AI 系列:Embedding 训练细节 & 数学原理
2025-09-06
Embedding model,几个典型问题:
- 作用:是什么、可以做什么?
- 训练:如何训练自己的模型?
- 评估:如何评估自己的模型?
- 选型:什么场景下使用什么模型?
- 应用:如何应用到实际场景中?
典型术语,含义:
InfoNCE全称是 Information Noise-Contrastive Estimation,最初用于互信息最大化,现在是对比学习里最常用的损失函数。CoSENT全称是 Contrastive Sentence (Embedding) Ordering Loss,是一种用于句子排序的损失函数。MSE全称是 Mean Squared Error,是最常见的回归损失函数之一,用来度量预测值与真实值差异的平方的平均值。STS全称是 Semantic Textual Similarity,是一种用于衡量句子语义相似度的任务。
其中,前 3 个都是损失函数,用于训练 embedding 模型;后 1 个是任务,用于评估 embedding 模型。
InfoNCE 损失函数,把正例的表征向量拉近 query,且把负例推远,使得在 embedding 空间内正例相似度最大化。当用 softmax 时,loss 实质上把正例的相似度当成“正确类别”的概率最大化。
\[\mathcal{L}_{\text{InfoNCE}} = -\log\frac{\exp(\operatorname{sim}(q,p)/\tau)}{\exp(\operatorname{sim}(q,p)/\tau)+\sum_{n\in\mathcal{N}}\exp(\operatorname{sim}(q,n)/\tau)}\]CoSENT 的核心思想不是直接回归 label 到 cosine,而是利用标注的相对排名信息,用 pairwise 的 log-sum-exp 来保持“相似度排序一致性”。论文里给出的一个(interaction)形式是:
\[\mathcal{L}_{\text{CoSENT}}=\log\!\Big(1+\sum_{(k,l):\; \text{label}(i,j)>\text{label}(k,l)}\exp\big(\lambda\big(f(k,l)-f(i,j)\big)\big)\Big)\]MSE 损失函数公式(若 label 在 [-1,1] 或 [0,5] 需先归一化到 sim 相同的取值范围):
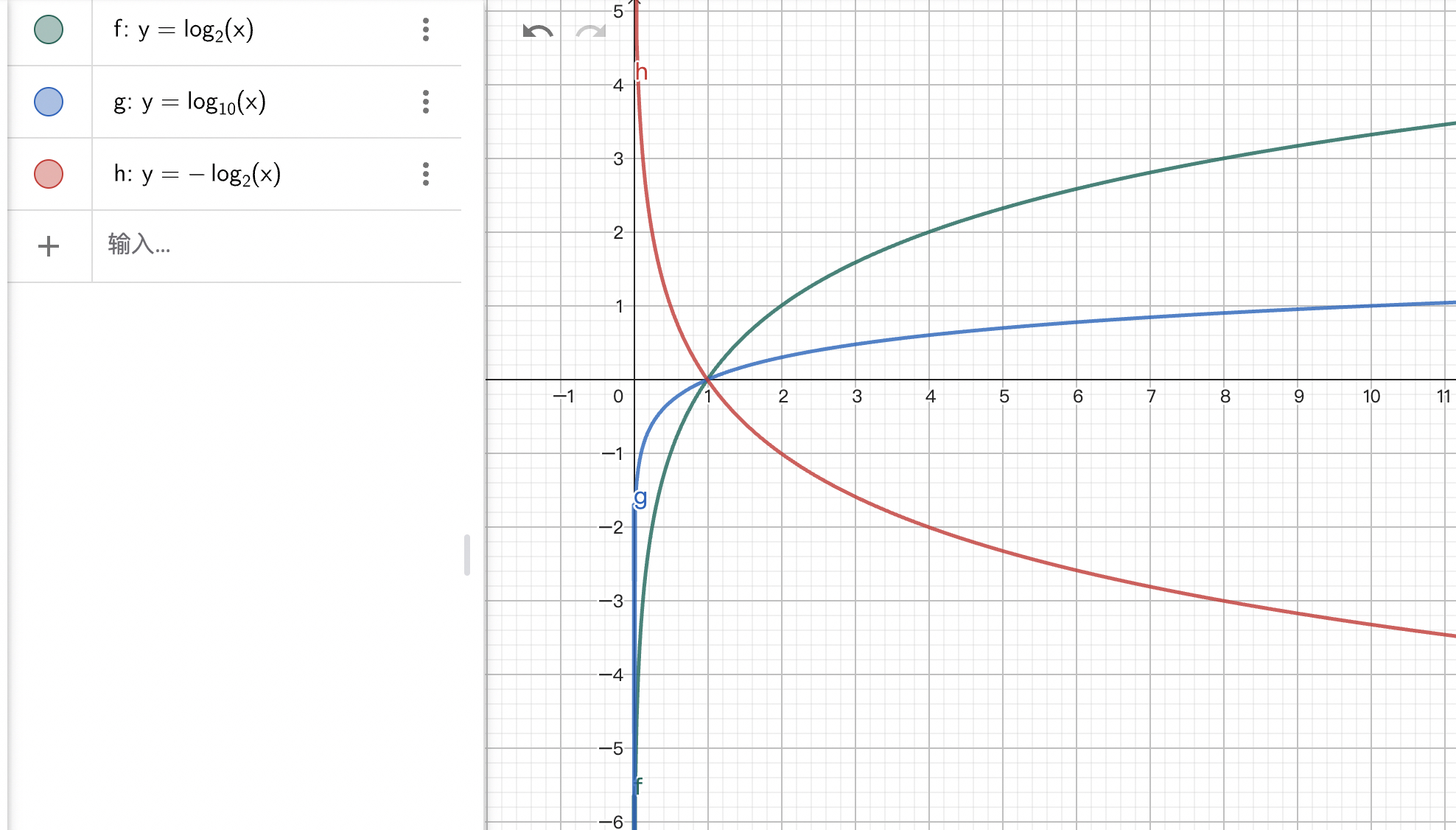
Embedding model(嵌入模型 / 向量表示模型)的原理,核心是:把离散的文本、图片、音频等信号,映射到连续的高维向量空间中,使得语义相似的输入,在向量空间的距离也更近。
下文按原理和训练过程,拆开讲。
1. 核心思想
- 目标:将文本(或其他模态)转化为稠密向量(dense embedding),让
语义关系在几何空间里可度量。 - 关键点:
- 语义相近的句子 → 向量相似度高(
余弦相似度/内积大); - 语义无关的句子 → 向量相似度低。
- 语义相近的句子 → 向量相似度高(
2. 模型结构
常见的 embedding 模型和大语言模型结构相似,主要分:
- 输入层:token embedding,把词/子词映射成向量。
- 编码层:Transformer/BERT 等结构,利用
自注意力机制捕捉上下文语义。 - 输出层:通常取
[CLS]token 或平均池化(mean pooling),得到固定维度的 sentence embedding。
2.1.Embedding vs LLM
embedding 模型(比如 BERT、SimCSE、BGE、M3E 等)和大语言模型(GPT、LLaMA、DeepSeek 等)在结构上确实有很多相似之处,但在训练目标、架构细节和使用方式上有差异。从以下几个维度对比。
2.1.1. 相似之处
-
底层架构:都是 Transformer
- embedding 模型和 LLM 都是基于 Transformer 编码器/解码器结构。
- 主要组件相同:
多头自注意力(Multi-head Self-Attention)、前馈网络(FFN)、层归一化(LayerNorm)、残差连接。 - 因此,它们都能学习到 上下文依赖 和 语义信息。
-
输入表示
- 都需要将
文本分词(tokenization),再映射到向量空间(embedding layer)。 - 常用 BPE、SentencePiece 等
分词算法。 - 都会加入
位置编码(Positional Encoding)。
- 都需要将
-
预训练数据规模
- 都依赖
大规模文本语料,利用无监督/自监督学习。
- 都依赖
2.1.2. 差异之处
-
训练目标不同
- Embedding 模型:目标是得到一个
语义向量,常见训练方式:- MLM(Masked Language Modeling) 掩码语言模型 →
BERT - 对比学习(Contrastive Learning) →
SimCSE,BGE,M3E - 多任务联合 → 融合检索/排序/分类任务
- MLM(Masked Language Modeling) 掩码语言模型 →
- LLM:目标是
生成下一个 token(自回归 LM),优化目标是最大化 token 序列的似然。
- Embedding 模型:目标是得到一个
-
架构差异
- Embedding 模型:常用 Encoder-only(如 BERT),得到整段文本的
语义向量。 - LLM 模型:常用 Decoder-only(如 GPT、LLaMA),适合
生成任务。 - 也有 Encoder-Decoder(如 T5、mBART),既能做 embedding,也能做生成。
- Embedding 模型:常用 Encoder-only(如 BERT),得到整段文本的
-
输出形式
- Embedding 模型:输出一个
定长向量(句子/段落语义表示),通常取[CLS]token 或平均池化。 - LLM:输出一个
token 分布序列,可以生成文本。
- Embedding 模型:输出一个
-
推理/使用方式
- Embedding 模型:常用于相似度计算、检索、聚类、分类。使用时一般是一次性编码,得到向量即可。
- LLM:常用于对话、写作、推理。使用时是逐 token 解码,带有上下文记忆。
-
参数规模
- Embedding 模型:参数量相对较小(几十 M 到几百 M)。
- LLM:参数量更大(几十 B 起步)。
2.1.3. 总结表格
| 维度 | Embedding 模型 | 大语言模型 (LLM) |
|---|---|---|
| 底层结构 | Transformer | Transformer |
| 常用架构 | Encoder-only |
Decoder-only |
| 训练目标 | 语义表示(MLM/对比学习) | 文本生成(自回归 LM) |
| 输出形式 | 固定向量 | Token 序列 |
| 应用方向 | 检索、聚类、排序、语义匹配 | 对话、写作、推理、代码生成 |
| 参数规模 | 较小(M~B 级) | 较大(B~T 级) |
可以这样理解:
- embedding 模型更像是“大语言模型的编码器部分”,专注于
压缩语义; - 而 LLM 则是解码器部分的放大器,专注于
生成。
2.2.输出向量
Embedding 模型:输出一个
定长向量(句子/段落语义表示),通常取[CLS]token 或平均池化
2.2.1. [CLS] token 是什么?
- 在 BERT 系列 embedding 模型里,每个输入序列都会在
最前面插入一个特殊符号 [CLS](classification token)。 - 它本身没有语义含义,但在训练过程中,模型会学会把整句话的全局信息“汇聚”到这个位置。
- 训练时常见做法:
- BERT 原论文里,做句子分类任务时,直接用
[CLS]的输出向量作为句子的整体表示,输入到分类器。
- BERT 原论文里,做句子分类任务时,直接用
2.2.2. 为什么可以取 [CLS] 向量作为句子 embedding?
- Transformer 是
全局注意力机制:- 每一层里,
[CLS]这个位置可以“看到”所有其他 token 的信息。 - 因此,经过多层 Transformer 后,
[CLS]向量会包含整个句子的综合语义。
- 每一层里,
- 简单说,模型学会了:
- “我要把全句的特征集中到
[CLS]里,方便下游任务用。”
- “我要把全句的特征集中到
2.2.3. 取 [CLS] vs 平均池化
常见的两种做法:
- 取
[CLS]向量- 直接拿最后一层
[CLS]hidden state(比如 768 维)。 - 优点:计算简单,语义浓缩。
- 缺点:依赖预训练时的任务设计,有时候泛化性不如平均池化,不稳定。
- 直接拿最后一层
- 平均池化(mean pooling)
- 对所有 token 的 hidden states 求平均,得到句子表示。
- 优点:更稳定,不依赖模型是否专门训练过
[CLS]。 - 缺点:可能稀释掉一些重要 token 的权重。
2.2.4. 实例
假设输入句子:
[CLS] 我 喜欢 学习 embedding 模型 [SEP]
-
Transformer 处理后,每个 token 都会得到一个向量表示:
H[CLS], H[我], H[喜欢], H[学习], H[embedding], H[模型], H[SEP] - 如果取
[CLS],就用H[CLS]作为整句 embedding。 -
如果做平均池化,就用所有 token 的向量求平均:
embedding = mean(H[我], H[喜欢], H[学习], H[embedding], H[模型])
2.2.5. 现代 embedding 模型的选择
- 早期:BERT → 多用
[CLS],取[CLS]token 的含义就是:用 BERT 模型训练时,专门设计的“全局语义汇聚点”来代表整个句子的向量。 - 后来:SimCSE、Sentence-BERT、BGE → 多用 平均池化,因为效果更稳健,特别是做检索/相似度任务时。
- 一些模型(如 M3E)还会混合策略:训练时用
[CLS],推理时用 mean pooling,这样兼顾效率与效果。
3. 训练方法
Embedding model 的训练过程,可以认为是:先预训练,然后再 对比学习、排序损失、多任务增强训练等微调。
3.0. 简述训练过程
Embedding model 的训练过程,通常分为两个大的阶段:
3.0.1. 预训练阶段 (Pre-training)
- 目标:让模型具备基本的语义理解能力。
-
做法:
- 使用大规模无标注文本进行 自监督训练(Masked Language Model,Next Sentence Prediction,或其他变体)。
- 输出的 Transformer 编码器学会对文本片段进行语义表示。
- 结果:模型能把语言结构、词语共现、句子关系学到,但此时输出的 embedding 还不一定适合下游任务(比如语义相似度计算、检索)。
例子:BERT、RoBERTa、ELECTRA 这些都是在大语料上预训练的语言模型。
3.0.2. 微调阶段 (Fine-tuning for Embedding)
在通用语义基础上,使用 有标注或弱标注数据,结合 对比学习、排序损失、多任务增强 来提升 embedding 的效果。
常见方法:
-
对比学习 (Contrastive Learning, 如 InfoNCE)
- 输入正负样本对
(q, pos, neg),拉近正样本 embedding,拉远负样本 embedding。 - 常用于语义匹配、检索。
- 输入正负样本对
-
排序损失 (Ranking Loss, 如 Triplet Loss, Pairwise Loss)
-
强调 排序关系,例如:
- 给定一个 query,它与文档 A 的相关性比文档 B 高 → 模型要保证
sim(q, A) > sim(q, B)。
- 给定一个 query,它与文档 A 的相关性比文档 B 高 → 模型要保证
-
-
回归损失 (Regression Loss, 如 MSE)
- 用在语义相似度标注任务 (STS, [0,5] 分)。
- 目标是让 embedding 的余弦相似度,接近标注分数。
-
分类损失 (Classification Loss, 如 CrossEntropy)
-
用在自然语言推理 (NLI) 数据上:
- premise-hypothesis 是 “蕴含” → 高相似度
- 是 “矛盾” → 低相似度
- 是 “中立” → 中间相似度
-
-
多任务增强 (Multi-task Training)
- 将上述任务组合,比如 InfoNCE + MSE + NLI CrossEntropy,一起训练。
- 可以避免单一任务过拟合,提高 embedding 的泛化能力。
总结起来:
- 预训练:大语料 → 学语言知识。
- 微调:对比学习 / 排序 / 回归 / 多任务 → 学相似度和检索能力。
这就是所说的 “先预训练 → 再微调(对比学习、排序、多任务)” 的完整流程。
通过 对比学习 + 排序损失 + 多任务增强-训练,来学习“语义空间”。
embedding 模型和普通语言模型不同,核心是相对相似性学习(contrastive learning)。
3.1.对比学习(Contrastive Learning)
-
InfoNCE / NT-Xent:给定一对
(query, positive),同时配上负例(negative),训练模型把正例拉近,负例推远。-
损失函数:
\[L = - \log \frac{\exp(\text{sim}(q, p) / \tau)}{\sum_{n}\exp(\text{sim}(q, n)/\tau)}\]
(sim 通常用 cosine similarity,
τ是温度系数) -
3.2.语义等价约束(CoSENT / Triplet Loss)
- CoSENT:要求语义相似的句子对相似度更高,且
顺序满足标注关系。- 比如 “今天天气真好” 和 “天气很好” 的相似度
>“今天天气真好” 和 “股市大跌”。
- 比如 “今天天气真好” 和 “天气很好” 的相似度
- 常见做法:排序损失(pairwise ranking loss)。
3.3.多任务监督
embedding 模型通常用多种任务联合训练:
- 语义匹配:自然语言推理(NLI)、相似句子匹配(STS)。
- 检索任务:query-document relevance。
- 分类任务:辅助学习,让 embedding 更鲁棒。
4. 评估指标
- 相似度任务:Spearman / Pearson 相关系数(和人工标注的相似度对比)。
- 检索任务:
MRR、Recall\@K、nDCG。 - 聚类任务:Silhouette score。
5. 常见模型分类
- Sentence-BERT (SBERT):典型
句向量模型,基于 BERT + 对比学习。 - SimCSE:自监督 + 对比学习,利用 Dropout 产生正样本。
- OpenAI text-embedding-ada-002 / 003:大规模语料预训练 + 多任务微调。
- 国内 BGE / M3E / XiaoBu: InfoNCE + CoSENT 混合,多任务、多语种增强。
Embedding model 的原理就是 把语义相似度转化为几何相似度,通过 对比学习 / 排序损失 / 多任务训练 来学习一个“语义空间”。
6.训练方法-要点
Embedding 模型,常见的训练方法:
- 联合训练:损失函数,加权求和
- 交替训练
- 分阶段训练:先无监督预训练
pre-train,再有监督fine-tune,这种复杂度低
常见做法,细节:
-
联合训练(simultaneous):总损失,为各种损失函数的加权求和
\[L_{total}=\sum_i \alpha_i L_i\]- 直接在同一 batch / 同一次反向传播里同时优化。
- 优点:共享表征、正则化效应;
- 缺点:不同任务/损失会有梯度冲突或量级差异,导致某些任务被“淹没”。可用 GradNorm / PCGrad 等方法缓解。
- 交替 / 轮换训练(alternating):每个 step 或每个 epoch 切换任务(或用不同 task-specific batches)。缓解权重调参问题,但训练调度更复杂。
- 分阶段(pretrain → finetune):先大规模用 InfoNCE/contrastive 无监督预训练,再用监督损失(如 CoSENT / MSE / ranking)微调(这是很常见且稳定的流程)。
下面会对每种损失函数,讨论其:公式、参数含义、物理(几何)含义、梯度直觉、优缺点和实战建议。
6.1.InfoNCE / Contrastive loss(包括检索场景下的 softmax 形式)
公式(query-style),给定 query \(q\)、一个正例 \(p\) 和负例集合 \(\mathcal{N}\):
\[\mathcal{L}_{\text{InfoNCE}} = -\log\frac{\exp(\operatorname{sim}(q,p)/\tau)}{\exp(\operatorname{sim}(q,p)/\tau)+\sum_{n\in\mathcal{N}}\exp(\operatorname{sim}(q,n)/\tau)}\]- \(\operatorname{sim}(\cdot,\cdot)\):相似度函数(常用
cosine或未经归一化的点积)。 - \(\tau\):temperature(温度),控制 softmax 的“尖锐度”。τ 越小,分布越尖锐(会更强烈地惩罚与正例相近的负例);τ 越大,loss 更平滑。
要点:
- 物理/几何含义:把正例的表征向量拉近 query,且把负例推远,使得在 embedding 空间内正例相似度最大化。当用 softmax 时,loss 实质上把正例的相似度当成“正确类别”的概率最大化。
- 梯度直觉:正例对梯度贡献为拉近方向;每个负例按其 softmax 权重被按比例推动远离。负例越“硬”(sim 接近正例),梯度贡献越大。
- 实战要点:
- 常用 trick:L2 归一化 embeddings(使用 cosine)并乘以 scale(等价于
1/τ)。 - 需要足够多的负例(大 batch 或 memory-bank / momentum encoder),负例数量 直接影响效果。
- 参考:InfoNCE 源/推导(CPC/InfoNCE)。
- 常用 trick:L2 归一化 embeddings(使用 cosine)并乘以 scale(等价于
InfoNCE 全称是 Information Noise-Contrastive Estimation,最初用于互信息最大化,现在是对比学习里最常用的损失函数。
NCE (Noise-Contrastive Estimation 噪声对比估计),是一种统计方法,用来把复杂的概率密度估计问题,转化为一个
二分类对比问题:区分“真实样本”和“噪声样本”。L2 归一化(也叫 向量标准化),是把向量长度缩放到 1,这样相似度计算就只和方向有关,而与长度无关。
6.2.NT-Xent(Normalized Temperature-scaled Cross Entropy,SimCLR 中的形式)
公式(对称版本,2N views):对 batch 中每一对正样本 (i,j),
总体 loss 对所有正对求平均(同时对称计算 \((i,j)\) 和 \((j,i)\))。
- 参数:同 InfoNCE 的 \(\tau\);2N 来自每个样本的两个增强视图。
- 物理含义:把“同一实例的两个增强视图”视为正例,把 batch 中其他视图视为负例,学习实例辨别性。常用于无监督/自监督预训练。
6.3. Triplet Loss(锚-正-负)
公式(距离版): 保持术语一致,原则上不考虑距离版本写法
\[\mathcal{L}_{\text{triplet}}=\max\big(0,\; d(a,p)-d(a,n)+m\big)\]或相似度版:推荐”相似度版”写法,语义越靠近、相似度越取值越高
\[\max\big(0,\; s(a,n)-s(a,p)+m\big)\]- \(d(\cdot,\cdot)\):距离(如欧氏);\(s\):相似度(如 cosine);\(m\):margin(边界)。
要点:
- 物理含义:要求 anchor 与 positive 的距离至少比与 negative 小 margin。margin 决定“安全带”的宽度:m 太大难以收敛,m 太小约束弱。
- 采样重要性:效果高度依赖正/负样本采样策略(随机/半困难/困难负样本)。Hard-negative mining 很关键。
- 优点/缺点:直观、可解释;但训练效率低(需要构造三元组)且对采样敏感。参考 FaceNet 等工作。
6.4. Pairwise margin / Ranking loss(用于排序/检索)
常见形式:
\[\mathcal{L}=\max\big(0,\; (s(q,n)-s(q,p)) + \text{margin}\big)\]或用 logistic/sigmoid 平滑:
\[\mathcal{L}=\log\big(1+\exp(\lambda (s(q,n)-s(q,p)))\big)\]- \(\lambda\):缩放系数(控制平滑/近似程度)。
- 物理含义:保证正例的得分高于负例,保留排序关系。logistic 形式把“违反约束”的差值通过软化的 exp/log-sum-exp 来累积。
6.5. Cross-entropy(softmax 分类式检索)
在检索任务中,把所有候选看作类(或把正例当作“正确类别”),用普通 Cross-Entropy 交叉熵损失:
这在实现上和 InfoNCE 是等价的(当每个 query 只有一个正例时)。因此 InfoNCE 可看作一种 softmax-CE 的对比式写法。
6.6. Supervised Contrastive Loss(SupCon)
公式(Khosla et al.),对样本 \(i\) 令 \(P(i)\) 为同一类的其他样本集合:
\[\mathcal{L}_i = -\frac{1}{|P(i)|}\sum_{p\in P(i)}\log\frac{\exp(\operatorname{sim}(z_i,z_p)/\tau)}{\sum_{a\neq i}\exp(\operatorname{sim}(z_i,z_a)/\tau)}\]再对 batch 求均值。
含义:把同类样本聚成簇,同时将不同类簇分开;把有标签信息的优势直接用在 contrastive 框架里(比单纯 CE 更强调表征簇结构)。
6.7. CoSENT(排名/一致性损失,针对 STS)
CoSENT 全称是 Contrastive Sentence (Embedding) Ordering Loss,是一种用于句子排序的损失函数。
STS = Semantic Textual Similarity(语义文本相似度),是一种用于衡量句子语义相似度的任务。
CoSENT 的核心思想不是直接回归 label 到 cosine,而是利用标注的相对排名信息,用 pairwise 的 log-sum-exp 来保持“相似度排序一致性”。论文里给出的一个(interaction)形式是:
\[\mathcal{L}_{\text{CoSENT}}=\log\!\Big(1+\sum_{(k,l):\; \text{label}(i,j)>\text{label}(k,l)}\exp\big(\lambda\big(f(k,l)-f(i,j)\big)\big)\Big)\]- \(f(i,j)\):模型对句对 \((i,j)\) 的得分(可用 cosine);
- 只对那些在标注上应当更相似但模型打分不满足的“逆序对”进行软惩罚;
- \(\lambda\):缩放因子,控制“违反差值”的放大程度(类似 temperature/scale)。
要点:
- 物理含义:把标注上的相似度排序尽可能保存在模型得分排序中,能更稳健地处理“hard negative”与非精确标注,同时训练与预测使用相同的相似度度量(论文里证明在很多 STS 数据集上效果很好且收敛快)。
CoSENT 损失函数,主要用在 STS(Semantic Textual Similarity)语义文本相似度(排序)场景。
CoSENT = Cosine Sentence (Embedding) Loss
- “Cosine” → 用 余弦相似度作为核心度量方式。
- “Sentence” → 针对句子语义相似度任务(特别是 STS)。
- 最早是苏剑林(似乎最早在 2022 年左右)提出的,主要用来改进 STS 训练。
在 STS 任务里,常见做法是:
- 输入句子对
(s1, s2),标签是相似度分数(如 0–5)。 - 传统方法:直接用 MSE 回归句子 embedding 的余弦相似度。
问题:MSE(Mean Squared Error, 平方差的平均值) 强制相似度和标签的数值接近,但实际下游任务只关心 排序关系,而不是数值拟合。比如:
- (A,B) 标签 4.9
- (A,C) 标签 4.7
即便模型预测 0.8 vs 0.7 也足够了,不需要强制预测 4.9/5。
CoSENT 的核心思想
把 STS 看作一个排序问题,而不是回归问题。
- 如果
(s1, s2)的标签 >(s1, s3),那么我们希望: \(\cos(s_1,s_2) > \cos(s_1,s_3)\) - 损失函数,就是对这些 “违反顺序” 的样本对进行惩罚。
CoSENT 的一种常见写法:
\[L = \log\Big(1+\sum_{(i,j)} \exp\big(\lambda \cdot (\cos(u_j,v_j)-\cos(u_i,v_i))\big)\Big)\]其中:
- \((i,j)\):所有“应该更相似”,但预测相似度却不满足的句对。
- \(\cos(\cdot,\cdot)\):embedding 的余弦相似度。
- \(\lambda\):缩放因子(类似 temperature,调节差距的放大程度)。
参数与物理含义:
- cos(u,v):句子语义的接近程度。
- λ(scale):
- λ 大 → 对排序错误敏感,梯度大,训练更激进。
- λ 小 → 训练平滑,但排序纠正不明显。
- loss 的几何意义:
- 如果模型预测的排序正确,loss≈0;
- 如果预测错误,差距越大,指数项越大,惩罚越强。
优势:
- 训练/预测一致性:训练时用的就是余弦相似度,预测时也直接用余弦,不存在 MSE 那种“训练指标 vs 预测指标不一致”。
- 关注排序:比回归更符合下游需求(检索、匹配、STS 都关心相对相似度,而不是具体分数)。
- 更快收敛:实测在 STS-B 等任务上,比 MSE、分类式 loss 更稳定。
应用场景:
- 中文 STS:LCQMC、ATEC、BQ Corpus 等。
- 语义检索:Query–Document 匹配。
- Embedding 训练微调:作为对比学习的轻量替代。
一句话总结:CoSENT 是一种基于余弦相似度的排序型损失函数,专门为 STS 设计,它不再回归具体分数,而是直接优化“语义相似度的排序关系”,训练与预测保持一致,效果更稳定。
6.8. MSE / Cosine-regression(直接回归相似度)
MSE = Mean Squared Error(均方误差),是最常见的
回归损失函数之一,用来度量预测值与真实值差异的平方的平均值。
公式(若 label 在 [-1,1] 或 [0,5] 需先归一化到 sim 相同的取值范围):
- 缺点:若 embedding 空间的分布与标签尺度不一致,直接回归会导致不稳定(且与 downstream 用 cosine 做检索时训练/测试不一致)。SBERT 曾用过 MSE,但实践中常与 ranking/contrastive 混合。
注意:
- 如果
标签取值范围比预测范围大很多,Loss 会很大,梯度也会非常大,导致训练不稳定(梯度爆炸)。- 归一化后,loss 数值会落在一个合理区间(通常 < 1),优化器更稳定。
6.9. 损失合并(Joint multi-loss)与权重策略
常见合并:
\[L_{\text{total}}=\alpha \cdot L_{\text{InfoNCE}} + \beta \cdot L_{\text{CoSENT}} + \gamma \cdot L_{\text{CE}} + \dots\]- \(\alpha,\beta,\gamma\):手工调参或用动态权重自适应(比如 GradNorm)学习。GradNorm 会动态调整各任务权重去平衡梯度大小;PCGrad/gradient-surgery 则直接在梯度层面消解任务间冲突(projection),避免互相“拉扯”。这些方法是多任务优化的常用工具。
6.10. 超参数/工程实战建议(汇总)
- temperature τ:常见范围
0.05–0.2(contrastive/simclr 场景);它影响 softmax 的“软/硬”程度。 - margin m(triplet):一般
0.1–0.5,视距离度量与归一化而定。 - scale / λ(ranking/logistic):控制 log-sum-exp 的陡峭度,类似于
1/τ。 - embedding 归一化:常做
L2-norm,配合cosine比较稳定。 - 负例数:越多越好(但计算成本上升)——用大 batch、memory bank、或 momentum encoder(MoCo)增加负例池。
- hard negative mining:对 margin/ranking/contrastive 都很关键;但要小心噪声样本导致模型崩溃(用 semi-hard 或按权重采样)。
- 调参顺序:常用策略 = 无监督大规模 contrastive(InfoNCE/NT-Xent)预训练 → 用监督损失(CoSENT / SupCon / ranking)微调 → 最后在目标数据上做小步 learning-rate 微调。
6.11. 小结(一句话)
多数现代 sentence/embedding pipeline 会结合多种损失:
- contrastive(InfoNCE/NT-Xent)负责通用区分能力,是否相关
- ranking/CoSENT/SupCon 则用标签/排序信息把 embedding 空间微调到下游任务需要的结构上。
- 是否“同时训练”取决于数据、任务和资源——联合训练能共享信息,但要用权重/梯度手段处理冲突;
- 分阶段训练,更稳定,但需要更多步骤。
M3E: Moka Massive Mixed Embedding Model,3个M
- Moka,此模型由 MokaAI 训练,开源和评测,训练脚本使用 uniem ,评测 BenchMark 使用 MTEB-zh
- Massive,此模型通过千万级 (2200w+) 的中文句对数据集进行训练
- Mixed,此模型支持中英双语的同质文本相似度计算,异质文本检索等功能,未来还会支持代码检索
关联资料
RAG两大核心利器: M3E-embedding和bge-rerank
原文地址:https://ningg.top/ai-series-embedding-model-details/