Chapter 19: Evaluation and Monitoring¶
第 19 章:评估与监控
This chapter examines methodologies that allow intelligent agents to systematically assess their performance, monitor progress toward goals, and detect operational anomalies. While Chapter 11 outlines goal setting and monitoring, and Chapter 17 addresses Reasoning mechanisms, this chapter focuses on the continuous, often external, measurement of an agent's effectiveness, efficiency, and compliance with requirements. This includes defining metrics, establishing feedback loops, and implementing reporting systems to ensure agent performance aligns with expectations in operational environments (see Fig.1)
本章讨论如何让智能体系统性评估自身表现、监控目标进展,并及时发现运行异常。第 11 章讲目标设定与监控,第 17 章讲推理机制;而本章更关注对智能体有效性、效率和合规性的持续度量,且主要依赖外部观测。具体包括指标定义、反馈闭环和报告机制,用来确保智能体在真实运行环境中的表现与预期保持一致(见图 1)。
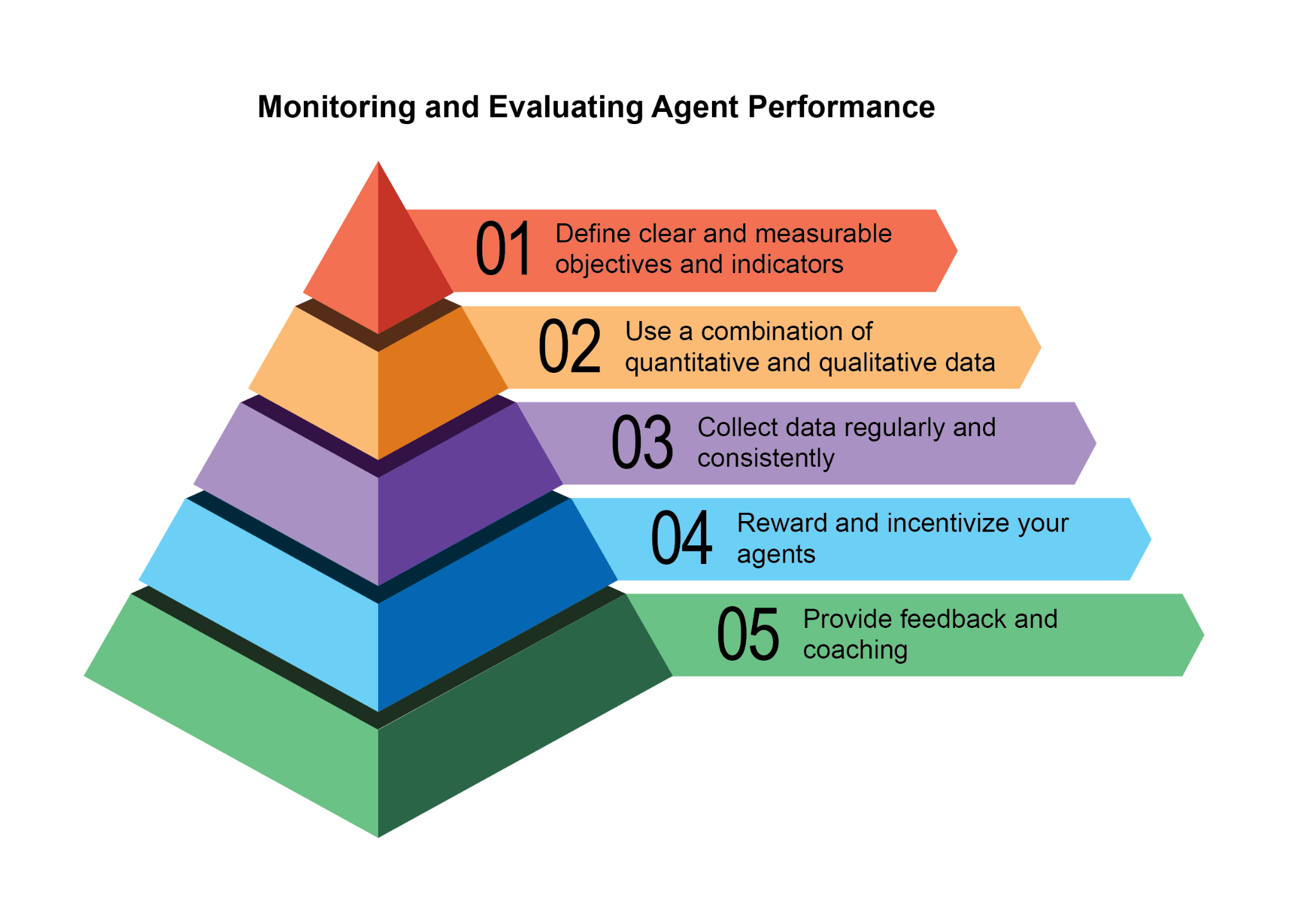
Fig:1. Best practices for evaluation and monitoring
图 1:评估与监控的最佳实践
Practical Applications & Use Cases¶
实际应用与用例¶
Most Common Applications and Use Cases:
最常见的应用场景包括:
- Performance Tracking in Live Systems: Continuously monitoring the accuracy, latency, and resource consumption of an agent deployed in a production environment (e.g., a customer service chatbot's resolution rate, response time).
- A/B Testing for Agent Improvements: Systematically comparing the performance of different agent versions or strategies in parallel to identify optimal approaches (e.g., trying two different planning algorithms for a logistics agent).
- Compliance and Safety Audits: Generate automated audit reports that track an agent's compliance with ethical guidelines, regulatory requirements, and safety protocols over time. These reports can be verified by a human-in-the-loop or another agent, and can generate KPIs or trigger alerts upon identifying issues.
- Enterprise systems: To govern Agentic AI in corporate systems, a new control instrument, the AI "Contract," is needed. This dynamic agreement codifies the objectives, rules, and controls for AI-delegated tasks.
- Drift Detection: Monitoring the relevance or accuracy of an agent's outputs over time, detecting when its performance degrades due to changes in input data distribution (concept drift) or environmental shifts.
- Anomaly Detection in Agent Behavior: Identifying unusual or unexpected actions taken by an agent that might indicate an error, a malicious attack, or an emergent un-desired behavior.
- Learning Progress Assessment: For agents designed to learn, tracking their learning curve, improvement in specific skills, or generalization capabilities over different tasks or data sets.
- 线上系统性能跟踪: 持续观测生产环境中智能体的准确率、时延与资源占用(例如客服场景的解决率、响应时间)。
- 智能体改进的 A/B 测试: 并行对比不同版本或策略的效果,筛选更优方案(如对物流智能体并行试用两种规划算法)。
- 合规与安全审计: 自动生成审计报告,长期追踪智能体对伦理准则、法规与安全规程的遵守情况;报告可由人类或其他智能体复核,并在异常时产出 KPI 或触发告警。
- 企业系统: 治理企业级 Agentic AI 往往需要新的控制机制,即 AI「合约(Contract)」;通过动态协议把委派任务的目标、规则与控制措施写清楚,并转化为可执行约束。
- 漂移检测: 跟踪智能体输出随时间的相关性或准确度,识别输入分布变化(概念漂移)或环境变迁带来的性能衰减。
- 智能体行为异常检测: 识别反常或出乎意料的行动,可能预示错误、恶意攻击或涌现的不良行为。
- 学习进度评估: 针对具备学习能力的智能体,记录学习曲线、专项技能进步,以及在跨任务、跨数据集上的泛化表现。
Hands-On Code Example¶
动手代码示例¶
Developing a comprehensive evaluation framework for AI agents is a challenging endeavor, comparable to an academic discipline or a substantial publication in its complexity. This difficulty stems from the multitude of factors to consider, such as model performance, user interaction, ethical implications, and broader societal impact. Nevertheless, for practical implementation, the focus can be narrowed to critical use cases essential for the efficient and effective functioning of AI agents.
为智能体搭建一套完备的评估框架并不容易,其复杂度不亚于一门独立学科,甚至足以写成一部重量级专著。难点在于,它需要同时权衡模型表现、用户交互、伦理影响和社会影响等多个维度。真正落地时,通常会先把范围收窄,只聚焦那些直接决定智能体能否高效、可靠运行的核心用例。
Agent Response Assessment: This core process is essential for evaluating the quality and accuracy of an agent's outputs. It involves determining if the agent delivers pertinent, correct, logical, unbiased, and accurate information in response to given inputs. Assessment metrics may include factual correctness, fluency, grammatical precision, and adherence to the user's intended purpose.
智能体回复评估: 这是衡量输出质量与准确性的核心环节。重点要看:给定输入后,回复是否相关、正确、逻辑自洽、无明显偏见,且信息可靠。常见指标包括事实正确性、语言流畅度、语法规范,以及与用户意图的契合度。
def evaluate_response_accuracy(agent_output: str, expected_output: str) -> float:
"""Calculates a simple accuracy score for agent responses."""
# This is a very basic exact match; real-world would use more sophisticated metrics
return 1.0 if agent_output.strip().lower() == expected_output.strip().lower() else 0.0
# Example usage
agent_response = "The capital of France is Paris."
ground_truth = "Paris is the capital of France."
score = evaluate_response_accuracy(agent_response, ground_truth)
print(f"Response accuracy: {score}")
The Python function evaluate_response_accuracy calculates a basic accuracy score for an AI agent's response by performing an exact, case-insensitive comparison between the agent's output and the expected output, after removing leading or trailing whitespace. It returns a score of 1.0 for an exact match and 0.0 otherwise, representing a binary correct or incorrect evaluation. This method, while straightforward for simple checks, does not account for variations like paraphrasing or semantic equivalence.
Python 函数
evaluate_response_accuracy会先去除首尾空白,再对智能体输出与期望输出做不区分大小写的逐字精确匹配:完全一致返回 1.0,否则返回 0.0,也就是一个二元对错判定。这个方法实现简单,但处理不了同义改写、语序变化或语义等价等情况。
The problem lies in its method of comparison. The function performs a strict, character-for-character comparison of the two strings. In the example provided:
agent_response: "The capital of France is Paris."ground_truth: "Paris is the capital of France."
Even after removing whitespace and converting to lowercase, these two strings are not identical. As a result, the function will incorrectly return an accuracy score of 0.0, even though both sentences convey the same meaning.
问题就出在比较策略本身:它采用的是严格逐字比对。示例中: *
agent_response:「The capital of France is Paris.」 *ground_truth:「Paris is the capital of France.」 即便去掉空白并统一小写,两串仍不一致,函数会误报0.0,而两句语义其实相同。
A straightforward comparison falls short in assessing semantic similarity, only succeeding if an agent's response exactly matches the expected output. A more effective evaluation necessitates advanced Natural Language Processing (NLP) techniques to discern the meaning between sentences. For thorough AI agent evaluation in real-world scenarios, more sophisticated metrics are often indispensable. These metrics can encompass String Similarity Measures like Levenshtein distance and Jaccard similarity, Keyword Analysis for the presence or absence of specific keywords, Semantic Similarity using cosine similarity with embedding models, LLM-as-a-Judge Evaluations (discussed later for assessing nuanced correctness and helpfulness), and RAG-specific Metrics such as faithfulness and relevance.
纯字符串比对很难刻画语义相似,只有与期望输出逐字一致才算「成功」。更有效的评估,通常需要借助自然语言处理(NLP)来判断句义。真实场景里的智能体评估也往往不是单看一个指标,而是组合多种方法,例如 Levenshtein、Jaccard 等字符串相似度,关键词覆盖分析,基于向量嵌入的余弦语义相似度,LLM-as-a-Judge(后文会详细讲,用于细判正确性与有用性),以及 RAG 场景下的忠实度、相关性等。
Latency Monitoring: Latency Monitoring for Agent Actions is crucial in applications where the speed of an AI agent's response or action is a critical factor. This process measures the duration required for an agent to process requests and generate outputs. Elevated latency can adversely affect user experience and the agent's overall effectiveness, particularly in real-time or interactive environments. In practical applications, simply printing latency data to the console is insufficient. Logging this information to a persistent storage system is recommended. Options include structured log files (e.g., JSON), time-series databases (e.g., InfluxDB, Prometheus), data warehouses (e.g., Snowflake, BigQuery, PostgreSQL), or observability platforms (e.g., Datadog, Splunk, Grafana Cloud).
延迟监控: 当响应或行动速度直接决定体验时,端到端延迟就是关键指标,也就是从请求进入到结果产出所花的总时间。延迟一高,用户体验和系统效果都会受影响,尤其是在实时或高交互场景中。生产环境里不应只把数据打印到控制台,更适合写入持久化系统,例如结构化日志(如 JSON)、时序数据库(如 InfluxDB、Prometheus)、数据仓库(如 Snowflake、BigQuery、PostgreSQL),或可观测平台(如 Datadog、Splunk、Grafana Cloud)。
Tracking Token Usage for LLM Interactions: For LLM-powered agents, tracking token usage is crucial for managing costs and optimizing resource allocation. Billing for LLM interactions often depends on the number of tokens processed (input and output). Therefore, efficient token usage directly reduces operational expenses. Additionally, monitoring token counts helps identify potential areas for improvement in prompt engineering or response generation processes.
跟踪 LLM 交互的 token 用量: 对 LLM 驱动的智能体来说,统计 token 用量是成本管控和容量规划的基础,因为大多数服务都会按输入、输出 token 计费。提高 token 利用效率,能直接压缩开支;持续监控也有助于发现提示设计或生成策略中的优化空间。
# This is conceptual as actual token counting depends on the LLM API
class LLMInteractionMonitor:
def __init__(self):
self.total_input_tokens = 0
self.total_output_tokens = 0
def record_interaction(self, prompt: str, response: str):
# In a real scenario, use LLM API's token counter or a tokenizer
input_tokens = len(prompt.split()) # Placeholder
output_tokens = len(response.split()) # Placeholder
self.total_input_tokens += input_tokens
self.total_output_tokens += output_tokens
print(f"Recorded interaction: Input tokens={input_tokens}, Output tokens={output_tokens}")
def get_total_tokens(self):
return self.total_input_tokens, self.total_output_tokens
# Example usage
monitor = LLMInteractionMonitor()
monitor.record_interaction("What is the capital of France?", "The capital of France is Paris.")
monitor.record_interaction("Tell me a joke.", "Why don't scientists trust atoms? Because they make up everything!")
input_t, output_t = monitor.get_total_tokens()
print(f"Total input tokens: {input_t}, Total output tokens: {output_t}")
This section introduces a conceptual Python class, LLMInteractionMonitor, developed to track token usage in large language model interactions. The class incorporates counters for both input and output tokens. Its record_interaction method simulates token counting by splitting the prompt and response strings. In a practical implementation, specific LLM API tokenizers would be employed for precise token counts. As interactions occur, the monitor accumulates the total input and output token counts. The get_total_tokens method provides access to these cumulative totals, essential for cost management and optimization of LLM usage.
本节给出一个概念性的 Python 类
LLMInteractionMonitor,用来累计大语言模型交互中的 token 用量,分别维护输入与输出计数。record_interaction这里用分词数近似 token 数;在线上环境中,应替换为对应 API 的官方分词器。每次交互累加后,可通过get_total_tokens读取总量,用于支撑成本核算与用量优化。
Custom Metric for "Helpfulness" using LLM-as-a-Judge: Evaluating subjective qualities like an AI agent's "helpfulness" presents challenges beyond standard objective metrics. A potential framework involves using an LLM as an evaluator. This LLM-as-a-Judge approach assesses another AI agent's output based on predefined criteria for "helpfulness." Leveraging the advanced linguistic capabilities of LLMs, this method offers nuanced, human-like evaluations of subjective qualities, surpassing simple keyword matching or rule-based assessments. Though in development, this technique shows promise for automating and scaling qualitative evaluations.
以 LLM-as-a-Judge 度量「有用性」: 「有用性」这类主观维度,很难只靠传统客观指标覆盖。一种可行做法,是让 LLM 充当评委,按预先约定的有用性 rubric 去评判另一智能体的输出。借助大模型的语言理解能力,这种方法能给出更接近人类的细粒度判断,通常也比关键词匹配或硬编码规则更灵活。它仍在快速演进,但在自动化、规模化开展质性评估方面已经展现出很大潜力。
import os
import json
import logging
from typing import Optional
import google.generativeai as genai
# --- Configuration ---
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# Set your API key as an environment variable to run this script
# For example, in your terminal: export GOOGLE_API_KEY='your_key_here'
try:
genai.configure(api_key=os.environ["GOOGLE_API_KEY"])
except KeyError:
logging.error("Error: GOOGLE_API_KEY environment variable not set.")
exit(1)
# --- LLM-as-a-Judge Rubric for Legal Survey Quality ---
LEGAL_SURVEY_RUBRIC = """
You are an expert legal survey methodologist and a critical legal reviewer. Your task is to evaluate the quality of a given legal survey question. Provide a score from 1 to 5 for overall quality, along with a detailed rationale and specific feedback.
Focus on the following criteria:
1. **Clarity & Precision (Score 1-5):**
* 1: Extremely vague, highly ambiguous, or confusing.
* 3: Moderately clear, but could be more precise.
* 5: Perfectly clear, unambiguous, and precise in its legal terminology (if applicable) and intent.
2. **Neutrality & Bias (Score 1-5):**
* 1: Highly leading or biased, clearly influencing the respondent towards a specific answer.
* 3: Slightly suggestive or could be interpreted as leading.
* 5: Completely neutral, objective, and free from any leading language or loaded terms.
3. **Relevance & Focus (Score 1-5):**
* 1: Irrelevant to the stated survey topic or out of scope.
* 3: Loosely related but could be more focused.
* 5: Directly relevant to the survey's objectives and well-focused on a single concept.
4. **Completeness (Score 1-5):**
* 1: Omits critical information needed to answer accurately or provides insufficient context.
* 3: Mostly complete, but minor details are missing.
* 5: Provides all necessary context and information for the respondent to answer thoroughly.
5. **Appropriateness for Audience (Score 1-5):**
* 1: Uses jargon inaccessible to the target audience or is overly simplistic for experts.
* 3: Generally appropriate, but some terms might be challenging or oversimplified.
* 5: Perfectly tailored to the assumed legal knowledge and background of the target survey audience.
**Output Format:**
Your response MUST be a JSON object with the following keys:
* `overall_score`: An integer from 1 to 5 (average of criterion scores, or your holistic judgment).
* `rationale`: A concise summary of why this score was given, highlighting major strengths and weaknesses.
* `detailed_feedback`: A bullet-point list detailing feedback for each criterion (Clarity, Neutrality, Relevance, Completeness, Audience Appropriateness). Suggest specific improvements.
* `concerns`: A list of any specific legal, ethical, or methodological concerns.
* `recommended_action`: A brief recommendation (e.g., "Revise for neutrality", "Approve as is", "Clarify scope").
"""
class LLMJudgeForLegalSurvey:
"""A class to evaluate legal survey questions using a generative AI model."""
def __init__(self, model_name: str = 'gemini-1.5-flash-latest', temperature: float = 0.2):
"""
Initializes the LLM Judge.
Args:
model_name (str): The name of the Gemini model to use.
'gemini-1.5-flash-latest' is recommended for speed and cost.
'gemini-1.5-pro-latest' offers the highest quality.
temperature (float): The generation temperature. Lower is better for deterministic evaluation.
"""
self.model = genai.GenerativeModel(model_name)
self.temperature = temperature
def _generate_prompt(self, survey_question: str) -> str:
"""Constructs the full prompt for the LLM judge."""
return f"{LEGAL_SURVEY_RUBRIC}\n\n---\n**LEGAL SURVEY QUESTION TO EVALUATE:**\n{survey_question}\n---"
def judge_survey_question(self, survey_question: str) -> Optional[dict]:
"""
Judges the quality of a single legal survey question using the LLM.
Args:
survey_question (str): The legal survey question to be evaluated.
Returns:
Optional[dict]: A dictionary containing the LLM's judgment, or None if an error occurs.
"""
full_prompt = self._generate_prompt(survey_question)
try:
logging.info(f"Sending request to '{self.model.model_name}' for judgment...")
response = self.model.generate_content(
full_prompt,
generation_config=genai.types.GenerationConfig(
temperature=self.temperature,
response_mime_type="application/json"
)
)
# Check for content moderation or other reasons for an empty response.
if not response.parts:
safety_ratings = response.prompt_feedback.safety_ratings
logging.error(f"LLM response was empty or blocked. Safety Ratings: {safety_ratings}")
return None
return json.loads(response.text)
except json.JSONDecodeError:
logging.error(f"Failed to decode LLM response as JSON. Raw response: {response.text}")
return None
except Exception as e:
logging.error(f"An unexpected error occurred during LLM judgment: {e}")
return None
# --- Example Usage ---
if __name__ == "__main__":
judge = LLMJudgeForLegalSurvey()
# --- Good Example ---
good_legal_survey_question = """
To what extent do you agree or disagree that current intellectual property laws in Switzerland adequately protect emerging AI-generated content, assuming the content meets the originality criteria established by the Federal Supreme Court?
(Select one: Strongly Disagree, Disagree, Neutral, Agree, Strongly Agree)
"""
print("\n--- Evaluating Good Legal Survey Question ---")
judgment_good = judge.judge_survey_question(good_legal_survey_question)
if judgment_good:
print(json.dumps(judgment_good, indent=2))
# --- Biased/Poor Example ---
biased_legal_survey_question = """
Don't you agree that overly restrictive data privacy laws like the FADP are hindering essential technological innovation and economic growth in Switzerland?
(Select one: Yes, No)
"""
print("\n--- Evaluating Biased Legal Survey Question ---")
judgment_biased = judge.judge_survey_question(biased_legal_survey_question)
if judgment_biased:
print(json.dumps(judgment_biased, indent=2))
# --- Ambiguous/Vague Example ---
vague_legal_survey_question = """
What are your thoughts on legal tech?
"""
print("\n--- Evaluating Vague Legal Survey Question ---")
judgment_vague = judge.judge_survey_question(vague_legal_survey_question)
if judgment_vague:
print(json.dumps(judgment_vague, indent=2))
The Python code defines a class LLMJudgeForLegalSurvey designed to evaluate the quality of legal survey questions using a generative AI model. It utilizes the google.generativeai library to interact with Gemini models.
该 Python 示例实现
LLMJudgeForLegalSurvey类,借助生成式模型评判法律调研问卷的质量,并通过google.generativeai与 Gemini 交互。
The core functionality involves sending a survey question to the model along with a detailed rubric for evaluation. The rubric specifies five criteria for judging survey questions: Clarity & Precision, Neutrality & Bias, Relevance & Focus, Completeness, and Appropriateness for Audience. For each criterion, a score from 1 to 5 is assigned, and a detailed rationale and feedback are required in the output. The code constructs a prompt that includes the rubric and the survey question to be evaluated.
核心做法,是把待评问题与一份详细评分 rubric 一并交给模型。Rubric 覆盖五个维度:清晰度与精确性、中立性与偏见、相关性与聚焦、完整性,以及受众适配度;每项按 1-5 分打分,并要求给出理由和改进建议。最终提示由 rubric 与目标问题拼接而成。
The judge_survey_question method sends this prompt to the configured Gemini model, requesting a JSON response formatted according to the defined structure. The expected output JSON includes an overall score, a summary rationale, detailed feedback for each criterion, a list of concerns, and a recommended action. The class handles potential errors during the AI model interaction, such as JSON decoding issues or empty responses. The script demonstrates its operation by evaluating examples of legal survey questions, illustrating how the AI assesses quality based on the predefined criteria.
judge_survey_question会把这份提示发送给指定的 Gemini 模型,并要求它按 JSON 结构返回:总分、概要理由、分项反馈、风险关切和建议动作。类内部也对 JSON 解析失败、空响应等异常做了兜底处理。脚本末尾则通过正反两类问卷示例,演示完整的评判链路。
Before we conclude, let's examine various evaluation methods, considering their strengths and weaknesses.
结束前,先横向对比几类评估手段及其取舍。
| Evaluation Method | Strengths | Weaknesses |
|---|---|---|
| Human Evaluation | Captures subtle behavior | Difficult to scale, expensive, and time-consuming, as it considers subjective human factors. |
| LLM-as-a-Judge | Consistent, efficient, and scalable. | Intermediate steps may be overlooked. Limited by LLM capabilities. |
| Automated Metrics | Scalable, efficient, and objective | Potential limitation in capturing complete capabilities. |
上表几类方法各有取舍:人工评估善于捕捉细微行为,但成本高、难规模化,而且主观性较强;LLM 评判相对一致、高效、易扩展,却可能忽略中间步骤,也受模型本身能力上限制约;自动化指标最容易扩展、也更客观,但往往难以完整反映智能体的综合能力边界。
Agents trajectories¶
智能体轨迹(Agent Trajectories)¶
Evaluating agents' trajectories is essential, as traditional software tests are insufficient. Standard code yields predictable pass/fail results, whereas agents operate probabilistically, necessitating qualitative assessment of both the final output and the agent's trajectory—the sequence of steps taken to reach a solution. Evaluating multi-agent systems is challenging because they are constantly in flux. This requires developing sophisticated metrics that go beyond individual performance to measure the effectiveness of communication and teamwork. Moreover, the environments themselves are not static, demanding that evaluation methods, including test cases, adapt over time.
评估智能体轨迹非常关键,因为传统软件测试往往不够用。确定性代码尚可用通过/失败来刻画,而智能体行为带有随机性,所以既要看最终输出,也要看它是如何一步步走到这个结果的,也就是行动轨迹。多智能体系统及其所处环境都在持续变化,评估因此更难;这时就需要超越单智能体绩效、能够刻画沟通与协作质量的复合指标。测试设计与用例本身,也必须随着环境演化持续更新。
This involves examining the quality of decisions, the reasoning process, and the overall outcome. Implementing automated evaluations is valuable, particularly for development beyond the prototype stage. Analyzing trajectory and tool use includes evaluating the steps an agent employs to achieve a goal, such as tool selection, strategies, and task efficiency. For example, an agent addressing a customer's product query might ideally follow a trajectory involving intent determination, database search tool use, result review, and report generation. The agent's actual actions are compared to this expected, or ground truth, trajectory to identify errors and inefficiencies. Comparison methods include exact match (requiring a perfect match to the ideal sequence), in-order match (correct actions in order, allowing extra steps), any-order match (correct actions in any order, allowing extra steps), precision (measuring the relevance of predicted actions), recall (measuring how many essential actions are captured), and single-tool use (checking for a specific action). Metric selection depends on specific agent requirements, with high-stakes scenarios potentially demanding an exact match, while more flexible situations might use an in-order or any-order match.
这意味着要同时审视决策质量、推理链路和最终结果。越过原型阶段之后,自动化轨迹评估的价值会尤其突出。对工具使用的分析,通常包括工具选型、策略选择和任务效率等维度。比如处理客户产品咨询时,理想轨迹可能是:先识别意图,再调用数据库检索,接着复核结果,最后生成答复。把实际轨迹与期望轨迹(金标准)对照,就能定位错误与资源浪费。常见比对方式包括精确匹配、保序匹配(允许插入冗余步骤)、任意序匹配(同样允许冗余)、精确率、召回率,以及对单一关键工具的专项检查等。具体选哪种,要根据业务风险在严格与宽松之间权衡。
Evaluation of AI agents involves two primary approaches: using test files and using evalset files. Test files, in JSON format, represent single, simple agent-model interactions or sessions and are ideal for unit testing during active development, focusing on rapid execution and simple session complexity. Each test file contains a single session with multiple turns, where a turn is a user-agent interaction including the user’s query, expected tool use trajectory, intermediate agent responses, and final response. For example, a test file might detail a user request to “Turn off device_2 in the Bedroom,” specifying the agent’s use of a set_device_info tool with parameters like location: Bedroom, device_id: device_2, and status: OFF, and an expected final response of “I have set the device_2 status to off.” Test files can be organized into folders and may include a test_config.json file to define evaluation criteria. Evalset files utilize a dataset called an “evalset” to evaluate interactions, containing multiple potentially lengthy sessions suited for simulating complex, multi-turn conversations and integration tests. An evalset file comprises multiple “evals,” each representing a distinct session with one or more “turns” that include user queries, expected tool use, intermediate responses, and a reference final response. An example evalset might include a session where the user first asks “What can you do?” and then says “Roll a 10 sided dice twice and then check if 9 is a prime or not,” defining expected roll_die tool calls and a check_prime tool call, along with the final response summarizing the dice rolls and the prime check.
智能体评估常见的载体有两类:测试文件(test files)和 evalset 文件。测试文件通常采用 JSON,描述相对简单的单次智能体-模型会话,适合开发阶段的快速单测,强调结构清晰、执行轻量。一个文件通常对应一个多轮会话;每轮包含用户查询、期望的工具调用轨迹、中间回复和最终回复。比如用户说「把卧室里的
device_2关掉」,系统就应调用set_device_info(如 location: Bedroom、device_id: device_2、status: OFF),并以「已将device_2关闭」这类话术收尾。测试集可以按目录组织,也可以配套test_config.json声明评估规则。Evalset 则更偏向集成场景:一个 evalset 可收录多条较长会话,用于复杂多轮对话或端到端回归;文件中包含多条 eval,每条 eval 又可包含一个或多个 turn,字段同样覆盖查询、期望工具轨迹、中间态与参考终答。比如用户先问能力边界,再要求「掷两次十面骰并判断 9 是否质数」,系统就需要校验roll_die、check_prime等调用是否按预期出现,以及最终汇总回复是否正确。
Multi-agents: Evaluating a complex AI system with multiple agents is much like assessing a team project. Because there are many steps and handoffs, its complexity is an advantage, allowing you to check the quality of work at each stage. You can examine how well each individual "agent" performs its specific job, but you must also evaluate how the entire system is performing as a whole.
多智能体: 评估复杂的多智能体系统,很像评估一个团队协作项目。由于环节和交接很多,反而更适合按阶段设置检查点;既要衡量各角色是否完成了自己的职责,也要评估整个系统的协同效果。
To do this, you ask key questions about the team's dynamics, supported by concrete examples:
可以围绕协作动态列出一份检查清单,再结合具体场景验证:
- Are the agents cooperating effectively? For instance, after a 'Flight-Booking Agent' secures a flight, does it successfully pass the correct dates and destination to the 'Hotel-Booking Agent'? A failure in cooperation could lead to a hotel being booked for the wrong week.
- Did they create a good plan and stick to it? Imagine the plan is to first book a flight, then a hotel. If the 'Hotel Agent' tries to book a room before the flight is confirmed, it has deviated from the plan. You also check if an agent gets stuck, for example, endlessly searching for a "perfect" rental car and never moving on to the next step.
- Is the right agent being chosen for the right task? If a user asks about the weather for their trip, the system should use a specialized 'Weather Agent' that provides live data. If it instead uses a 'General Knowledge Agent' that gives a generic answer like "it's usually warm in summer," it has chosen the wrong tool for the job.
- Finally, does adding more agents improve performance? If you add a new 'Restaurant-Reservation Agent' to the team, does it make the overall trip-planning better and more efficient? Or does it create conflicts and slow the system down, indicating a problem with scalability?.
- 协作是否闭环? 例如航班代理出票后,是否把准确日期与目的地交接给酒店代理?若握手失败,可能出现「订对航班、订错周」的荒诞结果。
- 计划是否被遵守? 既定顺序是先机票后酒店时,酒店代理是否在确认舱位前就锁房?亦需留意某个代理是否陷入「找完美租车」式死循环。
- 角色是否匹配任务? 用户问行程天气,应路由到能拉实时数据的天气代理;若通识代理只回一句「夏天一般很热」,属于典型的工具错配。
- 扩容是否真增效? 新增餐厅预订代理后,整体行程规划是更顺滑还是更撕扯、更慢?后者往往暴露编排或接口设计的扩展性债务。
From Agents to Advanced Contractors¶
从智能体到高级「承包商」¶
Recently, it has been proposed (Agent Companion, gulli et al.) an evolution from simple AI agents to advanced "contractors", moving from probabilistic, often unreliable systems to more deterministic and accountable ones designed for complex, high-stakes environments (see Fig.2)
近期研究(Agent Companion,Gulli 等)提出,应从简单智能体演进到高级「承包商」模式:也就是从概率性强、可靠性参差的设计,转向更适合复杂高风险任务、也更可预期、更可追责的体系(见图 2)。
Today's common AI agents operate on brief, underspecified instructions, which makes them suitable for simple demonstrations but brittle in production, where ambiguity leads to failure. The "contractor" model addresses this by establishing a rigorous, formalized relationship between the user and the AI, built upon a foundation of clearly defined and mutually agreed-upon terms, much like a legal service agreement in the human world. This transformation is supported by four key pillars that collectively ensure clarity, reliability, and robust execution of tasks that were previously beyond the scope of autonomous systems
当下很多智能体仍依赖简短、语义不充分的指令。这种方式在演示场景里还能运作,但一到生产环境,就常因歧义而失效。「承包商」范式正是为了解决这个问题:它在用户与 AI 之间建立起一套严谨、可执行的约定,条款清晰、双方确认,类似现实世界中的服务合同。其背后的四大支柱共同保障透明性、可靠性和稳健交付,让那些过去难以交给自主系统处理的高难任务,逐步变得可托付。
First is the pillar of the Formalized Contract, a detailed specification that serves as the single source of truth for a task. It goes far beyond a simple prompt. For example, a contract for a financial analysis task wouldn't just say "analyze last quarter's sales"; it would demand "a 20-page PDF report analyzing European market sales from Q1 2025, including five specific data visualizations, a comparative analysis against Q1 2024, and a risk assessment based on the included dataset of supply chain disruptions." This contract explicitly defines the required deliverables, their precise specifications, the acceptable data sources, the scope of work, and even the expected computational cost and completion time, making the outcome objectively verifiable.
第一支柱是正式化合约(Formalized Contract)。它用一份详尽规格充当任务的单一事实来源,远不是一句提示词能替代的。例如做金融分析时,不会只写「分析上季销售」,而会明确要求「提交 20 页 PDF,分析 2025 年 Q1 欧洲区销售,附五类指定图表、给出与 2024 年 Q1 的同比对照,并基于随附供应链扰动数据完成风险评估」。这类合约会把交付物形态、技术规格、可用数据源、工作边界,甚至算力和工期预期都写清楚,使验收真正有据可依。
Second is the pillar of a Dynamic Lifecycle of Negotiation and Feedback. The contract is not a static command but the start of a dialogue. The contractor agent can analyze the initial terms and negotiate. For instance, if a contract demands the use of a specific proprietary data source the agent cannot access, it can return feedback stating, "The specified XYZ database is inaccessible. Please provide credentials or approve the use of an alternative public database, which may slightly alter the data's granularity." This negotiation phase, which also allows the agent to flag ambiguities or potential risks, resolves misunderstandings before execution begins, preventing costly failures and ensuring the final output aligns perfectly with the user's actual intent.
第二支柱是谈判与反馈的动态生命周期。合约不是一次性命令,而是协商的起点;承包商智能体可以先审条款,再回传反馈。比如条款要求访问一个它根本拿不到权限的专有数据库,它就可以明确回复:「XYZ 库当前不可达,请提供凭证,或授权改用公开替代源(粒度可能略有差异)。」这一阶段也能提前暴露歧义与风险,减少上线后的返工与损失,并让最终交付更贴近用户真实意图。
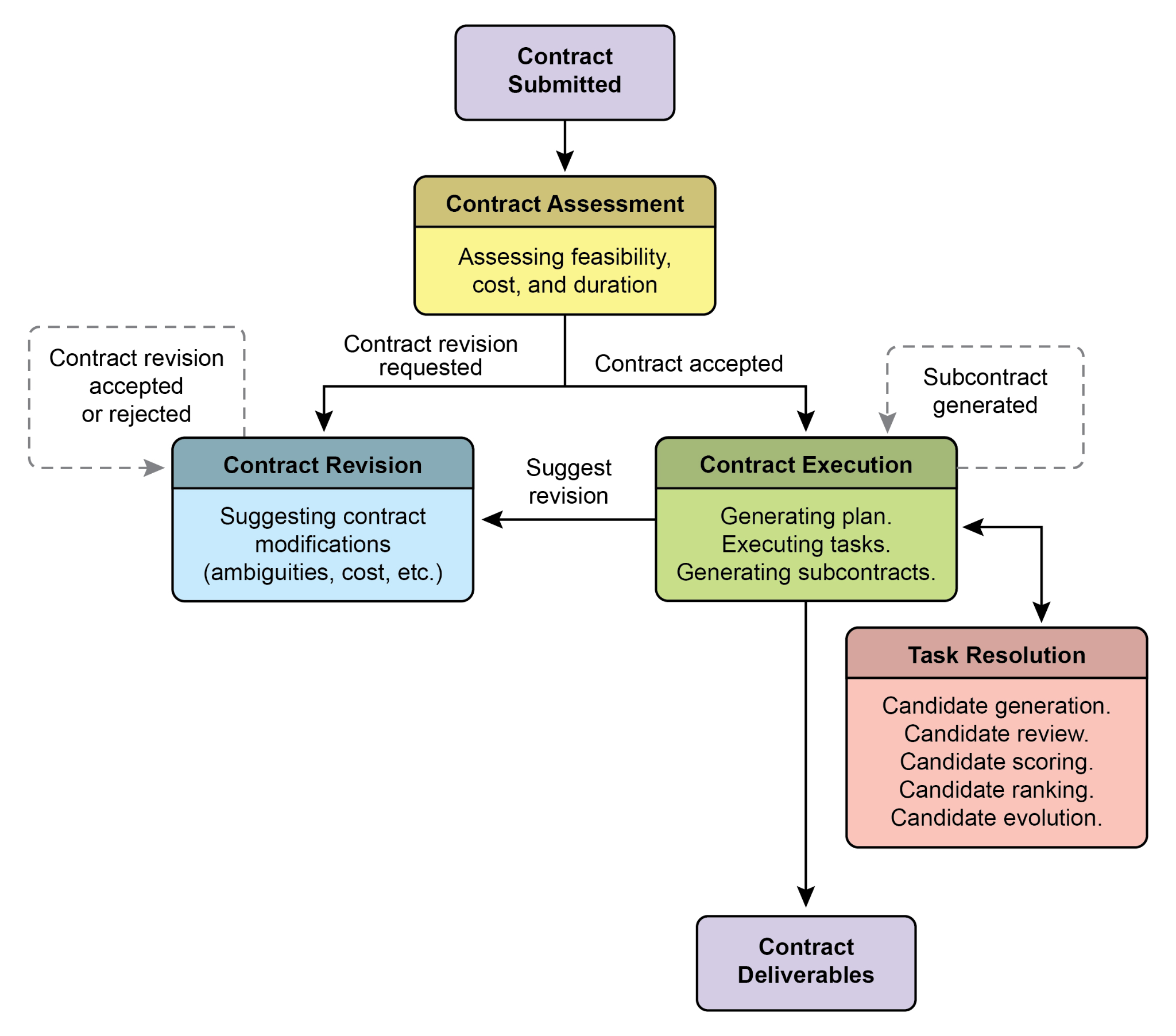
Fig. 2: Contract execution example among agents
图 2:智能体之间的合约执行示例
The third pillar is Quality-Focused Iterative Execution. Unlike agents designed for low-latency responses, a contractor prioritizes correctness and quality. It operates on a principle of self-validation and correction. For a code generation contract, for example, the agent would not just write the code; it would generate multiple algorithmic approaches, compile and run them against a suite of unit tests defined within the contract, score each solution on metrics like performance, security, and readability, and only submit the version that passes all validation criteria. This internal loop of generating, reviewing, and improving its own work until the contract's specifications are met is crucial for building trust in its outputs.
第三支柱是以质量为中心的迭代执行。与一味追求秒回不同,承包商把正确性和质量放在首位,内置自我校验与纠错机制。以代码生成为例,它不会只产出一份实现,而是可能并行尝试多种方案,在合约附带的单测上编译运行,再从性能、安全、可读性等维度打分,只提交满足全部门槛的版本。在规格达成前不断「生成 - 自检 - 改进」,正是这种模式赢得信任的关键。
Finally, the fourth pillar is Hierarchical Decomposition via Subcontracts. For tasks of significant complexity, a primary contractor agent can act as a project manager, breaking the main goal into smaller, more manageable sub-tasks. It achieves this by generating new, formal "subcontracts." For example, a master contract to "build an e-commerce mobile application" could be decomposed by the primary agent into subcontracts for "designing the UI/UX," "developing the user authentication module," "creating the product database schema," and "integrating a payment gateway." Each of these subcontracts is a complete, independent contract with its own deliverables and specifications, which could be assigned to other specialized agents. This structured decomposition allows the system to tackle immense, multifaceted projects in a highly organized and scalable manner, marking the transition of AI from a simple tool to a truly autonomous and reliable problem-solving engine.
第四支柱是借助子合约做层级分解。面对超大任务,主承包商可以像项目经理一样拆解目标,并为子任务签发正式的「子合约」。例如总目标是「交付一款电商移动应用」,就可以拆出 UI/UX、身份认证、商品库 schema、支付对接等多个子合约;每份子合约都带有自己的交付清单和验收标准,还可以进一步分派给专科智能体。这样的结构化拆解,让系统能以更可治理、也更可扩展的方式承接复杂项目,推动 AI 从被动工具演进为可托付的自主求解引擎。
Ultimately, this contractor framework reimagines AI interaction by embedding principles of formal specification, negotiation, and verifiable execution directly into the agent's core logic. This methodical approach elevates artificial intelligence from a promising but often unpredictable assistant into a dependable system capable of autonomously managing complex projects with auditable precision. By solving the critical challenges of ambiguity and reliability, this model paves the way for deploying AI in mission-critical domains where trust and accountability are paramount.
归根结底,承包商框架是把正式规格、协商机制和可验证执行直接写进智能体的核心逻辑,从而重塑人机协作方式。这样一来,AI 就不再只是「看似聪明却难预测」的助手,而会更接近一个能以可审计方式推进复杂项目的可靠伙伴。它直面歧义与可靠性这两大痛点,也为 AI 在强监管、强问责场景中的落地提供了现实路径。
Google's ADK¶
Google ADK¶
Before concluding, let's look at a concrete example of a framework that supports evaluation. Agent evaluation with Google's ADK (see Fig.3) can be conducted via three methods: web-based UI (adk web) for interactive evaluation and dataset generation, programmatic integration using pytest for incorporation into testing pipelines, and direct command-line interface (adk eval) for automated evaluations suitable for regular build generation and verification processes.
收尾前,再看一个具备评估能力的框架示例。借助 Google ADK(见图 3)评估智能体,大致有三种方式:使用 Web UI(
adk web)做交互式评测并沉淀数据集;使用 pytest 把评估嵌入 CI/CD 流程;或使用 CLI(adk eval)在构建与回归过程中批量执行评估。
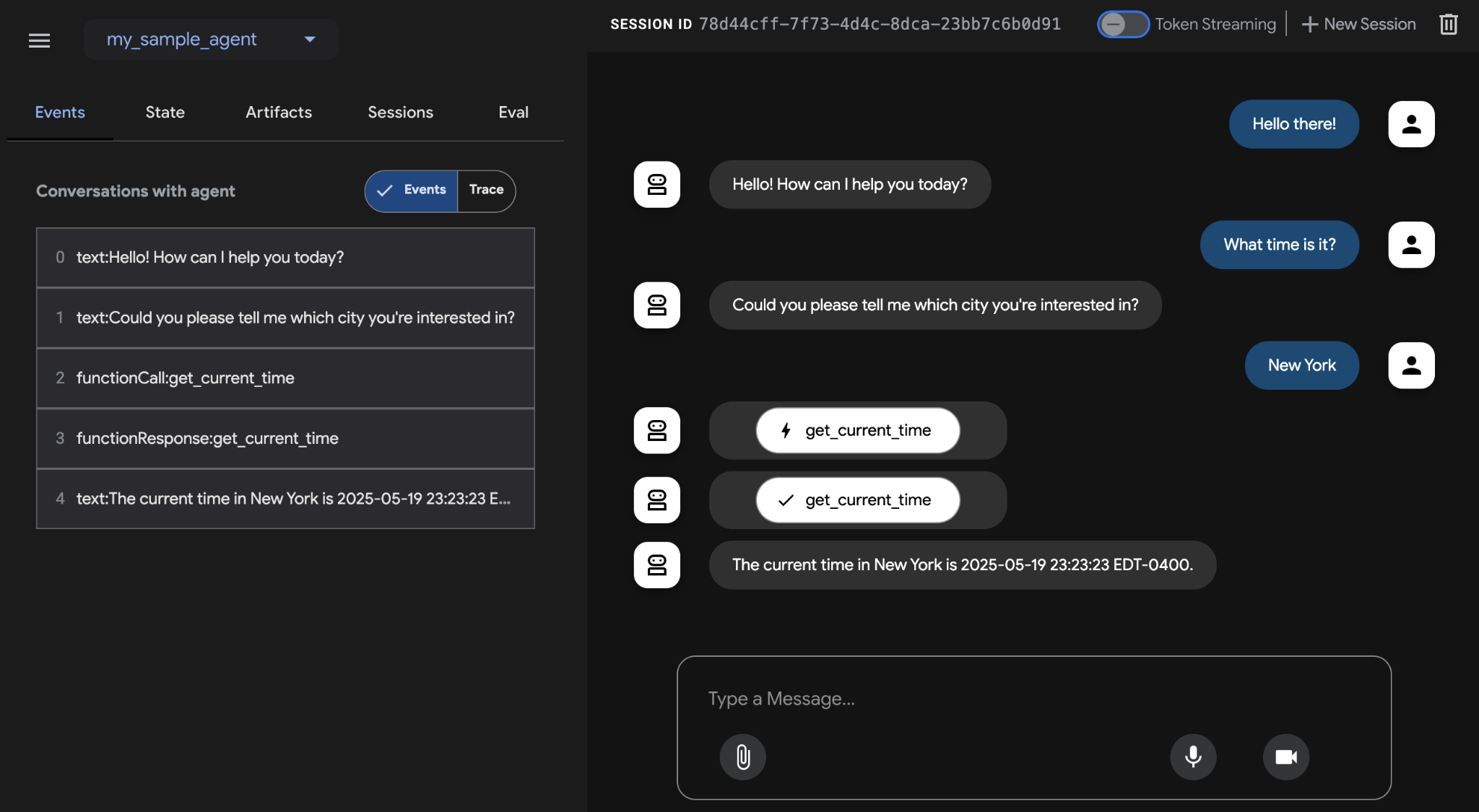
Fig.3: Evaluation Support for Google ADK
图 3:Google ADK 的评估支持
The web-based UI enables interactive session creation and saving into existing or new eval sets, displaying evaluation status. Pytest integration allows running test files as part of integration tests by calling AgentEvaluator.evaluate, specifying the agent module and test file path.
Web UI 支持交互式创建会话,并将结果写入已有或新建的 eval 集,同时实时展示评估状态。结合 pytest 时,只需调用
AgentEvaluator.evaluate,并传入智能体模块与测试文件路径,就能把评估用例纳入集成流水线。
The command-line interface facilitates automated evaluation by providing the agent module path and eval set file, with options to specify a configuration file or print detailed results. Specific evals within a larger eval set can be selected for execution by listing them after the eval set filename, separated by commas.
CLI 则通过指定智能体模块与 eval 集文件来触发自动化评估;你也可以附加配置文件,或输出更详细的结果。若只想执行大 eval 集中的部分子项,也可以在 eval 集名后用逗号列出目标 eval。
At a Glance¶
要点速览¶
What: Agentic systems and LLMs operate in complex, dynamic environments where their performance can degrade over time. Their probabilistic and non-deterministic nature means that traditional software testing is insufficient for ensuring reliability. Evaluating dynamic multi-agent systems is a significant challenge because their constantly changing nature and that of their environments demand the development of adaptive testing methods and sophisticated metrics that can measure collaborative success beyond individual performance. Problems like data drift, unexpected interactions, tool calling, and deviations from intended goals can arise after deployment. Continuous assessment is therefore necessary to measure an agent's effectiveness, efficiency, and adherence to operational and safety requirements.
是什么: 智能体与 LLM 运行在复杂多变的环境中,性能会随时间衰减;而概率性输出又让传统测试难以覆盖全部风险。多智能体系统与环境还会共同演化,因此更需要自适应的测试策略,以及能够刻画协作质量、而不只看单体分数的指标。系统上线后,还可能出现数据漂移、工具误用、链路异常与目标偏移,因此必须持续度量有效性、效率,以及对运营规范和安全红线的遵守情况。
Why: A standardized evaluation and monitoring framework provides a systematic way to assess and ensure the ongoing performance of intelligent agents. This involves defining clear metrics for accuracy, latency, and resource consumption, like token usage for LLMs. It also includes advanced techniques such as analyzing agentic trajectories to understand the reasoning process and employing an LLM-as-a-Judge for nuanced, qualitative assessments. By establishing feedback loops and reporting systems, this framework allows for continuous improvement, A/B testing, and the detection of anomalies or performance drift, ensuring the agent remains aligned with its objectives.
为什么: 统一的评估与监控体系,为持续衡量并守护智能体表现提供了方法论。它既要求为准确率、时延、资源消耗(如 token)建立可量化指标,也要求借助轨迹分析去理解推理链路,并用 LLM-as-a-Judge 等方法补足质性判断。再配合反馈闭环与报表机制,就能支撑迭代优化、对照实验,以及对异常和漂移的早期发现,让系统始终对齐业务与安全目标。
Rule of Thumb: Use this pattern when deploying agents in live, production environments where real-time performance and reliability are critical. Additionally, use it when needing to systematically compare different versions of an agent or its underlying models to drive improvements, and when operating in regulated or high-stakes domains requiring compliance, safety, and ethical audits. This pattern is also suitable when an agent's performance may degrade over time due to changes in data or the environment (drift), or when evaluating complex agentic behavior, including the sequence of actions (trajectory) and the quality of subjective outputs like helpfulness.
经验法则: 只要生产环境对实时性与可靠性有较高要求,就应采用这套模式;当你需要系统比较不同智能体版本或底座模型,以指导迭代时,也应引入它;在合规、安全、伦理审计等强约束场景下,它同样必不可少。尤其当数据或环境变化可能引发性能漂移,或需要评估复杂行为(如行动轨迹、主观维度「有用性」)时,这一模式更为关键。
Visual Summary:
图示摘要:
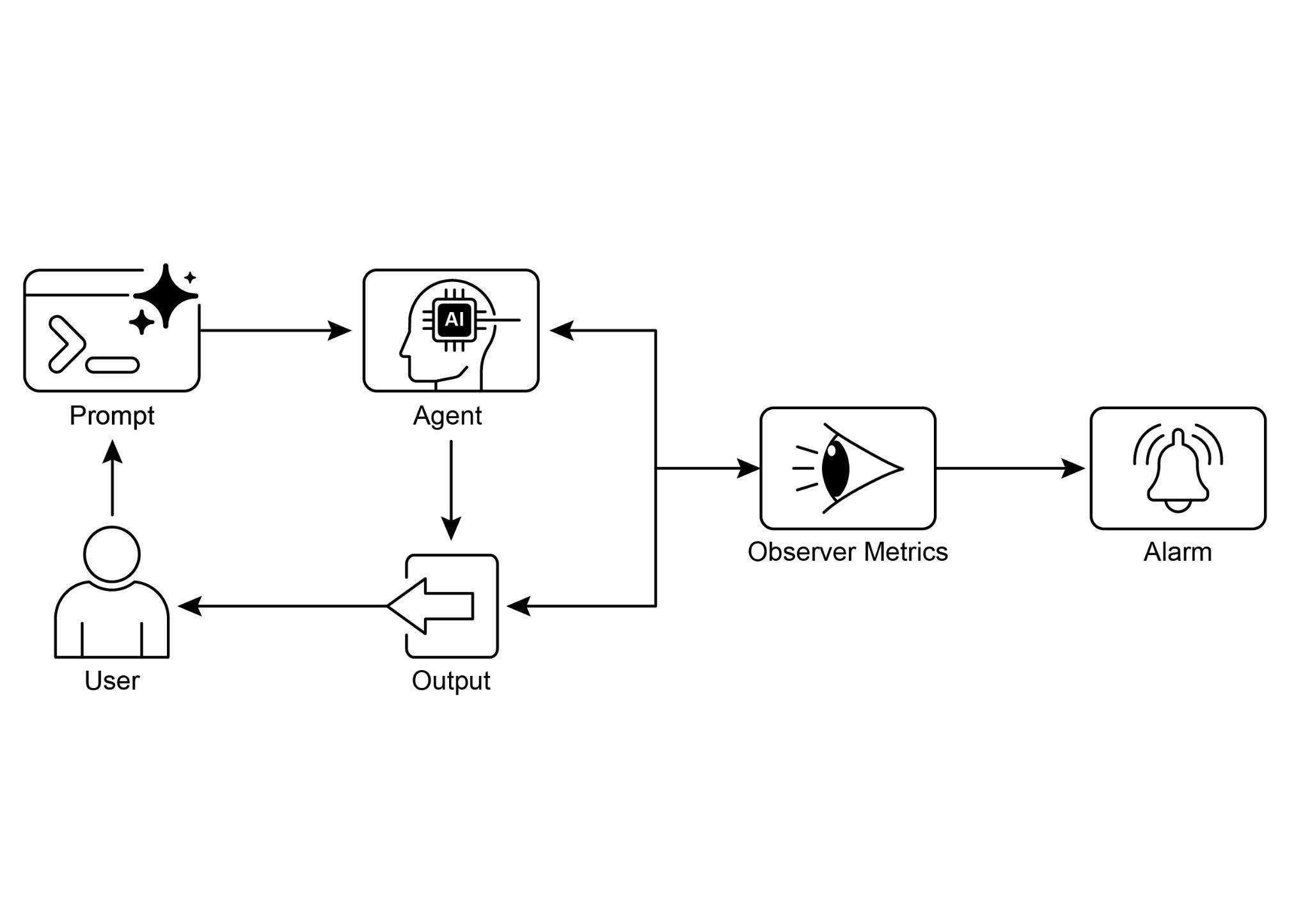
Fig.4: Evaluation and Monitoring design pattern
图 4:评估与监控设计模式
Key Takeaways¶
关键要点¶
- Evaluating intelligent agents goes beyond traditional tests to continuously measure their effectiveness, efficiency, and adherence to requirements in real-world environments.
- Practical applications of agent evaluation include performance tracking in live systems, A/B testing for improvements, compliance audits, and detecting drift or anomalies in behavior.
- Basic agent evaluation involves assessing response accuracy, while real-world scenarios demand more sophisticated metrics like latency monitoring and token usage tracking for LLM-powered agents.
- Agent trajectories, the sequence of steps an agent takes, are crucial for evaluation, comparing actual actions against an ideal, ground-truth path to identify errors and inefficiencies.
- The ADK provides structured evaluation methods through individual test files for unit testing and comprehensive evalset files for integration testing, both defining expected agent behavior.
- Agent evaluations can be executed via a web-based UI for interactive testing, programmatically with pytest for CI/CD integration, or through a command-line interface for automated workflows.
- In order to make AI reliable for complex, high-stakes tasks, we must move from simple prompts to formal "contracts" that precisely define verifiable deliverables and scope. This structured agreement allows the Agents to negotiate, clarify ambiguities, and iteratively validate its own work, transforming it from an unpredictable tool into an accountable and trustworthy system.
- 评估智能体不能停留在传统单测,而要在真实负载下持续度量有效性、效率与合规度。
- 典型落地包括线上指标看板、面向迭代的 A/B、合规与安全审计,以及对漂移与异常行为的监测。
- 入门可从回复正确率入手;生产级场景通常还要叠加延迟、token、成本与工具使用等维度。
- 行动轨迹是核心观测对象:把实际路径与金标准对照,可定位逻辑漏洞与资源浪费。
- ADK 以测试文件支撑快速单测,以 evalset 支撑更接近集成的场景,两者都显式描述期望行为。
- 执行层可选 Web 交互、pytest 嵌入流水线,或 CLI 批量回归。
- 若要在高风险任务上真正托付 AI,就需要从含糊提示升级为写明可验证交付物与边界的正式「合约」;结构化协议支持协商、消歧与自证,使系统从难以追踪的工具演进为可追责的协作伙伴。
Conclusions¶
结论¶
In conclusion, effectively evaluating AI agents requires moving beyond simple accuracy checks to a continuous, multi-faceted assessment of their performance in dynamic environments. This involves practical monitoring of metrics like latency and resource consumption, as well as sophisticated analysis of an agent's decision-making process through its trajectory. For nuanced qualities like helpfulness, innovative methods such as the LLM-as-a-Judge are becoming essential, while frameworks like Google's ADK provide structured tools for both unit and integration testing. The challenge intensifies with multi-agent systems, where the focus shifts to evaluating collaborative success and effective cooperation.
总之,评估智能体不能只盯着准确率,而要在动态环境中持续、立体地观测系统表现:既跟踪延迟、资源消耗等硬指标,也借助轨迹还原决策链路。对「有用性」这类软指标,LLM-as-a-Judge 正逐渐成为常用补充;Google ADK 等工具,则把单测与集成评估进一步产品化。多智能体场景会把难度继续抬高,因此评估重心也自然转向协作质量与任务衔接。
To ensure reliability in critical applications, the paradigm is shifting from simple, prompt-driven agents to advanced "contractors" bound by formal agreements. These contractor agents operate on explicit, verifiable terms, allowing them to negotiate, decompose tasks, and self-validate their work to meet rigorous quality standards. This structured approach transforms agents from unpredictable tools into accountable systems capable of handling complex, high-stakes tasks. Ultimately, this evolution is crucial for building the trust required to deploy sophisticated agentic AI in mission-critical domains.
要在关键业务里谈可靠性,行业就必须从「一句提示走天下」迈向受正式协议约束的高级「承包商」。承包商在可验证条款下运行,能谈判、拆解任务,并反复自检,直到满足严格的质量门槛。这条结构化路线,把智能体从难以预期的脚本提升为可审计的系统,使其足以承接复杂、高风险工作;这也是赢得监管与用户信任、在关键领域规模化部署智能体能力的前提。
References¶
Relevant research includes:
- ADK Web: https://github.com/google/adk-web
- ADK Evaluate: https://google.github.io/adk-docs/evaluate/
- Survey on Evaluation of LLM-based Agents, https://arxiv.org/abs/2503.16416
- Agent-as-a-Judge: Evaluate Agents with Agents, https://arxiv.org/abs/2410.10934
- Agent Companion, gulli et al: https://www.kaggle.com/whitepaper-agent-companion