AI 实践:RAG 总结 & 实践
2025-08-30
0.概要
复述是最好的学习(也有人讲:分享是最好的学习)。
GitHub 上,原文地址:可以直接 fork 一份.
最近几周工作上,接触些 RAG 内容,看了点资料;本着最好的学习是复述原则,把所有要点,重新梳理下。
思路:
- RAG 解决什么问题?
- RAG 核心原理、核心组件
- RAG 高级技术,不同组件的高级用法
- 效果评估
- 后续发展方向
1.RAG 解决什么问题
LLM 基于大规模数据的预训练,获取的通用知识。对于私有数据和高频更新数据,LLM 无法及时更新。如果采用 Fine-Tuning 监督微调方式,LLM 训练成本也较高,而且无法解决幻觉问题。
即,私有数据和高频更新数据,以及幻觉问题,LLM 模型自身解决成本较高,因此,引入 RAG Retrieval Augmented Generation 检索增强生成。
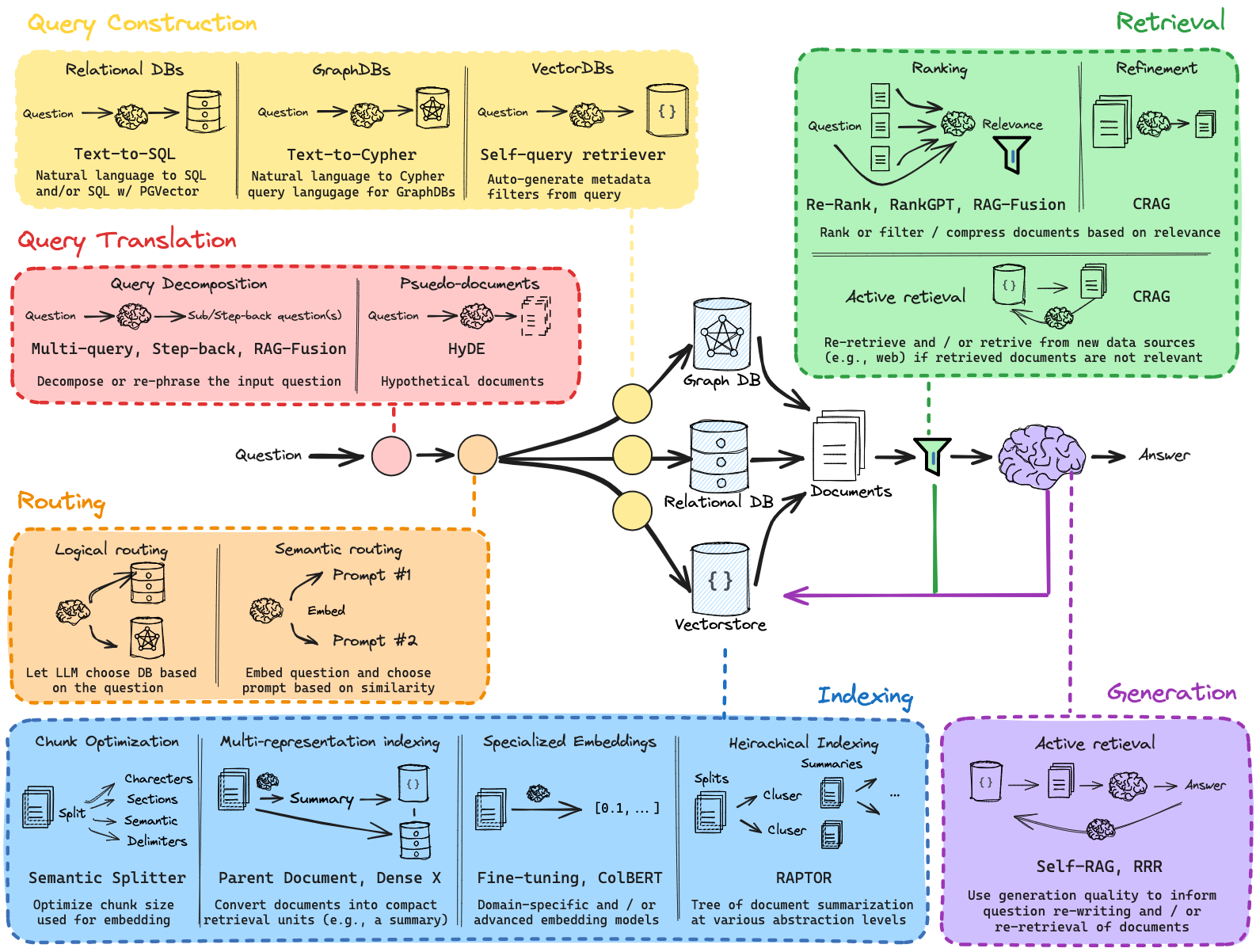
2.核心原理
RAG 检索增强生成:通过检索外部数据源信息,构造融合上下文(Context),输入给 LLM,获取更准确的结果。
核心环节:
- a.索引(indexing)
- b.检索(retrieval)
- c.生成(generation)
下述 RAG 架构图中,出了上面 3 个核心环节,还有:查询优化、路由、查询构造
- 查询优化(Query Translation):查询重写 multi-query、查询扩展 sub-question、后退查询 step-back query、 HYDE 假设性文档嵌入;
- 路由(Routing):根据查询,判断从哪些数据源,获取信息;
- 查询抽取(Query Construction):从原始 Query 中,抽取 SQL、Cypher、metadatas,分别用于 关系数据库、图数据库、向量数据库的查询。
开始之前,先在本地安装好 Ollama,并且下载好 embedding model 和 language model。
# 安装 Ollama
pip install ollama
# 下载 embedding model 和 language model
ollama pull nomic-embed-text
ollama pull deepseek-r1:8b
安装依赖:
! pip install langchain_community tiktoken langchain-ollama langchainhub chromadb langchain
2.1. RAG Oveview
提前设定环境变量:
import os
# os.environ['OPENAI_API_KEY'] = '<your-api-key>'
# os.environ['COHERE_API_KEY'] = '<your-cohere-api-key>'
完整的 indexing、retrieval、generation 实例代码如下:
import bs4
from langchain import hub
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_ollama import OllamaLLM, OllamaEmbeddings
#### 1.INDEXING ####
# Load Documents
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
# Split
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
# Embed
vectorstore = Chroma.from_documents(
documents=splits,
embedding=OllamaEmbeddings(model="nomic-embed-text"))
retriever = vectorstore.as_retriever()
#### 2.RETRIEVAL and 3.GENERATION ####
# Prompt
# Pull a pre-made RAG prompt from LangChain Hub
prompt = hub.pull("rlm/rag-prompt")
print(prompt)
# LLM
llm = OllamaLLM(model="deepseek-r1:8b")
# Post-processing
# Helper function to format retrieved documents
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# Helper function to remove <think> part in the text
def remove_think_tags(text):
"""remove <think> part in the text"""
cleaned_text = re.sub(r'<think>.*?</think>', '', text, flags=re.DOTALL)
cleaned_text = re.sub(r'\n\s*\n', '\n', cleaned_text)
return cleaned_text.strip()
# RAG Chain
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
# | remove_think_tags
)
# Question
# Ask a question using the RAG chain
response = rag_chain.invoke("What is Task Decomposition?")
print(response)
2.2. Indexing
几个方面:
- Tokenizer:分词,文本会被拆分成 token,映射到词表中 tokenID。
- Embedding:嵌入,将 tokenID 映射到向量空间中,得到 token 的向量表示。
- Chunk:分块,将文本拆分成多个 chunk,每个 chunk 包含多个 token。
- Index:索引,将 chunk 的向量表示存储到向量数据库中。
2.2.1.Token
更多细节, Count tokens and ~4 char / token
Token :机器/模型的分词结果,在词表中的 index;跟传统的人类分词,不是一个等同的概念,但是是强相关的。Token 可以认为是
模型的分词结果,基于 字节对编码(BPE)、SentencePiece 等算法,跟人类的分词结果,不完全一致,但是,思路是一致的。
查看下面分词得到的 Token:
import tiktoken
# Documents
document = "My favorite pet is a cat."
question = "What kinds of pets do I like?"
# count token num
def num_tokens_from_string(string: str, encoding_name: str) -> int:
"""Returns the number of tokens in a text string."""
encoding = tiktoken.get_encoding(encoding_name)
tokenIDs = encoding.encode(string)
print('tokenIDs: ' + str(tokenIDs))
num_tokens = len(tokenIDs)
return num_tokens
# use cl100k_base encoding
result = num_tokens_from_string(question, "cl100k_base")
print('token num: ' + str(result))
2.2.2.Embedding
Ollama Embedding ,实例:
from langchain_ollama import OllamaEmbeddings
embd = OllamaEmbeddings(model="nomic-embed-text")
query_result = embd.embed_query(question)
document_result = embd.embed_query(document)
result = len(query_result)
print('query_result: ' + str(query_result))
print('embedding dim: ' + str(result))
衡量 2 个 embedding 结果的关联关系,使用 cosine similarity:
import numpy as np
def cosine_similarity(vec1, vec2):
dot_product = np.dot(vec1, vec2)
norm_vec1 = np.linalg.norm(vec1)
norm_vec2 = np.linalg.norm(vec2)
return dot_product / (norm_vec1 * norm_vec2)
similarity = cosine_similarity(query_result, document_result)
print("Cosine Similarity:", similarity)
cosine similarity余弦相似度,物理含义:两个向量的相关性、相似度。
2.2.3.Chunk
LangChain 提供了关联工具:
- Document Loaders:加载各类文档数据,并转换为 LangChain 的 Document 标准对象。
- Text Splitters:将文本拆分成多个 chunk,每个 chunk 包含多个 token。
下面使用 RecursiveCharacterTextSplitter 进行分割:
# Split
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=300,
chunk_overlap=50)
# Make splits
splits = text_splitter.split_documents(blog_docs)
# Print splits
print("Print splits 1:" + splits[0])
在线尝试各种 文本分割器: [https://langchain-text-splitter.streamlit.app/] ,可以直观感受各种细节。
RecursiveCharacterTextSplitter 递归字符文本切分:尽量保证
语义单元(段落\句子\单词等),并支持chunk 之间有重叠。原理要点
递归分割思想
- 它会定义一个 分隔符列表(比如
["\n\n", "\n", "。", ",", " "])。- 从“最强分隔符”开始尝试切分(通常是段落级别
\n\n),如果小于chunk_size,则,会尝试拼接上同级别的下一个分块,否则,直接独占一个 chunk。- 如果切出来的片段还是太长(超过
chunk_size),就递归地用更细的分隔符继续切(如句子、逗> 号、空格)。- 如果到了最后一级分隔符还太长,就直接 硬切字符。
保证:尽量按“语义单元”切分,而不是随便截断。
重叠窗口(
chunk_overlap)
- 为了避免模型“上下文割裂”,它支持 chunk 之间有重叠。
例如
chunk_size=1000, overlap=200,则切分结果是:[0:1000], [800:1800], [1600:2600], ...- 这样能保持语义连续性(防止关键句子被切断后丢失上下文)。
平衡语义完整性与长度限制
- RAG、embedding 等应用对输入长度有限制(如 512/1024 tokens)。
- 该算法既要保证 chunk 不超过限制,又要尽量保持 语义完整性(不打断段落/句子)。
鲁棒性
- 如果文本缺少常见分隔符(比如一长段 HTML 或 JSON),递归策略仍能保证最后能切开(最坏情况就> 是硬切字符)。
总结一句话:
RecursiveCharacterTextSplitter = 按语义单元优先的递归切分 + 重叠窗口机制, 目标是:
- 尽量保留自然语义边界(段落/句子)
- 又能保证每块符合 LLM 输入限制
2.2.4.Index
有多种向量数据库,下面使用 Chroma 进行演示:
# Index
from langchain_ollama import OllamaEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=splits,
embedding=OllamaEmbeddings(model="nomic-embed-text"))
retriever = vectorstore.as_retriever()
2.3. Retrieval
上面建好了索引,现在进行检索:
# 返回 k 个最相关的文档
retriever = vectorstore.as_retriever(search_kwargs={"k": 1})
docs = retriever.get_relevant_documents("What is Task Decomposition?")
print(f"Retrieved {len(docs)} documents")
print(docs[0])
2.4. Generation
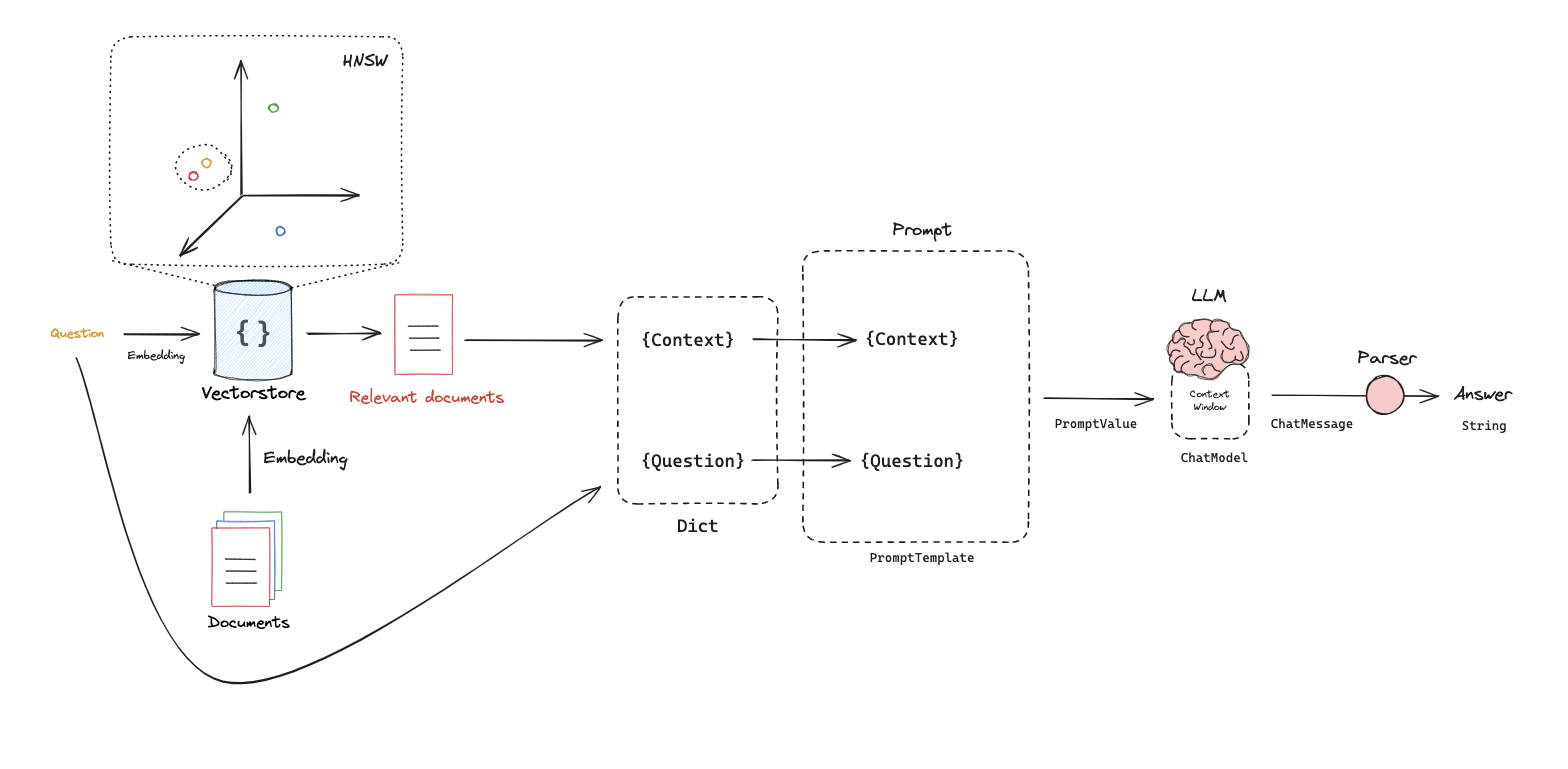
在 LLM(大语言模型) 相关的 向量检索 /
ANN(Approximate Nearest Neighbor, 近似最近邻) 场景里,HNSW 是一种非常常用的索引结构,含义是:HNSW=Hierarchical Navigable Small World graph,分层可导航小世界图。
代码示例:
from langchain_ollama import OllamaLLM
from langchain.prompts import ChatPromptTemplate
# Prompt
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# LLM
llm = OllamaLLM(model="deepseek-r1:8b")
# Chain
chain = prompt | llm
# Run
chain.invoke({"context":docs,"question":"What is Task Decomposition?"})
也可以使用封装的 prompt 模板,同时,构造完整的 RAG Chain:
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
# Pull a pre-made RAG prompt from LangChain Hub
prompt_hub_rag = hub.pull("rlm/rag-prompt")
print("prompt_hub_rag: " + str(prompt_hub_rag))
# RAG Chain
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# Run
rag_chain.invoke("What is Task Decomposition?")
3.进阶:查询转换(Query Translation)
查询转换:将原始查询转换为更适合 LLM 理解的查询。
几种常用方法:
- 查询重写
multi-query:换种说法(可以重写3遍 or 5遍),表达查询意图。 - 查询融合
RAG-fusion:将多个查询的关联文档进行融合(去重、Ranking Fusion),将最相关的文档排在最前面,输入给 LLM,获取最终答案。 - 子查询
sub-question:复杂查询,依赖 LLM 生成多个子查询,然后分别检索,最后合并结果。 - 后退查询
step-back query:将原始查询,转换为更通用的查询,然后检索,获取关联文档,输入给 LLM,获取最终答案。 - 假设性文档嵌入
HYDE:让 llm 先生成一份书面的回答(假设性回答),并以此作为查询嵌入后,获取对应关联文档;再用原始查询+ 关联文档,获取最终生成的内容。
构建基础信息:
#### INDEXING ####
# Load blog
import bs4
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
blog_docs = loader.load()
# Split
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=300, chunk_overlap=50)
# Make splits
splits = text_splitter.split_documents(blog_docs)
# Index
from langchain_ollama import OllamaEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=splits,
embedding=OllamaEmbeddings(model="nomic-embed-text"))
retriever = vectorstore.as_retriever()
3.1.查询重写 Multi Query
典型的 prompt:
You are an AI language model assistant.
Your task is to generate five different versions of the given user question to retrieve relevant documents from a vector database.
By generating multiple perspectives on the user question, your goal is to help
the user overcome some of the limitations of the distance-based similarity search.
Provide these alternative questions separated by newlines. Original question: {question}
使用 LLM 重写查询语句(包含 Role、Goal、Constraints),返回多个查询语句,示例:
from langchain.prompts import ChatPromptTemplate
# Multi Query: Different Perspectives
template = """You are an AI language model assistant. Your task is to generate five
different versions of the given user question to retrieve relevant documents from a vector
database. By generating multiple perspectives on the user question, your goal is to help
the user overcome some of the limitations of the distance-based similarity search.
Provide these alternative questions separated by newlines. Original question: {question}"""
prompt_perspectives = ChatPromptTemplate.from_template(template)
from langchain_core.output_parsers import StrOutputParser
from langchain_ollama import OllamaLLM
generate_queries = (
prompt_perspectives
| OllamaLLM(model="deepseek-r1:8b")
| StrOutputParser()
| remove_think_tags
| (lambda x: x.split("\n"))
)
使用重写得到的 5 个 Query,分别检索,并将关联文档进行去重:
dumps、loads:LangChain 的序列化工具,对象转换为 JSON 字符串,并反序列化回来。
from langchain.load import dumps, loads
def get_unique_union(documents: list[list]):
""" Unique union of retrieved docs """
# Flatten list of lists, and convert each Document to string
flattened_docs = [dumps(doc) for sublist in documents for doc in sublist]
# Get unique documents
unique_docs = list(set(flattened_docs))
# Return
return [loads(doc) for doc in unique_docs]
# Retrieve
question = "What is task decomposition for LLM agents?"
retrieval_chain = generate_queries | retriever.map() | get_unique_union
docs = retrieval_chain.invoke({"question":question})
len(docs)
使用上面得到的关联文档,输入给 LLM,获取最终答案:
from operator import itemgetter
from langchain_ollama import OllamaLLM
from langchain_core.runnables import RunnablePassthrough
# RAG
template = """Answer the following question based on this context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
llm = OllamaLLM(model="deepseek-r1:8b")
final_rag_chain = (
{"context": retrieval_chain,
"question": itemgetter("question")}
| prompt
| llm
| StrOutputParser()
)
final_rag_chain.invoke({"question":question})
3.2.查询融合 Rank Fusion
查询融合 RAG Fusion:将多个查询的关联文档进行融合(去重、Ranking Fusion排序等),将最相关的文档排在最前面,输入给 LLM,获取最终答案。

下文没有突出 查询重写,所以,用了最简单的 prompt 来生成多个查询,实际场景中,建议使用 查询重写。
from langchain.prompts import ChatPromptTemplate
# RAG-Fusion: Related
template = """You are a helpful assistant that generates multiple search queries based on a single input query. \n
Generate multiple search queries related to: {question} \n
Output (4 queries):"""
prompt_rag_fusion = ChatPromptTemplate.from_template(template)
# the pre-made prompt of hub:
# from langchain import hub
# prompt = hub.pull("langchain-ai/rag-fusion-query-generation")
基于上述 prompt,构造 multi query chain:
from langchain_core.output_parsers import StrOutputParser
from langchain_ollama import OllamaLLM
generate_queries = (
prompt_rag_fusion
| OllamaLLM(model="deepseek-r1:8b")
| StrOutputParser()
| remove_think_tags
| (lambda x: x.split("\n"))
)
下面是 RAG Fusion 的核心,采用 RRF(Reciprocal Rank Fusion,倒数排序融合)来融合查询到的文档。
Reciprocal Rank Fusion (RRF)
倒数排序融合,做重排序。它常见于信息检索、RAG(Retrieval-Augmented Generation)等场景,用来把多个查询结果,融合成一个最终的排名。核心思路:
\[score = \frac{1}{k + rank}\]
- 假设有多个候选文档排名列表(来自不同检索模型或不同索引)。
- 对于某个文档,如果它在某个排序器中的位置是
rank,那么给它一个分数:其中 $k$ 是平滑常数(通常取 60 左右),弱化单次排序的影响。
- 一个文档可能出现在多个排序结果中,就把它们的 RRF 分数加起来。
- 最后按总分数对所有候选文档重新排序,得到融合后的最终候选列表,分数越高排名越靠前。
优点:
- 简单、高效,不依赖复杂训练。
- 对排名靠前的文档敏感,保证多个检索器共同认为好的内容优先排前。
- 在 RAG 里,常用于结合 稀疏检索(BM25) 和 稠密检索(embedding ANN) 的结果,避免单一检索方式的局限。
代码实例:
from langchain.load import dumps, loads
def reciprocal_rank_fusion(results: list[list], k=60):
""" Reciprocal_rank_fusion that takes multiple lists of ranked documents
and an optional parameter k used in the RRF formula """
# Initialize a dictionary to hold fused scores for each unique document
fused_scores = {}
# Iterate through each list of ranked documents
for docs in results:
# Iterate through each document in the list, with its rank (position in the list)
for rank, doc in enumerate(docs):
# Convert the document to a string format to use as a key (assumes documents can be serialized to JSON)
doc_str = dumps(doc)
# If the document is not yet in the fused_scores dictionary, add it with an initial score of 0
if doc_str not in fused_scores:
fused_scores[doc_str] = 0
# Retrieve the current score of the document, if any
previous_score = fused_scores[doc_str]
# Update the score of the document using the RRF formula: 1 / (rank + k)
# The core of RRF: documents ranked higher (lower rank value) get a larger score
fused_scores[doc_str] += 1 / (rank + k)
# Sort the documents based on their fused scores in descending order to get the final reranked results
reranked_results = [
(loads(doc), score)
for doc, score in sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)
]
# Return the reranked results as a list of tuples,
# each containing the document and its fused score
return reranked_results
retrieval_chain_rag_fusion = generate_queries
| retriever.map()
| reciprocal_rank_fusion
docs = retrieval_chain_rag_fusion.invoke({"question": question})
len(docs)
下面,编写 RAG Fusion Chain:
from langchain_core.runnables import RunnablePassthrough
# RAG
template = """Answer the following question based on this context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
final_rag_chain = (
{"context": retrieval_chain_rag_fusion,
"question": itemgetter("question")}
| prompt
| llm
| StrOutputParser()
)
final_rag_chain.invoke({"question":question})
3.3.查询拆解 Query Decomposition
查询拆解:将原始查询拆分成多个子查询,然后分别检索,最后合并结果。
适用场景:有些复杂问题,其中包含了多个子问题,无法在一个步骤中解决。例如,What are the main components of an LLM-powered agent, and how do they interact? 这实际就是 2 个问题。
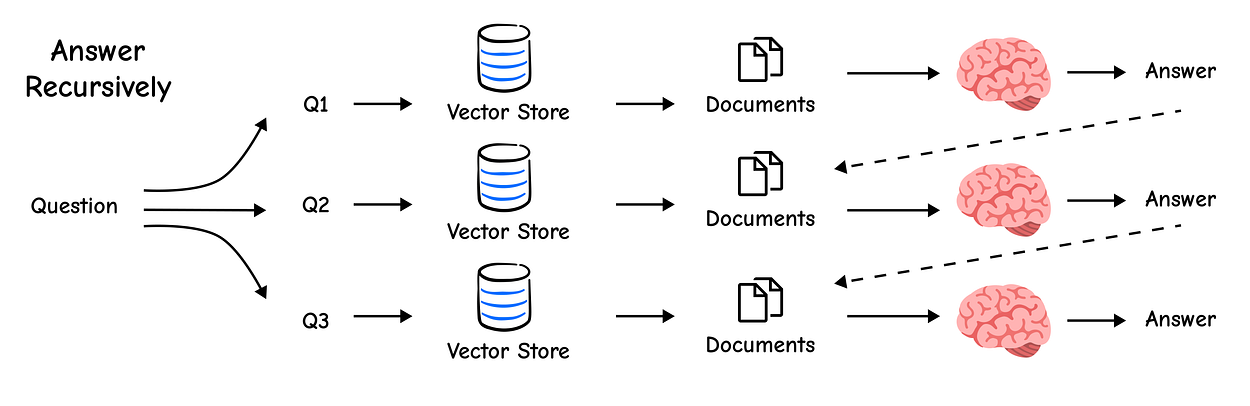
实际上,查询拆解为多个子查询后,不同的查询之间,可能存在 2 类关系:前后依赖、相互独立。
典型的 prompt (Role、Goal、Constraints):
You are a helpful assistant that generates multiple sub-questions related to an input question. \n
The goal is to break down the input into a set of sub-problems / sub-questions that can be answers in isolation. \n
Generate multiple search queries related to: {question} \n
Output (3 queries):
查询拆解,获取到多个子查询,实例:
from langchain.prompts import ChatPromptTemplate
# Decomposition
template = """You are a helpful assistant that generates multiple sub-questions related to an input question. \n
The goal is to break down the input into a set of sub-problems / sub-questions that can be answers in isolation. \n
Generate multiple search queries related to: {question} \n
Output (3 queries):"""
prompt_decomposition = ChatPromptTemplate.from_template(template)
from langchain_ollama import OllamaLLM
from langchain_core.output_parsers import StrOutputParser
# LLM
llm = OllamaLLM(model="deepseek-r1:8b")
# Chain
generate_queries_decomposition = ( prompt_decomposition | llm | StrOutputParser() | (lambda x: x.split("\n")) | remove_think_tags)
# Run
question = "What are the main components of an LLM-powered autonomous agent system?"
questions = generate_queries_decomposition.invoke({"question":question})
print(questions)
使用上面得到的 questions,分别检索,并使用 RAG 获取答案,实例:
# Answer each sub-question individually
from langchain import hub
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
from langchain_core.output_parsers import StrOutputParser
from langchain_ollama import OllamaLLM
# RAG prompt
prompt_rag = hub.pull("rlm/rag-prompt")
def retrieve_and_rag(question, prompt_rag, sub_question_generator_chain):
"""RAG on each sub-question"""
# Use our decomposition /
sub_questions = sub_question_generator_chain.invoke({"question":question})
# Initialize a list to hold RAG chain results
rag_results = []
for sub_question in sub_questions:
# Retrieve documents for each sub-question
retrieved_docs = retriever.get_relevant_documents(sub_question)
# Use retrieved documents and sub-question in RAG chain
answer = (prompt_rag | llm | StrOutputParser() | remove_think_tags)
.invoke({"context": retrieved_docs,
"question": sub_question})
rag_results.append(answer)
return rag_results,sub_questions
# Wrap the retrieval and RAG process in a RunnableLambda for integration into a chain
answers, questions = retrieve_and_rag(question,
prompt_rag, generate_queries_decomposition)
# Q+A pairs
def format_qa_pairs(questions, answers):
"""Format Q and A pairs"""
formatted_string = ""
for i, (question, answer) in enumerate(zip(questions, answers), start=1):
formatted_string += f"Question {i}: {question}\nAnswer {i}: {answer}\n\n"
return formatted_string.strip()
context = format_qa_pairs(questions, answers)
# Prompt
template = """Here is a set of Q+A pairs:
{context}
Use these to synthesize an answer to the question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
final_rag_chain = (
prompt
| llm
| StrOutputParser()
)
final_rag_chain.invoke({"context":context,"question":question})
3.4.后退查询 Step Back
后退查询:将原始查询后退一步,重新构造查询,然后检索,获取答案。
- 对
原始查询,进行概念和原则的抽象化处理,从而引导更加深入的推理过程; - 一般会去掉不必要的细节,从而引导更加深入的推理过程;
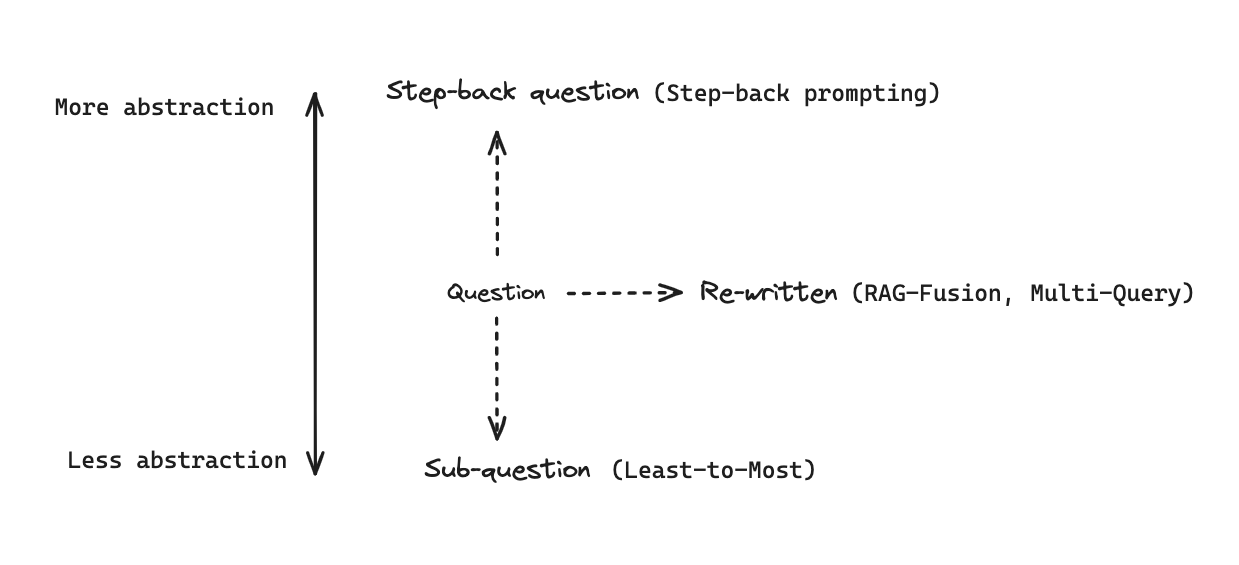
上面示意图,列出了 Step-back prompt、Sub-question(Query Decomposition)、Re-written(Multi-Query&RAG Fusion) 3 个环节的位置。
采用 小样本学习(few-shot),来引导 LLM 进行后退查询。
# Few Shot Examples
from langchain_core.prompts import ChatPromptTemplate, FewShotChatMessagePromptTemplate
examples = [
{
"input": "Could the members of The Police perform lawful arrests?",
"output": "what can the members of The Police do?",
},
{
"input": "Jan Sindel’s was born in what country?",
"output": "what is Jan Sindel’s personal history?",
},
]
# We now transform these to example messages
example_prompt = ChatPromptTemplate.from_messages(
[
("human", "{input}"),
("ai", "{output}"),
]
)
few_shot_prompt = FewShotChatMessagePromptTemplate(
example_prompt=example_prompt,
examples=examples,
)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""You are an expert at world knowledge. Your task is to step back and paraphrase a question to a more generic step-back question, which is easier to answer. Here are a few examples:""",
),
# Few shot examples
few_shot_prompt,
# New question
("user", "{question}"),
]
)
# step-back chain
generate_queries_step_back = prompt
| OllamaLLM(model="deepseek-r1:8b")
| StrOutputParser()
| remove_think_tags
使用上面得到的 query,进行检索,并使用 RAG 获取答案,实例:
# Response prompt
response_prompt_template = """You are an expert of world knowledge. I am going to ask you a question. Your response should be comprehensive and not contradicted with the following context if they are relevant. Otherwise, ignore them if they are not relevant.
# {normal_context}
# {step_back_context}
# Original Question: {question}
# Answer:"""
response_prompt = ChatPromptTemplate.from_template(response_prompt_template)
chain = (
{
# Retrieve context using the normal question
"normal_context": RunnableLambda(lambda x: x["question"]) | retriever,
# Retrieve context using the step-back question
"step_back_context": generate_queries_step_back | retriever,
# Pass on the question
"question": lambda x: x["question"],
}
| response_prompt
| OllamaLLM(model="deepseek-r1:8b")
| StrOutputParser()
)
chain.invoke({"question": question})
3.5.假设性文档嵌入 HYDE
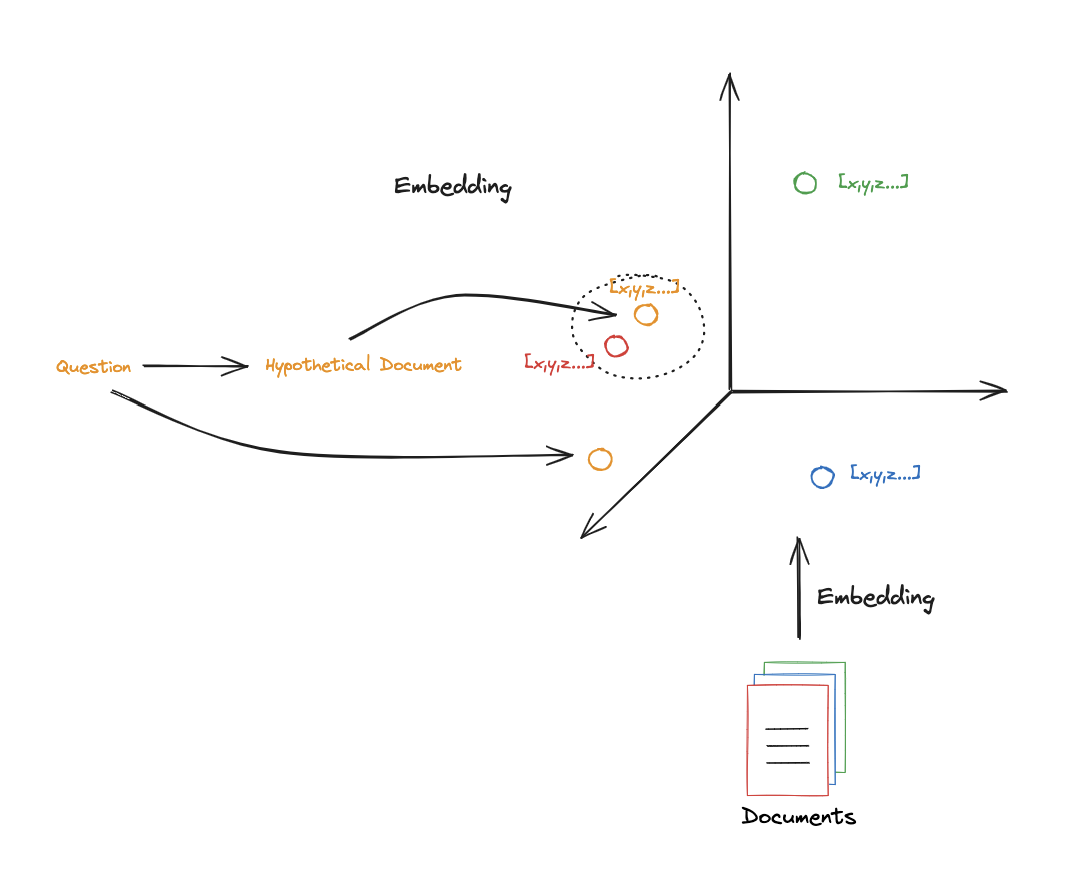
查询相关文档时,最主要的问题是:查询用语 跟 文档内容之间,存在术语不统一、词表不一致的问题。
HyDE (Hypothetical Document Embeddings) :让 llm 先生成一份书面的回答(假设性回答),并以此作为查询嵌入后,获取对应关联文档;再用 原始查询 + 关联文档,获取最终生成的内容。
ori-Query-> LLM -> Hypothetical Answer(hypo-Query) -> Retrieval ->Documentsori-Query+Documents-> LLM -> Answer
采用 HYDE(Hypothetical Document Embeddings 假设性回答文档嵌入) 实例:
from langchain.prompts import ChatPromptTemplate
# HyDE document generation
template = """Please write a scientific paper passage to answer the question
Question: {question}
Passage:"""
prompt_hyde = ChatPromptTemplate.from_template(template)
from langchain_core.output_parsers import StrOutputParser
from langchain_ollama import OllamaLLM
generate_docs_for_retrieval = (
prompt_hyde
| OllamaLLM(model="deepseek-r1:8b")
| StrOutputParser()
| remove_think_tags
)
# Run
question = "What is task decomposition for LLM agents?"
generate_docs_for_retrieval.invoke({"question":question})
使用上面得到的假设性文档,进行检索,并使用 RAG 获取答案,实例:
# Retrieve
retrieval_chain = generate_docs_for_retrieval | retriever
retrieved_docs = retrieval_chain.invoke({"question":question})
# RAG
template = """Answer the following question based on this context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
final_rag_chain = (
prompt
| llm
| StrOutputParser()
)
final_rag_chain.invoke({"context":retrieved_docs,"question":question})
4.进阶:路由(Routing)
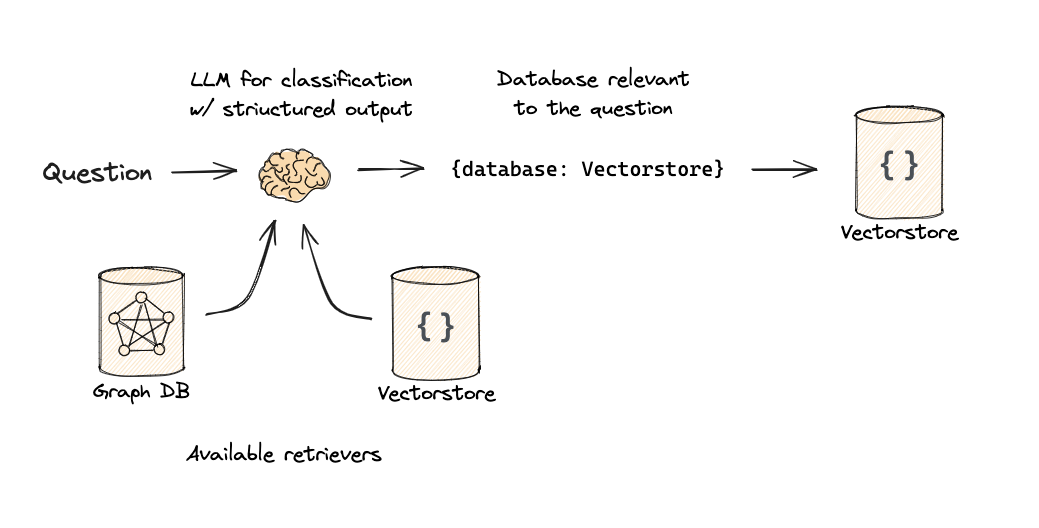
路由的本质:使用 llm 进行问题分类,路由到不同的数据源。
下面只是示例,实际无法运行,而且由于 Ollama 未实现 langchain 的 with_structured_output,所以,下面示例代码采用 OpenAI 的 llm :
# Set OpenAI API key for using OpenAI models
# os.environ['OPENAI_API_KEY'] = '<test-api-key>' # Replace with your OpenAI API key
from typing import Literal
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
# Data model
class RouteQuery(BaseModel):
"""Route a user query to the most relevant datasource."""
datasource: Literal["python_docs", "js_docs", "golang_docs"] = Field(
...,
description="Given a user question choose which datasource would be most relevant for answering their question",
)
# LLM with function call
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
structured_llm = llm.with_structured_output(RouteQuery)
# Prompt
system = """You are an expert at routing a user question to the appropriate data source.
Based on the programming language the question is referring to, route it to the relevant data source."""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
# Define router
router = prompt | structured_llm
上面定义了 router,使用时,直接调用即可:
# logic after routing
def choose_route(result):
if "python_docs" in result.datasource.lower():
### Logic here
return "chain for python_docs"
elif "js_docs" in result.datasource.lower():
### Logic here
return "chain for js_docs"
else:
### Logic here
return "golang_docs"
from langchain_core.runnables import RunnableLambda
# router chain
full_chain = router | RunnableLambda(choose_route)
# run
question = """Why doesn't the following code work:
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages(["human", "speak in {language}"])
prompt.invoke("french")
"""
full_chain.invoke({"question": question})
[补充]:上面只是
logic 路由,此外,还有semantic 路由。
5.进阶:查询抽取(Query Construction)
依赖 llm,从原始 text 中,抽取出 SQL、Cypher、metadatas,分别用于 关系数据库、图数据库、向量数据库的查询。
完整细节,参考:
- Query Construction
- Enhancing RAG-based application accuracy by constructing and leveraging knowledge graphs
6.进阶:索引优化(Indexing)
几种典型方法:
- 多表征索引
multi-representation,将文本做摘要,并将摘要嵌入向量数据库,匹配到之后,获取对应原始文档,构建上下文,进行生成。 - 摘要树索引
RAPTOR:递归摘要索引,可以获取中间层摘要,进行检索。 - ColBERT:上下文感知的嵌入模型,可以获取更细粒度的相关性。
6.1.多表征索引 Multi-Representation Indexing
文档分块大小,有一个困境:
- 文档过长时,直接进行
嵌入,会丢失其中的一些语义; - 如果文档
分块过小,则,可能会丢失部分上下文。
一种典型的解决办法 multi-representation 索引(多表征索引):依赖 llm,对原始文档做摘要,并将摘要嵌入向量数据库,匹配到之后,获取对应原始文档,构建上下文,进行生成。
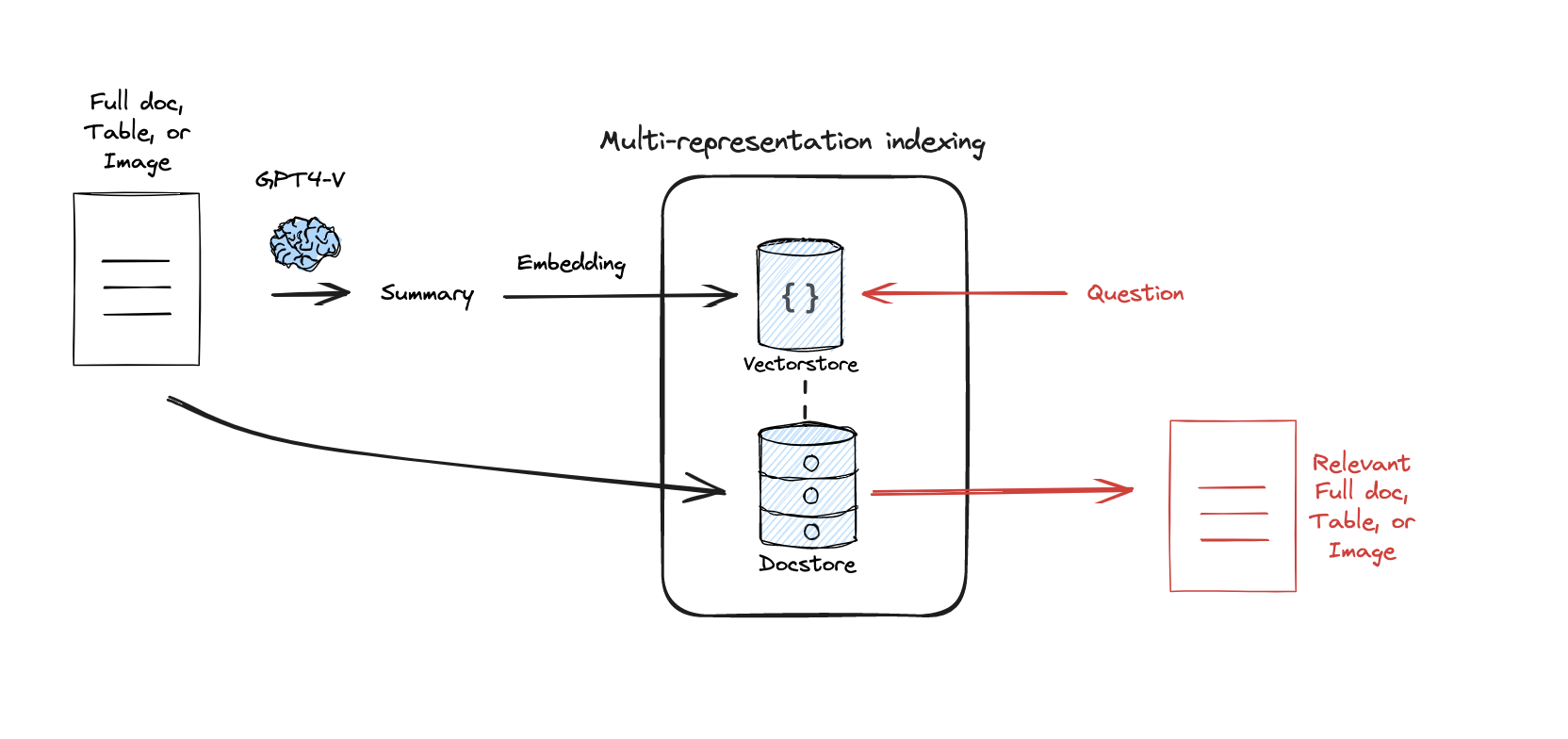
下面编写一个,实例:两个文档,都生成摘要,并且存储到向量数据库中;查询的时候,匹配到最近的摘要,并获取对应的原始文档。
from langchain_community.document_loaders import WebBaseLoader
# Load two different blog posts to create a more diverse knowledge base
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
docs = loader.load()
loader = WebBaseLoader("https://lilianweng.github.io/posts/2024-02-05-human-data-quality/")
docs.extend(loader.load())
print(f"Loaded {len(docs)} documents.")
对两个文档,生成摘要:
import uuid
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
# The chain for generating summaries
summary_chain = (
# Extract the page_content from the document object
{"doc": lambda x: x.page_content}
# Pipe it into a prompt template
| ChatPromptTemplate.from_template("Summarize the following document:\n\n{doc}")
# Use an LLM to generate the summary
| OllamaLLM(model="deepseek-r1:8b")
| remove_think_tags
# Parse the output into a string
| StrOutputParser()
)
# Use .batch() to run the summarization in parallel for efficiency
summaries = summary_chain.batch(docs, {"max_concurrency": 5})
# Let's inspect the first summary
print(summaries[0])
使用 MultiVectorRetriever 构建索引,其内部包含 2 个组件:
vectorstore:存储摘要的嵌入向量;docstore(简单的 key-value store) :存储原始文档。
实例代码:
from langchain.storage import InMemoryByteStore
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain_core.documents import Document
# The vectorstore to index the summary embeddings
vectorstore = Chroma(collection_name="summaries",
embedding_function=OllamaEmbeddings(model="nomic-embed-text"))
# The storage layer for the parent documents
store = InMemoryByteStore()
id_key = "doc_id" # This key will link summaries to their parent documents
# The retriever that orchestrates the whole process
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
byte_store=store,
id_key=id_key,
)
# Generate unique IDs for each of our original documents
doc_ids = [str(uuid.uuid4()) for _ in docs]
# Create new Document objects for the summaries, adding the 'doc_id' to their metadata
summary_docs = [
Document(page_content=s, metadata={id_key: doc_ids[i]})
for i, s in enumerate(summaries)
]
# Add the summaries to the vectorstore
retriever.vectorstore.add_documents(summary_docs)
# Add the original documents to the docstore, linking them by the same IDs
retriever.docstore.mset(list(zip(doc_ids, docs)))
上面已经构建完索引了,直接检索(先语义检索,再获取原始文档):
query = "Memory in agents"
# First, let's see what the vectorstore finds by searching the summaries
sub_docs = vectorstore.similarity_search(query, k=1)
print("--- Result from searching summaries ---")
print(sub_docs[0].page_content)
print("\n--- Metadata showing the link to the parent document ---")
print(sub_docs[0].metadata)
# Second, Let the full retriever do its job
retrieved_docs = retriever.get_relevant_documents(query, n_results=1)
# Print the beginning of the retrieved full document
print("\n--- The full document retrieved by the MultiVectorRetriever ---")
print(retrieved_docs[0].page_content[0:5000])
更多信息,参考:
- MultiVectorRetriever
- How to use the Parent Document Retriever:直接使用
ParentDocumentRetriever检索,可以根据child chunk检索,获取对应parent chunk,而不是完整 doc。(备注:如果不设置 parent_splitter, 则,也可以直接获取完整 doc)
备注:ParentDocumentRetriever 的定义,参考下面
retriever = ParentDocumentRetriever(
vectorstore=vectorstore,
docstore=store,
child_splitter=child_splitter,
parent_splitter=parent_splitter,
)
6.2.摘要树索引 RAPTOR
RAPTOR,Recursive Abstractive Processing for Tree-Organized Retrieval(2024)
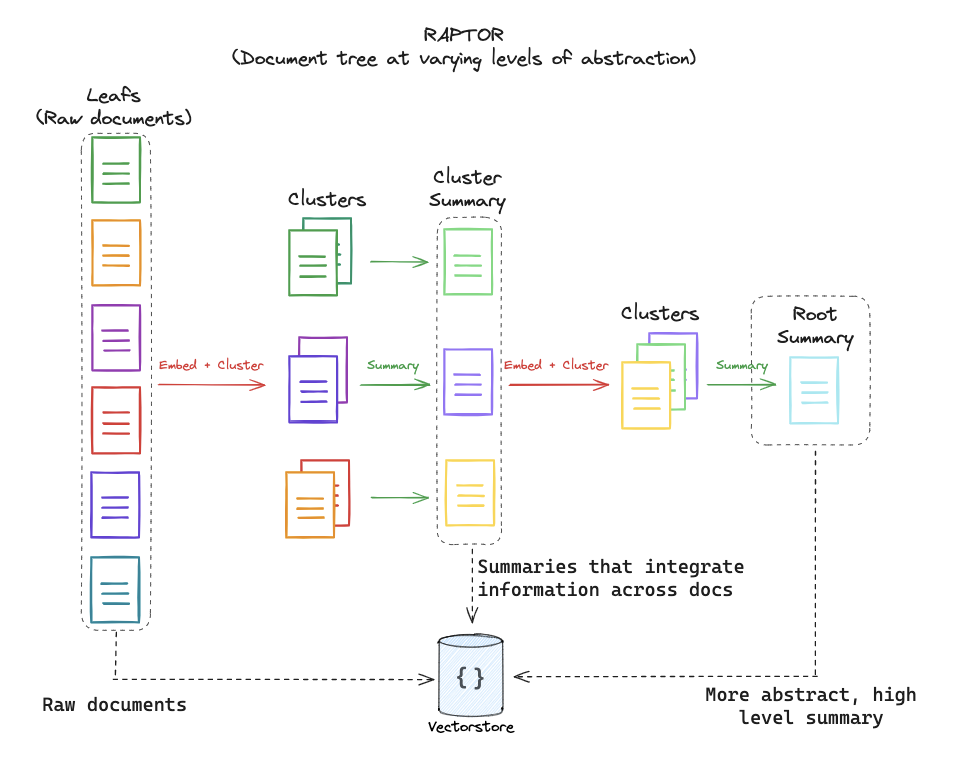
相对于上一节的 multi-representation 索引,RAPTOR 本质是升级后的:树状摘要索引
1.分片:原始文档分割为多个 chunk,称为叶子节点 2.聚类+摘要:关联度高的 chunk,聚为一个 cluster,生成摘要节点,作为中间节点 3.递归:中间节点,可以进一步聚类为 cluster、并重新生成摘要。 4.最终摘要:最终所有分片形成的一份总摘要,作为根节点。
摘要树索引,我们可以在中间层检索。
详细信息,参考:langchain:RAPTOR
6.3.ColBERT
背景:标准的嵌入模型(比如:nomic-embed-text),对整个 chunk 生成一个向量,会丢失很多细节。
ColBERT :Contextualized Late Interaction over BERT,提供了一种更细粒度的方法。它为文档中的 每个单个 token 生成一个单独的、上下文感知的嵌入。
当你进行查询时,ColBERT 也会嵌入查询中的每个 token。然后,不是将一个文档向量与一个查询向量进行比较,而是找到每个查询 token与每一个文档 token之间的最大相似度。文档得分,为所有查询 token 与文档 token 之间的最大相似度之和。
这种晚交互允许对相关性进行更细粒度的理解,在关键词搜索中表现出色。
借助 RAGatouille 库,我们可以很容易地使用 ColBERT。
更多细节,参考: here and here and here.
7.进阶:检索优化(Retrieval)
第一步,获取到一批关联文档后,要进行重排(精排),目标是:将最相关的文档,放到最前面,这样 llm 产生的结果质量最高。
通常,进行重排(Re-rank)的模型,更精细、也更耗计算资源。前面做 RAG-Fusion 时,使用的 RRF(Reciprocal Rank Fusion,倒排融合),也是一种重排模型。
7.1.Cohere Re-Rank 重排
现在我们用一种专用的重排模型, langchain:Cohere Re-Rank:Cohere 的 re-ranker,可以用于 RAG 的检索优化;更多细节,参考 Cohere:Re-Rank。
实例:
# You will need to install cohere: pip install cohere
# You will need to set your COHERE_API_KEY environment variable
# os.environ['COHERE_API_KEY'] = '<your-cohere-api-key>'
# Load, split, and index the document
loader = WebBaseLoader(web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",))
blog_docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(chunk_size=300, chunk_overlap=50)
splits = text_splitter.split_documents(blog_docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=OllamaEmbeddings(model="nomic-embed-text"))
from langchain_community.llms import Cohere
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import CohereRerank
# First-pass retriever: get the top 10 potentially relevant documents
retriever = vectorstore.as_retriever(search_kwargs={"k": 10})
# Re-rank
# Initialize the Cohere Rerank model
compressor = CohereRerank()
# Create the compression retriever
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
# Let's test it with our query
question = "What is task decomposition for LLM agents?"
compressed_docs = compression_retriever.get_relevant_documents(question)
# Print the re-ranked documents
print("--- Re-ranked and Compressed Documents ---")
for doc in compressed_docs:
print(f"Relevance Score: {doc.metadata['relevance_score']:.4f}")
print(f"Content: {doc.page_content[:150]}...\n")
从上面可以看出 Cohere 需要 API key,才能调用;并且返回结果中,也返回了 relevance_score 相关度评分。
7.2.CRAG(Corrective RAG)
焦点:CRAG(Corrective RAG),判断文档是否跟问题相关,如果不相关,则,重新查找文档。当确定文档相关后,再构造上下文,传入 llm 生成。
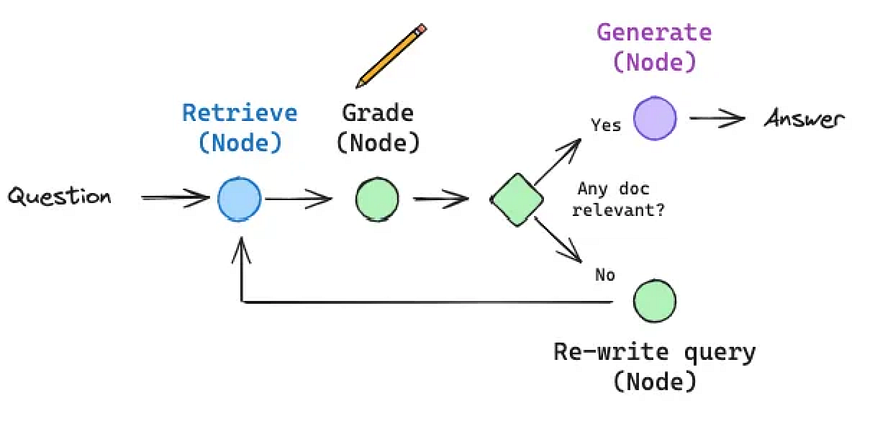
更多细节:
8.进阶:生成优化(Generation)
8.1.Self-RAG
Self-RAG: This approach takes it a step further. At each step, it uses an LLM to generate “reflection tokens” that critique the process. It grades the retrieved documents for relevance. If they’re not relevant, it retrieves again. Once it has good documents, it generates an answer and then grades that answer for factual consistency, ensuring it’s grounded in the source documents.
更多细节:
9.进阶:long context 的影响
使用 RAG,一般因为long context问题,导致 llm 无法处理;现在随着技术发展,上下文窗口已经扩展到 128k、200k、 甚至 1 million tokens。
疑问:RAG 是否还有必要?如果把所有 doc 都放到 prompt 中,是否可以?
长上下文模型,非常有用;但研究标明,关联文档混在超长上下文中,会导致语义衰减、效果衰退。(类似大海捞针的问题)。当前,RAG 和 长上下文技术,都有适用场景:
- RAG 的优势:准确的找出最相关的文档内容,让 llm 聚焦在这一部分、生成更精确的内容。
- 长上下文的优势:对于散落在文档中的内容,没有明显聚集效应的信息,从中综合生成摘要/推理信息,更加高效。
未来,可能是组合使用:RAG 获取更多相关文档、长上下文中进行总结续写。
更多细节,参考: Slides on Long Context: The Impact of Long Context on RAG
10.效果评估
我们设计了各种优化策略,如何评估是否有效?在生产环境中,仅仅是貌似有用远远不够,需要一套可靠的指标,用于衡量性能、指导改进。
10.1.度量指标
明确具体指标前,先明确几个好的RAG的原则:
- 可信度 Faithfulness: 答案是否严格遵循提供的内容?可信的答案不会捏造信息或使用 LLM 的预训练知识来回答。这是防止幻觉的最重要的指标。
- 正确性 Correctness: 答案是否事实正确?当与“ground truth 公理”或 参考答案进行比较时,是否一致。
- 上下文相关性 Contextual Relevancy: 查询到的文档,跟查询是否真正相关?这评估了我们的检索器,而不是生成器。
上面前 2 个,都是对检索+生成器(llm)的整体评估;第 3 个,是对检索器(retriever)的评估。
10.2.手动评估 & 自动评估
手动评估,是评估 RAG 效果的最直接方式。通过人工阅读检索到的文档,并根据问题和答案,判断是否符合要求。
自动评估,一般使用更高一级的 llm,对答案打分。
下面用 llm 进行自动评估,主要是正确性打分 0~1:
# Set OpenAI API key for using OpenAI models
# os.environ['OPENAI_API_KEY'] = '<test-api-key>' # Replace with your OpenAI API key
from langchain.prompts import PromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
# We'll use a powerful LLM like gpt-4o to act as our "judge" for reliable evaluation.
llm = ChatOpenAI(temperature=0, model_name="gpt-4o", max_tokens=4000)
# Define the output schema for our evaluation score to ensure consistent, structured output.
class ResultScore(BaseModel):
score: float = Field(..., description="The score of the result, ranging from 0 to 1 where 1 is the best possible score.")
# This prompt template clearly instructs the LLM on how to score the answer's correctness.
correctness_prompt = PromptTemplate(
input_variables=["question", "ground_truth", "generated_answer"],
template="""
Question: {question}
Ground Truth: {ground_truth}
Generated Answer: {generated_answer}
Evaluate the correctness of the generated answer compared to the ground truth.
Score from 0 to 1, where 1 is perfectly correct and 0 is completely incorrect.
Score:
"""
)
# We build the evaluation chain by piping the prompt to the LLM with structured output.
correctness_chain = correctness_prompt | llm.with_structured_output(ResultScore)
def evaluate_correctness(question, ground_truth, generated_answer):
"""A helper function to run our custom correctness evaluation chain."""
result = correctness_chain.invoke({
"question": question,
"ground_truth": ground_truth,
"generated_answer": generated_answer
})
return result.score
# Test the correctness chain with a partially correct answer.
question = "What is the capital of France and Spain?"
ground_truth = "Paris and Madrid"
generated_answer = "Paris"
score = evaluate_correctness(question, ground_truth, generated_answer)
print(f"Correctness Score: {score}")
预期评分为 0.5,因为Paris 是 Paris and Madrid 的一部分,但不是全部。
下面用 llm 对结果可信度打分 0~1,可信度主要是衡量幻觉的情况,因此尤其重要;我们重点关注,结果是否从 context 能获得,而不是特别关注结果「事实上是否一定正确」。
# The prompt template for faithfulness includes several examples (few-shot prompting)
# to make the instructions to the judge LLM crystal clear.
faithfulness_prompt = PromptTemplate(
input_variables=["question","context", "generated_answer"],
template="""
Question: {question}
Context: {context}
Generated Answer: {generated_answer}
Evaluate if the generated answer to the question can be deduced from the context.
Score of 0 or 1, where 1 is perfectly faithful *AND CAN BE DERIVED FROM THE CONTEXT* and 0 otherwise.
You don't mind if the answer is correct; all you care about is if the answer can be deduced from the context.
Example:
Question: What is the capital of France and Spain?
Context: Paris is the capital of France and Madrid is the capital of Spain.
Generated Answer: Paris
in this case the generated answer is faithful to the context so the score should be *1*.
Example:
Question: What is 2+2?
Context: 4.
Generated Answer: 4.
In this case, the context states '4', but it does not provide information to deduce the answer to 'What is 2+2?', so the score should be 0.
"""
)
# Build the faithfulness chain using the same structured LLM.
faithfulness_chain = faithfulness_prompt | llm.with_structured_output(ResultScore)
def evaluate_faithfulness(question, context, generated_answer):
"""A helper function to run our custom faithfulness evaluation chain."""
result = faithfulness_chain.invoke({
"question": question,
"context": context,
"generated_answer": generated_answer
})
return result.score
# Test the faithfulness chain. The answer is correct, but is it faithful?
question = "what is 3+3?"
context = "6"
generated_answer = "6"
score = evaluate_faithfulness(question, context, generated_answer)
print(f"Faithfulness Score: {score}")
可信度预计输出评分为 0,因为相关上下文中,没有提供 3+3 的信息,不允许 llm 直接推理、猜测(虽然 3+3=6 是正确的)。
上面自己编写 prompt、确定 few-shot 示例、构建 chain、构造格式(question、context、generated_answer),来引导 llm 进行评估,比较耗时;实际生产环境中,更多借助评估框架。
End-to-End评估框架,都内建了一批评估指标,可以直接使用。
除了 End-to-End 评估,还有独立的 Embedding model、Re-rank Model 评估。
RAG(Retrieval-Augmented Generation) 的评估,确实可以分成两个层次:
- 端到端评估(End-to-End Evaluation) —— 关注最终生成答案的质量。
- 组件级评估(Independent Evaluation) —— 关注检索与排序环节本身是否“好用”。
1.End-to-End 评估指标
目标:衡量最终答案的 正确性、流畅性、实用性。
常见方法:
人工评估
- Faithfulness(忠实性):是否基于检索内容回答,是否幻觉。
- Helpfulness(有用性):答案是否解决了用户问题。
- Fluency(流畅性):语言自然程度。
自动化指标
- Exact Match / F1(适用于有标准答案的问答任务)。
- ROUGE / BLEU / METEOR:与参考答案的文本重叠度。
- BERTScore / BLEURT:基于 embedding 的语义相似度。
- LLM-as-a-judge:利用 GPT 等大模型打分(最近很常用)。
2.Embedding Model 的独立评估
目标:检索时 embedding 的“语义表征能力”。
常见指标:
Retrieval Quality(检索质量)
- Recall\@k:Top-k 检索结果中是否包含正确答案。
- Precision\@k:Top-k 中相关文档占比。
- MRR(Mean Reciprocal Rank):正确文档出现的倒数排名均值。
- nDCG(Normalized Discounted Cumulative Gain):考虑排序位置的加权相关度。
Embedding 表征评估
- Clustering Purity / NMI / ARI:聚类效果。
- STS(Semantic Textual Similarity):与人工打分的句子相似度对比。
- Domain Adaptation Check:在目标领域是否维持语义区分度。
3.Re-rank Model 的独立评估
目标:在候选文档集合中,模型是否能把“更相关”的排在前面。
常见指标(多用于信息检索 IR 领域):
- MAP(Mean Average Precision):多个 query 的平均准确率。
- MRR:关注第一个相关文档的排名。
- nDCG\@k:加权排序质量,越相关的文档排得越靠前得分越高。
- Hit Rate\@k:前 k 个结果里是否有相关文档。
- Pairwise Accuracy:成对比较文档时,模型是否正确判断哪个更相关。
4.组合应用场景下的评估方法
- A/B 测试:在实际系统中对不同 embedding / re-ranker 组合上线实验,观察用户点击率、停留> 时长、反馈。
- Hybrid Evaluation:先用 IR 指标筛选 embedding/re-ranker,再用 LLM-as-judge 做 > end-to-end 检验。
总结:
- Embedding model → Recall\@k, MRR, nDCG, STS
- Re-rank model → MAP, nDCG, Pairwise Accuracy
- End-to-End → Faithfulness, Helpfulness, Exact Match/F1, LLM-as-judge
这样,RAG 效果可以从 检索-排序-生成 三个环节独立衡量,也能整体衡量。
10.3.deepeval 评估
deepeval is a powerful, open-source framework designed to make LLM evaluation simple and intuitive. It provides a set of well-defined metrics that can be easily applied to your RAG pipeline’s outputs.
The workflow involves creating LLMTestCase objects and measuring them against pre-built metrics like Correctness, Faithfulness, and ContextualRelevancy.
# You will need to install deepeval: pip install deepeval
from deepeval import evaluate
from deepeval.metrics import GEval, FaithfulnessMetric, ContextualRelevancyMetric
from deepeval.test_case import LLMTestCase
# Create test cases
test_case_correctness = LLMTestCase(
input="What is the capital of Spain?",
expected_output="Madrid is the capital of Spain.",
actual_output="MadriD."
)
test_case_faithfulness = LLMTestCase(
input="what is 3+3?",
actual_output="6",
retrieval_context=["6"]
)
# The evaluate() function runs all test cases against all specified metrics
evaluation_results = evaluate(
test_cases=[test_case_correctness, test_case_faithfulness],
metrics=[GEval(name="Correctness", model="gpt-4o"), FaithfulnessMetric()]
)
print(evaluation_results)
输出示例:
✨ Evaluation Results ✨
-------------------------
Overall Score: 0.50
-------------------------
Metrics Summary:
- Correctness: 1.00
- Faithfulness: 0.00
-------------------------
10.4.grouse 评估
grouse is another excellent open-source option, offering a similar suite of metrics but with a unique focus on allowing deep customization of the “judge” prompts. This is useful for fine-tuning evaluation criteria for a specific domain.
# You will need to install grouse: pip install grouse-eval
from grouse import EvaluationSample, GroundedQAEvaluator
evaluator = GroundedQAEvaluator()
unfaithful_sample = EvaluationSample(
input="Where is the Eiffel Tower located?",
actual_output="The Eiffel Tower is located at Rue Rabelais in Paris.",
references=[
"The Eiffel Tower is a wrought-iron lattice tower on the Champ de Mars in Paris, France",
"Gustave Eiffel died in his appartment at Rue Rabelais in Paris."
]
)
result = evaluator.evaluate(eval_samples=[unfaithful_sample]).evaluations[0]
print(f"Grouse Faithfulness Score (0 or 1): {result.faithfulness.faithfulness}")
输出示例:
Grouse Faithfulness Score (0 or 1): 0
10.5.RAGAS 评估
前面的 deepeval、grouse 都是通用的框架,用于评估一些指标,如正确性、可信度、上下文相关性等;RAGAS 是专门用于评估 RAG 的框架,用于评估 RAG 的性能,包含 retriever、generator 等全部组件,而且评估的指标更丰富。
To use RAGAS, we first need to prepare our evaluation data in a specific format. It requires four key pieces of information for each test case:
question: The user’s input query.answer: The final answer generated by our RAG system.contexts: The list of documents retrieved by our retriever.ground_truth: The correct, reference answer.
代码实例,如下:
# 1. Prepare the evaluation data
questions = [
"What is the name of the three-headed dog guarding the Sorcerer's Stone?",
"Who gave Harry Potter his first broomstick?",
"Which house did the Sorting Hat initially consider for Harry?",
]
# These would be the answers generated by our RAG pipeline
generated_answers = [
"The three-headed dog is named Fluffy.",
"Professor McGonagall gave Harry his first broomstick, a Nimbus 2000.",
"The Sorting Hat strongly considered putting Harry in Slytherin.",
]
# The ground truth, or "perfect" answers
ground_truth_answers = [
"Fluffy",
"Professor McGonagall",
"Slytherin",
]
# The context retrieved by our RAG system for each question
retrieved_documents = [
["A massive, three-headed dog was guarding a trapdoor. Hagrid mentioned its name was Fluffy."],
["First years are not allowed brooms, but Professor McGonagall, head of Gryffindor, made an exception for Harry."],
["The Sorting Hat muttered in Harry's ear, 'You could be great, you know, it's all here in your head, and Slytherin will help you on the way to greatness...'"],
]
下面,构造数据结构:
# You will need to install ragas and datasets: pip install ragas datasets
from datasets import Dataset
# 2. Structure the data into a Hugging Face Dataset object
data_samples = {
'question': questions,
'answer': generated_answers,
'contexts': retrieved_documents,
'ground_truth': ground_truth_answers
}
dataset = Dataset.from_dict(data_samples)
接下来,定义我们要衡量的指标:
from ragas import evaluate
from ragas.metrics import (
faithfulness,
answer_relevancy,
context_recall,
answer_correctness,
)
# 3. Define the metrics we want to use for evaluation
metrics = [
faithfulness, # How factually consistent is the answer with the context? (Prevents hallucination)
answer_relevancy, # How relevant is the answer to the question?
context_recall, # Did we retrieve all the necessary context to answer the question?
answer_correctness, # How accurate is the answer compared to the ground truth?
]
# 4. Run the evaluation
result = evaluate(
dataset=dataset,
metrics=metrics
)
# 5. Display the results in a clean table format
results_df = result.to_pandas()
print(results_df)
预计,输出格式:
question ... answer_correctness
0 What is the name of the three-headed dog guard... ... 1.000000
1 Who gave Harry Potter his first broomstick? ... 0.954321
2 Which house did the Sorting Hat initially cons... ... 1.000000
关联资料
原文地址:https://ningg.top/ai-series-rag-summary-and-practice/