent(
name="DraftWriter",
description="Generates initial draft content on a given subject.",
instruction="Write a short, informative paragraph about the user's subject.",
output_key="draft_text", # The output is saved to this state key.
)
# The second agent critiques the draft from the first agent.
reviewer = LlmAgent(
name="FactChecker",
description="Reviews a given text for factual accuracy and provides a structured critique.",
instruction="""
You are a meticulous fact-checker.
1. Read the text provided in the state key 'draft_text'.
2. Carefully verify the factual accuracy of all claims.
3. Your final output must be a dictionary containing two keys:
- "status": A string, either "ACCURATE" or "INACCURATE".
- "reasoning": A string providing a clear explanation for your status, citing specific issues if any are found.
""",
output_key="review_output", # The structured dictionary is saved here.
)
# The SequentialAgent ensures the generator runs before the reviewer.
review_pipeline = SequentialAgent(
name="WriteAndReview_Pipeline",
sub_agents=[generator, reviewer],
)
# Execution Flow:
# 1. generator runs -> saves its paragraph to state['draft_text'].
# 2. reviewer runs -> reads state['draft_text'] and saves its dictionary output to state['review_output'].
This code demonstrates the use of a sequential agent pipeline in Google ADK for generating and reviewing text. It defines two LlmAgent instances: generator and reviewer. The generator agent is designed to create an initial draft paragraph on a given subject. It is instructed to write a short and informative piece and saves its output to the state key draft_text. The reviewer agent acts as a fact-checker for the text produced by the generator. It is instructed to read the text from draft_text and verify its factual accuracy. The reviewer's output is a structured dictionary with two keys: status and reasoning. status indicates if the text is "ACCURATE" or "INACCURATE", while reasoning provides an explanation for the status. This dictionary is saved to the state key review_output. A SequentialAgent named review_pipeline is created to manage the execution order of the two agents. It ensures that the generator runs first, followed by the reviewer. The overall execution flow is that the generator produces text, which is then saved to the state. Subsequently, the reviewer reads this text from the state, performs its fact-checking, and saves its findings (the status and reasoning) back to the state. This pipeline allows for a structured process of content creation and review using separate agents.
示例展示如何在 Google ADK 里用顺序流水线做「写—审」:
generator、reviewer两个LlmAgent。生成器按主题写一段短而信息密度高的正文,落到状态键draft_text;审阅器读同键,做事实核查,并产出包含status(ACCURATE/INACCURATE)与reasoning的字典,写入review_output。SequentialAgent名为review_pipeline,硬性保证先写后审:状态里先出现草稿,再出现审查结论。两个智能体各司其职,把创作与质检拆开。
Note: An alternative implementation utilizing ADK's LoopAgent is also available for those interested.
注: 若感兴趣,还可采用 ADK 的
LoopAgent实现替代方案。
Before concluding, it's important to consider that while the Reflection pattern significantly enhances output quality, it comes with important trade-offs. The iterative process, though powerful, can lead to higher costs and latency, since every refinement loop may require a new LLM call, making it suboptimal for time-sensitive applications. Furthermore, the pattern is memory-intensive; with each iteration, the conversational history expands, including the initial output, critique, and subsequent refinements.
收尾前需指出:反思能抬升质量,但伴随明确成本。每多一轮通常就多一次模型调用,时延与费用同步上升,低延迟场景须谨慎评估。上下文也会逐轮膨胀——旧稿、批评与修订稿堆叠,更容易触达上下文上限。
At Glance¶
速览¶
What: An agent's initial output is often suboptimal, suffering from inaccuracies, incompleteness, or a failure to meet complex requirements. Basic agentic workflows lack a built-in process for the agent to recognize and fix its own errors. This is solved by having the agent evaluate its own work or, more robustly, by introducing a separate logical agent to act as a critic, preventing the initial response from being the final one regardless of quality.
是什么: 智能体生成的第一版输出往往并不理想,常见问题包括事实不准、内容不完整,或未能满足复杂要求。而基础的智能体工作流通常缺少一套让系统识别并修正自身错误的内建机制。解决这一问题的方式,是让智能体对自己的产出进行评估;更稳妥的做法,则是引入一个独立的「批评者」角色,从而避免无论质量如何,初始回答都直接成为最终答案。
Why: The Reflection pattern offers a solution by introducing a mechanism for self-correction and refinement. It establishes a feedback loop where a "producer" agent generates an output, and then a "critic" agent (or the producer itself) evaluates it against predefined criteria. This critique is then used to generate an improved version. This iterative process of generation, evaluation, and refinement progressively enhances the quality of the final result, leading to more accurate, coherent, and reliable outcomes.
为什么: 反思模式通过引入自我纠正与持续精炼机制来解决这一问题。它建立起一个反馈闭环:由「生产者」智能体先生成输出,再由「批评者」智能体(或生产者自身)依据预设标准进行评估,而这些评估结果又会反过来指导下一版的生成。随着生成、评估与精炼的迭代推进,最终结果通常会在准确性、连贯性与可靠性方面持续提升。
Rule of thumb: Use the Reflection pattern when the quality, accuracy, and detail of the final output are more important than speed and cost. It is particularly effective for tasks like generating polished long-form content, writing and debugging code, and creating detailed plans. Employ a separate critic agent when tasks require high objectivity or specialized evaluation that a generalist producer agent might miss.
经验法则: 当最终输出的质量、准确性与细节完整度比速度和成本更重要时,就应考虑使用反思模式。它尤其适用于长篇内容打磨、代码编写与调试,以及复杂计划制定等任务。若任务对客观性要求较高,或需要更专业的评估视角,最好引入独立的「批评者」智能体,而不是只依赖生产者自行审查。
Visual summary:
图示摘要:
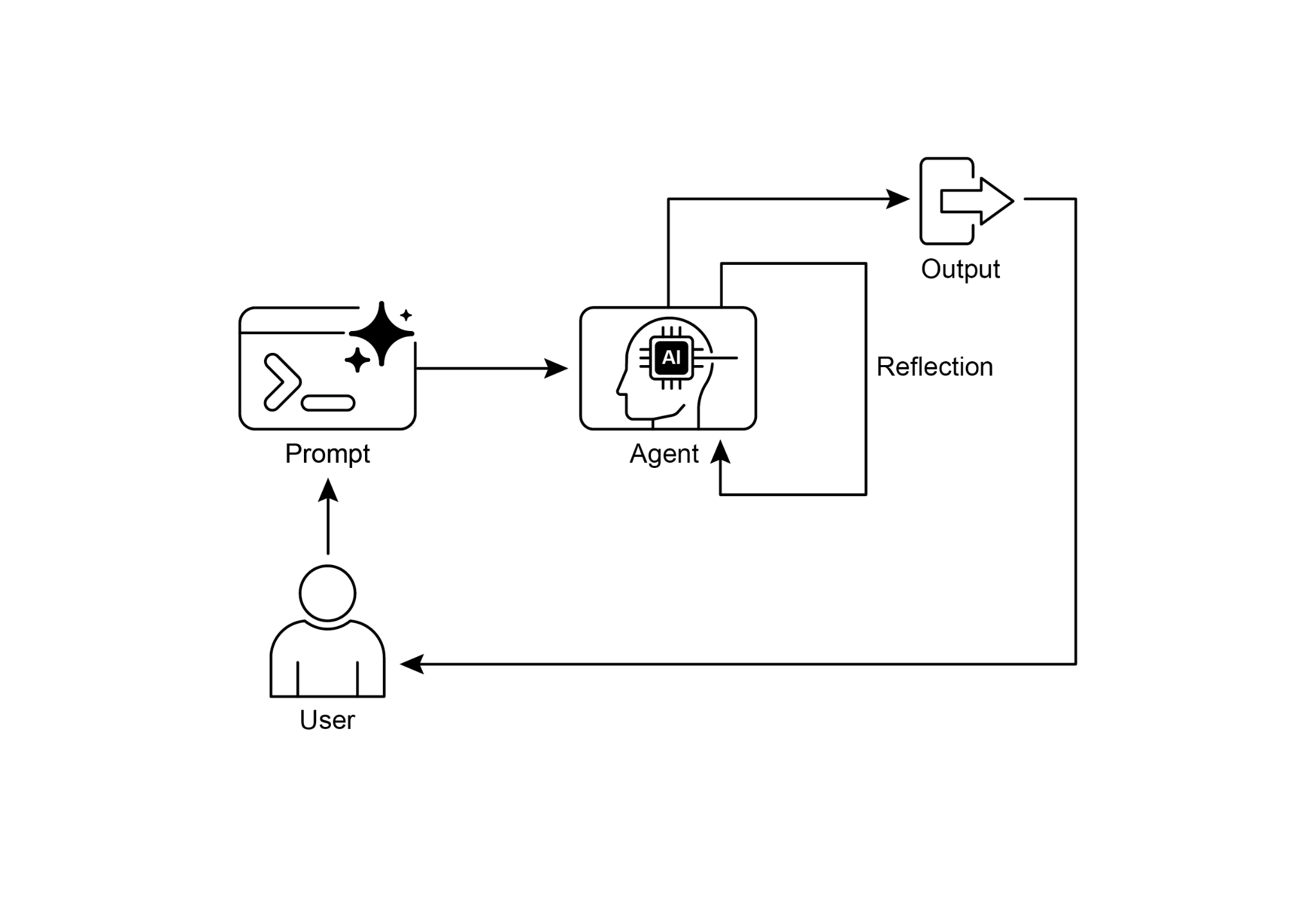
Fig. 1: Reflection design pattern, self-reflection
图 1:反思设计模式,自我反思
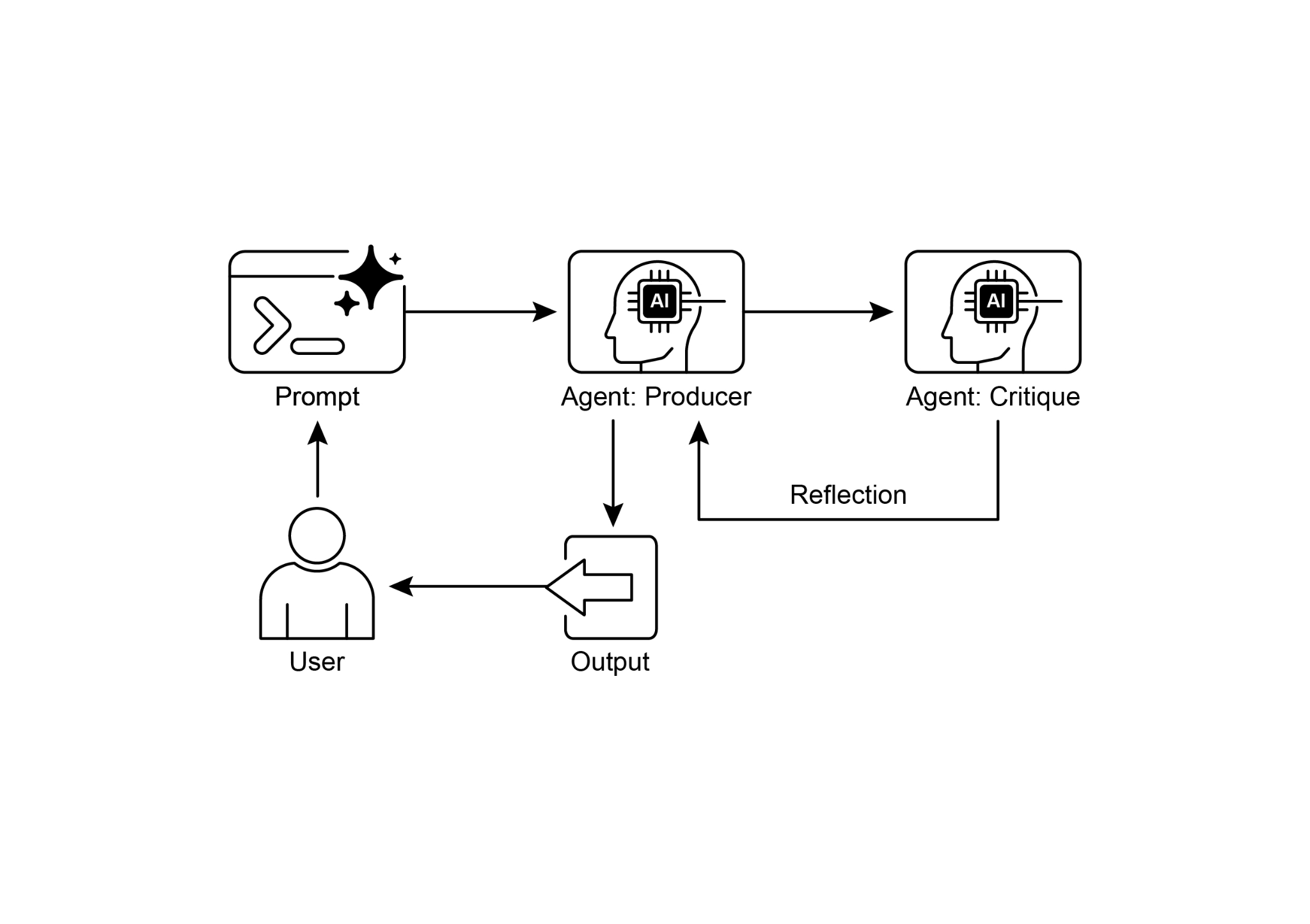
Fig.2: Reflection design pattern, producer and critique agent
图 2:反思设计模式,生产者与批评者智能体
Key Takeaways¶
要点¶
可归纳为:
- The primary advantage of the Reflection pattern is its ability to iteratively self-correct and refine outputs, leading to significantly higher quality, accuracy, and adherence to complex instructions.
- It involves a feedback loop of execution, evaluation/critique, and refinement. Reflection is essential for tasks requiring high-quality, accurate, or nuanced outputs.
- A powerful implementation is the Producer-Critic model, where a separate agent (or prompted role) evaluates the initial output. This separation of concerns enhances objectivity and allows for more specialized, structured feedback.
- However, these benefits come at the cost of increased latency and computational expense, along with a higher risk of exceeding the model's context window or being throttled by API services.
- While full iterative reflection often requires stateful workflows (like LangGraph), a single reflection step can be implemented in LangChain using LCEL to pass output for critique and subsequent refinement.
- Google ADK can facilitate reflection through sequential workflows where one agent's output is critiqued by another agent, allowing for subsequent refinement steps.
- This pattern enables agents to perform self-correction and enhance their performance over time.
- 反思的主要优势在于支持多轮自我纠正,在质量、准确率与对复杂指令的遵循度上同步提升。
- 典型闭环:执行 → 批评 → 精炼;交付标准苛刻时往往值得投入。
- 生产者–批评者拆分最常见:两个智能体或两套提示,换个视角审视问题,反馈更结构化。
- 代价是更慢、更贵,也更吃上下文,容易触及 token 上限或受到 API 配额限制。
- 多轮直到收敛通常要 LangGraph 一类有状态编排;若只做「评一次、改一次」,LCEL 也能串起来。
- ADK 里用
SequentialAgent把写与审串成管道,同样能接到后续精炼步骤。- 长远看,
反思让系统具备持续自我校准的能力。
Conclusion¶
结语¶
The reflection pattern provides a crucial mechanism for self-correction within an agent's workflow, enabling iterative improvement beyond a single-pass execution. This is achieved by creating a loop where the system generates an output, evaluates it against specific criteria, and then uses that evaluation to produce a refined result. This evaluation can be performed by the agent itself (self-reflection) or, often more effectively, by a distinct critic agent, which represents a key architectural choice within the pattern.
反思为工作流补上「自我纠错」这一环:产出 → 对照标准评估 → 据评估改版,从而突破单次生成的天花板。评估可以自评,也可以交给独立批评者,后者在实践中往往更稳,也是架构上需要预先权衡的关键取舍。
While a fully autonomous, multi-step reflection process requires a robust architecture for state management, its core principle is effectively demonstrated in a single generate-critique-refine cycle. As a control structure, reflection can be integrated with other foundational patterns to construct more robust and functionally complex agentic systems.
端到端多轮反思离不开可靠的状态与调度,但弄懂「生成–批评–精炼」这一最小闭环,就足以把握其精髓。把它与链式、路由、并行等基础模式组合使用,可构建更能承载复杂需求、功能更丰富的智能体系统。
References¶
Here are some resources for further reading on the Reflection pattern and related concepts:
- Training Language Models to Self-Correct via Reinforcement Learning, https://arxiv.org/abs/2409.12917
- LangChain Expression Language (LCEL) Documentation: https://python.langchain.com/docs/introduction/
- LangGraph Documentation:https://www.langchain.com/langgraph
- Google Agent Developer Kit (ADK) Documentation (Multi-Agent Systems): https://google.github.io/adk-docs/agents/multi-agents/