理解 LLM 原理
2025-06-28
从基础开始,一步一步带你了解一个大语言模型(LLM)是如何诞生的。你会看到一个“从文本 → 模型 → 智能输出”的完整流程,就像训练一个AI“语言小脑”的过程。
LLM 的架构图,包含核心组件:
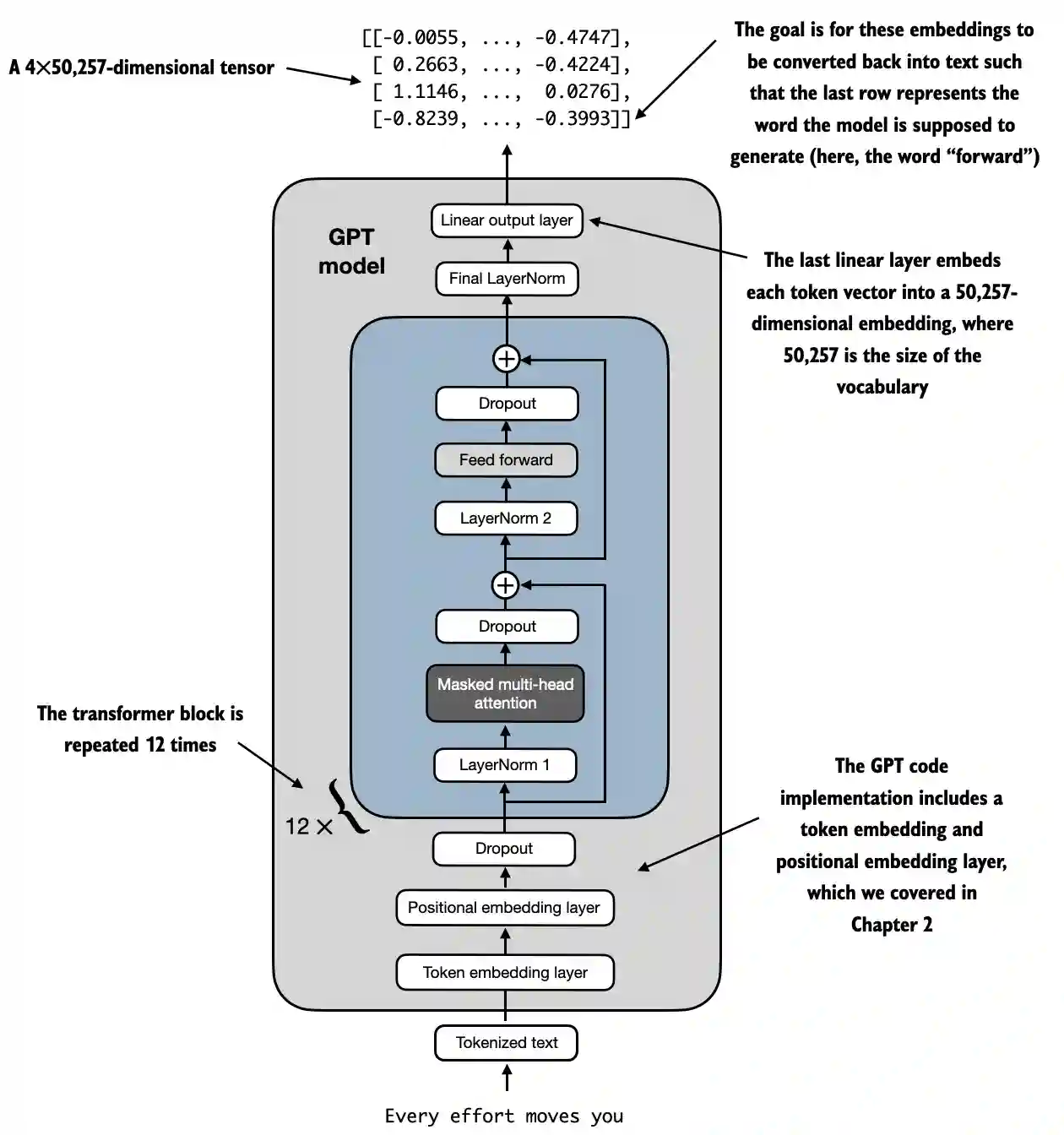
目标:从 0 理解 LLM 的 7 个核心阶段
我们用通俗语言讲解每一阶段的原理、作用和关键概念。
阶段 1:Tokenization(分词)
目标:把「人类语言」变成「数字」
举个例子:
输入句子:I love AI.
要让模型能理解,它得变成数字,比如:
"I" → 103
"love" → 412
"AI" → 987
"." → 27
有哪些常用 Tokenizer?
- 字符级(小模型):每个字符是一个 token →
["I", " ", "l", "o", "v", "e"] - 单词级:一个词是一个 token
- BPE(Byte Pair Encoding)(主流):将高频子词组合成 token,例如
["un", "lik", "ely"] - SentencePiece / Tokenizer by OpenAI(tiktoken):高效,支持子词、空格、标点等编码方式
阶段 2:构建模型结构(Transformer)
目标:构建能理解句子关系的神经网络
核心是 Transformer 架构,最早来自论文《Attention is All You Need》。
基本组成:
- Embedding 层:把 token 数字转为向量,比如 103 → [0.23, -0.8, …]
- 位置编码:告诉模型每个词的位置顺序
- Self-Attention:让每个词都能“关注”句子中其他词(比如 “not happy” 中,”not” 影响了 “happy”)
- MLP 层:做最终的特征提取和预测,参考附录A.
- Residual & LayerNorm:帮助训练稳定
多个 Transformer Block 叠在一起,就能“更深地理解”语言含义。
阶段 3:训练循环(输入、输出、损失函数)
目标:让模型通过看大量文字,学会「预测下一个词」
训练方法非常简单,但高效:
输入:I love
目标:love AI
每次让模型预测下一个词是什么,如果预测错了,就调整模型内部参数(反向传播)。
损失函数:
- 通常用 交叉熵(Cross Entropy Loss)
- 越接近真实的词,Loss 越低
阶段 4:准备训练数据
目标:喂给模型「海量、高质量」文本
常用的数据集:
- Wikipedia(百科全书)
- BookCorpus(小说文本)
- Common Crawl(互联网页面)
- GitHub、Reddit、新闻等
特点:
- 越多越好(LLM通常训练几百 GB ~ TB 级数据)
- 清洗质量很关键(去广告、乱码等)
数据通常要变成 token 编号后才能送进模型训练。
阶段 5:模型训练(大脑学习)
目标:真正让模型「从文本中学习语言规律」
你可以理解为:“大脑开始读书,逐渐变聪明”
技术细节:
- 优化器:通常用 AdamW(适合 NLP)
- 多 GPU 并行:分布式训练
- 混合精度训练(FP16):更快,省显存
- 梯度裁剪:防止爆炸
训练几小时到几周不等,依规模而定。
阶段 6:推理 & 采样(模型输出)
目标:让模型「写出新句子」或「回答问题」
流程:
- 给模型输入开头 → “I love”
- 模型预测下一个词 → “you”
- 把预测结果接到输入上,再次预测下一个 → “so”
- 重复直到达到长度或遇到结束符
常见采样方式:
| 方法 | 说明 |
|---|---|
| Greedy | 每次选概率最大的 |
| Top-k | 只在前 k 个最高概率中选 |
| Top-p(nucleus) | 在累计概率达到 p 的词中随机选 |
| 温度 sampling | 加 randomness,控制创造性 |
附录
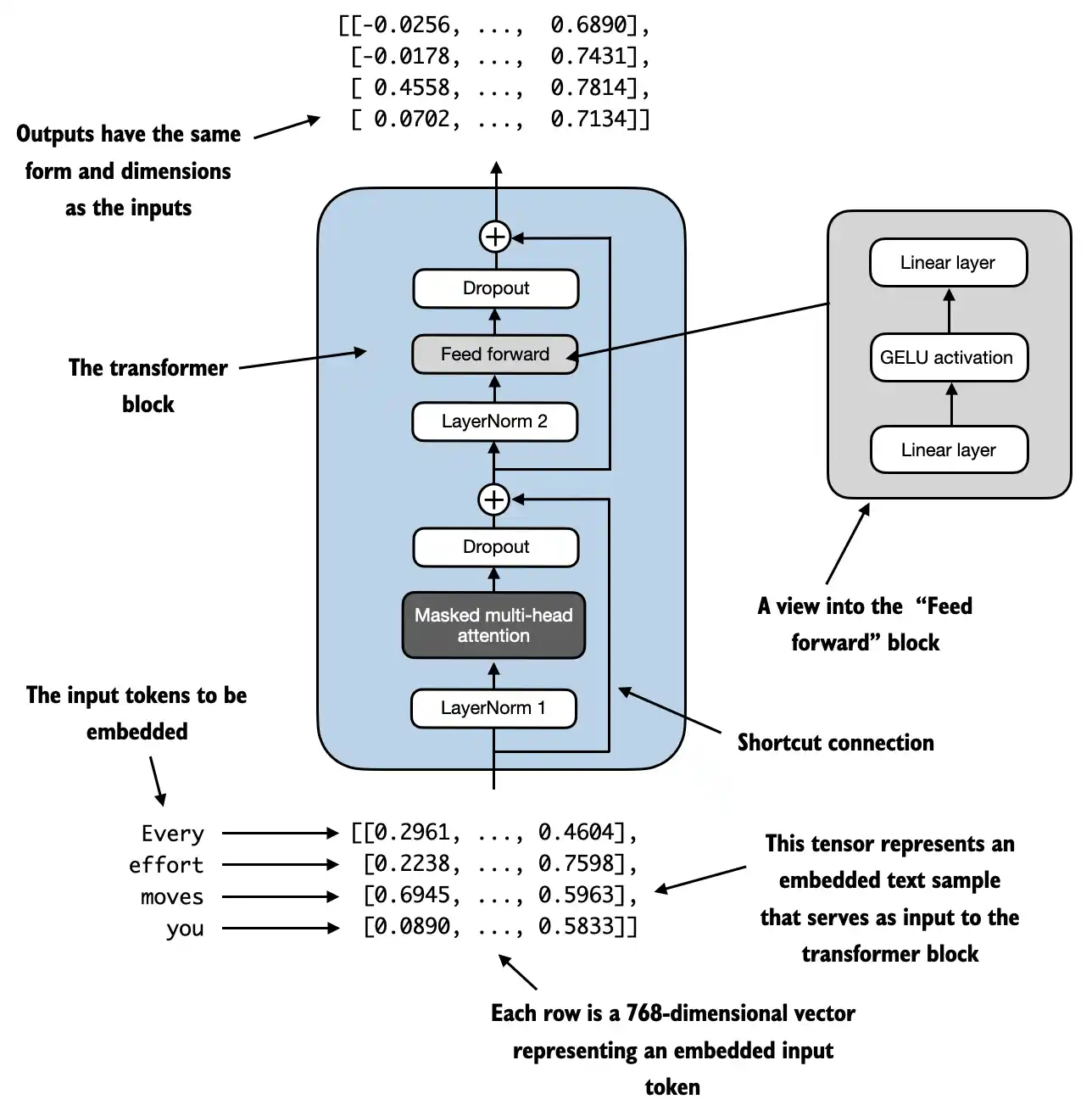
附录A. MLP 层
在大型语言模型(LLM)的 Transformer 架构中,MLP 层(Multi-Layer Perceptron Layer),也常被称为前馈神经网络层(Feed-Forward Network Layer, FFN Layer),是构成 Transformer 基本块(Block)的核心组件之一。它紧跟在自注意力层(Self-Attention Layer)之后。
它的主要作用和特点如下:
- 位置:
- 每个 Transformer 块(包含自注意力层和 MLP 层)的结构通常是:
输入 -> 层归一化(LayerNorm) -> 自注意力 -> (残差连接) -> 层归一化(LayerNorm) -> MLP 层 -> (残差连接) -> 输出。 - 所以,MLP 层是每个 Transformer 块的后半部分。
- 每个 Transformer 块(包含自注意力层和 MLP 层)的结构通常是:
- 结构:
- MLP 层本身是一个相对简单的两层全连接神经网络。
- 典型结构(以原始 Transformer 为例):
- 输入: 自注意力层输出的每个词元(Token)的向量表示(维度为
d_model,例如 768, 1024, 4096 等)。 - 第一层(扩展层/隐藏层): 一个全连接层(Linear Layer),通常将输入维度
d_model大幅扩展(例如扩展到4 * d_model)。这一层后面跟着一个非线性激活函数(如 ReLU, GELU - 在 LLM 中 GELU 更常用)。 - 第二层(收缩层/输出层): 另一个全连接层(Linear Layer),将扩展后的维度(例如
4 * d_model)压缩回原始的输入维度d_model。 - 输出: 一个与输入维度相同的向量(
d_model)。
- 输入: 自注意力层输出的每个词元(Token)的向量表示(维度为
- 公式表示(忽略偏置项):
FFN(x) = W₂ * GELU(W₁ * x)x: 输入向量(维度d_model)W₁: 第一层权重矩阵(维度d_model x d_ff,d_ff通常是4 * d_model)GELU: 激活函数(高斯误差线性单元)W₂: 第二层权重矩阵(维度d_ff x d_model)- 输出:维度
d_model
- 核心作用:
- 提供非线性变换能力: 这是 MLP 层最核心的作用。自注意力层擅长捕捉序列中不同位置词元之间的关系(相关性),但它本身主要是由线性操作(矩阵乘法)和 Softmax(非线性)组成的,其输出的组合方式仍然是相对线性的。MLP 层通过其内部的激活函数(如 GELU)引入了强大的非线性变换能力。
- 独立处理每个位置的信息: 与自注意力层不同(它需要查看序列中所有其他位置的词元来计算当前词元的表示),MLP 层独立地对序列中每个位置的表示进行处理。它只接收该位置自注意力层输出的向量,并对其进行变换,不直接与其他位置的词元交互。
- 学习复杂特征和模式: 这种独立的非线性变换允许模型学习比自注意力层捕获的关系更复杂、更抽象的特征和模式。它可以对自注意力层聚合的信息进行提炼、转换和深化理解。
- 增加模型容量(参数量): MLP 层(尤其是其扩展层
d_ff = 4 * d_model)包含了 Transformer 块中绝大多数的可学习参数(参数数量通常远超自注意力层)。这些参数为模型提供了强大的学习和表达能力。
- 为什么需要它? 想象一下,如果没有 MLP 层,Transformer 块就只剩下自注意力层和归一化层。自注意力层虽然能理解词元之间的关系,但它缺乏对单个词元表示进行深度、非线性加工的能力。模型学习复杂函数(如自然语言理解和生成)的能力将大大受限。MLP 层提供了这种关键的“深度加工”能力,使模型能够将自注意力层学到的上下文信息转化为更丰富、更可用的表示,传递给后续层或用于最终预测。
总结:
在 LLM 的 Transformer 架构中,MLP 层(或 FFN 层)是一个独立作用于序列中每个位置的小型两层神经网络。它的核心功能是对自注意力层输出的表示施加强大的非线性变换,从而学习更复杂的特征和模式,极大地增强模型的表达能力。它是 Transformer 块不可或缺的组成部分,贡献了模型大部分的参数量。
关联资料
- 知乎:入门大语言模型(LLM)看哪本书好呀?
- 大模型技术 30 讲
- Build a Large Language Model (From Scratch) 中文版
- 百面大模型
- 大语言模型(赵鑫) 包含电子版
- Happy-LLM:从零开始的大语言模型原理与实践教程
- www.newsletter.swirlai.com SwirlAI Newsletter 是一份涵盖 AI 工程(AI Engineering)、数据工程(Data Engineering)、机器学习(ML)、MLOps 等内容的专业知识型通讯,致力于以简明、易读的方式分享复杂的概念与实际经验
- https://medium.com/ 直接检索所有技术要点.
原文地址:https://ningg.top/ai-series-llm-intro-simple/