AI视野:傅盛-变与不变,用 AI 做小应用切入
2023-12-02
原文地址:傅盛:用大模型,做小工具
1.变与“不变”
我认为“创新”这个词可能会让创业者迷失自我。很多时候,创新不是创造出来的,而是成长出来的。当社会趋势发生重大变化时,总会有人实现这一趋势,不是你可能就是别人。
比如乔布斯。苹果前CEO约翰·斯卡利感叹,乔布斯最伟大的能力是既可以zoom in(缩近),也可以zoom out(拉远)。他能看到两个区域间可能发生连接的机会,这是创业者最好的时间点,而他能很细致地实现这个连接。
我创业十几年,有幸在2002年加入互联网行业,成为一名产品经理。在互联网高速发展的二三十年中,诞生了代表快速变化的互联网思维。但贝索斯说,亚马逊要把未来十年都投入到不变的事情上。这句话很有意思,互联网强调快速变化,怎么去找不变的东西呢?
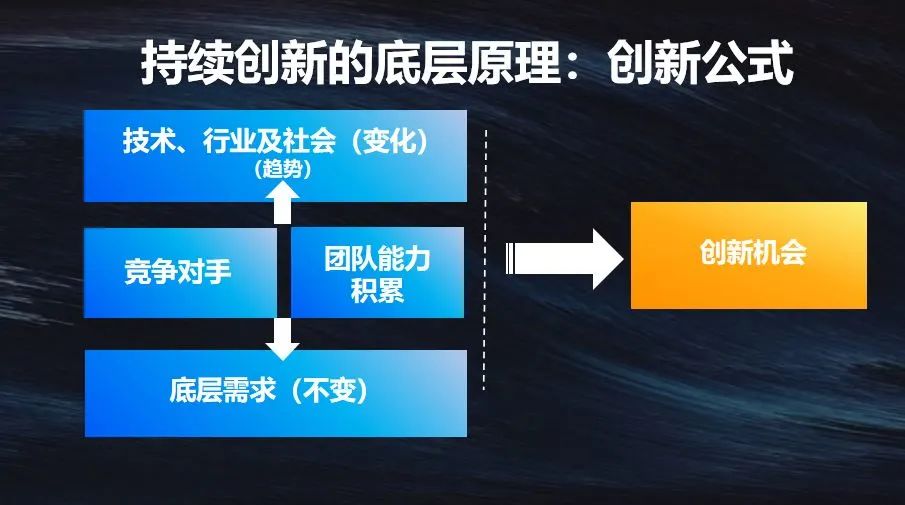
无论做什么,无论东方西方、古代现代,
- 人类的底层需求不会变,比如吃喝玩乐、衣食出行、更高的荣誉感、更好的存在感等,
- 马斯洛需求层次理论适用于人类的所有社会阶层。
我做产品经理时一直在批驳一个观点:做产品不要做用户调查,因为用户不知道自己想要什么。
- 持这个观点的人,最喜欢举的一个例子是:当没有汽车的时候,你问用户,用户永远说需要更快的马车。
- 这其实是一种诡辩。
- 用户的底层需求是更快、更安全的出行。
- 用户并不知道汽车这个产品。
- 等内燃机发明出来,创业者把内燃机装到四个轮子上,就变成了汽车,满足的还是用户不变的需求。
所以,创业者的安家立业之本是对用户和对技术的理解。哪怕不是做技术的,也一定要真正了解其基本原理。我们更多是在摸索、生长,让它涌现出来,找到新技术和我们现在业务的结合点。
当年为什么我做360这样的安全软件能有机会?
- 因为对安全的需求一直在那里,
- 只是正好遇到互联网出现,安全的形势发生了变化,互联网加快了木马病毒的传播,
- 这时老的安全厂商没有跟上变化,所以给了我这个机会。
为什么我能把猎豹移动做上市?那时我意识到,由于互联网的出现,中美两个大国在应用技术上没有本质差别。2012年我带了几十个工程师去美国学习,请人来讲安卓课的时候,发现他们讲的东西我们的工程师都懂。
移动互联网让全球化加速,于是我做了猎豹移动。我们作为创业者,要把用户不变的底层需求想清楚,再结合技术、行业和社会的变化,在其中找到一个连接点。
对手没有做和自身的团队积累也是一个创新因素。
- 我做过的几个产品能用户量过亿,很大程度是因为对手正好没有做,或者大公司没有重视。
- 有句话叫“
非共识的机会才是创业者最好的机会”。 - 当对手不是很强,这个趋势刚刚发生,开始涌现,又符合人类底层需求时,就有可能找到创新机会。
2.第三次科技奇迹年
GPT带来的AI浪潮一定是巨大的。我特别喜欢的一位科普作者卓克认为,今年是科技的奇迹年。科技的奇迹年在历史上只出现过两次。
- 一次是1666年,牛顿在这一年做出了巨大的科技成果(开辟了光学这个物理学分支,创立了微积分这个数学分支,导出了引力公式这个现代自然科学的基础规律) ,此后《自然哲学的数学原理》出版,牛顿三大定律横空出世;
- 另一次是1905年爱因斯坦发表了四篇论文,这四篇论文改变了世界。
- 而卓克之所以认为今年是一个奇迹年,是因为GPT的出现,会使很多技术的底层范式发生重大变化。
为什么说今年是奇迹年?
语义理解是人工智能技术的皇冠。- 人工智能第一波浪潮,解决的是
图像识别的问题,但识别并不是人类独有的能力。 - 智人和动物的核心区别在于语言,能描述虚拟事物的语言。
- 清华教授刘嘉说,语言的规则是语言产生后人类想办法总结出来的。
- 我们学的语法结构,无论是主谓宾、定状补,都是根据语言总结的规则,人类今天对语言本身的原理还没有真正研究清楚。
70多年前,艾伦·图灵提出图灵测试,这被认为是检测智能的最好办法。最近GPT推出了语音版,如果从未听过它的声音,跟它对话肯定觉得是真人。所以我认为GPT的出现已经在某种程度上解决了图灵测试想要解决的问题。
语义理解是非常难的。我们在2016年就投资了人工智能,当时整个行业都认为AlphaGo出来以后就是一马平川,解决了图像识别就可以解决语音识别、语义理解和自动驾驶等。但人工智能攻克语义理解的难度,高于做出图像识别的难度。当时有人认为,自动驾驶之所以迟迟未被攻克,不是识别问题,而是逻辑问题。看到障碍会刹车并不一定就是会开车的老司机,要对路况做出判断,对整体的逻辑有深刻理解才行。自动驾驶不是靠识别和规则就能搞定的,否则猩猩都能开车了。但猩猩不能开车,尽管猩猩的识别能力很强。人为什么要到18岁才能考驾照?是因为开车需要逻辑理解和一定的模式判别能力。
2016年后,元宇宙、区块链的概念很热,人工智能却没有以前喊得那么响了。那时我也很痛苦,我们做了很多机器人放在商场里,我女儿天天去和它互动,回来对我说,老爸你做了人工智障机器人。但其实不是我不行,而是行业的天花板在那里。但这次GPT的出现可以说是震惊了所有人。

在GPT出现前,几乎全球的大公司和人工智能公司都在用学外语的方式教机器理解语言。
- 比如,某大公司号称有千万级的知识图谱,为了理解语言,可能有几千万词汇的各种组合,
- 比如主语后面要有谓语,如果没有谓语该怎么填等。
- 这些都是极其复杂的规则,由成百上千人的团队在做,就连我们这样规模的公司都是上百人在做。
好处是学会这些规则就可以开始回答问题了。最典型的应用就是淘宝客服,你说什么,它就给你弹出对应的界面。
我曾经问过我们的专家、香港大学计算机系主任马毅教授这样一个问题,数学能不能真正地模拟智能,把智能的原理给呈现出来?他说当然可以,其实我们的智能就是压缩和预测的过程。比如我现在看到这么多人在这里,我的视网膜里至少有上亿像素点在不断冲击,经过层层压缩到大脑里,最后变成会场的同学们。但这个原理很难应用。
OpenAI最厉害的是,它相信可以像教母语一样,只要持续给它大段的文字,不用单独去培训,它就像小孩一样,突然有天就会张口说话了。
OpenAI做这件事就像哥伦布发现美洲,并不只是技术难度的问题,而是路线选择的问题。前几年OpenAI甚至是硅谷的笑话,大家都觉得是异想天开,训练一次几千万美金,什么规则也不给它,计算机有天就能像人一样说话了?给它几亿的文本,也不教它什么,它突然就能得出雄安在北京的南边吗?但这件事的确发生了。
ChatGPT出现之前的对话系统更多是一种模式匹配,虽然它也能回答问题,但系统实际上不理解问题的具体含义;如果这个问题不在人类给它的那些模式范围里,它就回答不了。而ChatGPT却真正做到了理解词的含义。
人的语言,是千变万化的。举个例子,
- 我们做智能音箱,“下一首”是一个很简单的命令。
- 为了符合用户预期,我们可以做上百个泛化,有人会说“再听一首”,有人会说“我还想再听”“再来一个”,为几个词我们做了很多泛化,才能勉强达到音箱的可用性。
- 但你对ChatGPT说“上一首”“下一首”,它都能真正地理解,我们再也不用做那些复杂繁重的工作了。
很多人说ChatGPT会一本正经地胡说八道,其实人也经常一本正经地胡说八道。我们有办法用一些工具和应用把它限制在一个框架里。它本质就是一个大号的计算机,不必太过神话。我觉得只要人类的法治不崩溃,社会不出大问题,它对人类肯定是一个很好的工具。

GPT的原理很简单,就是根据词的概率去计算下一个词,但就是这么简单的原理,带来了智能的涌现。
因此,数据的输入很重要,你希望它在哪方面更擅长,就要给它这方面更多的数据。现在已有论文可以证明,在百亿参数模型下对某一类知识着重训练,它便可以在单项能力方面表现出和GPT4一样的能力。
3.ChatGPT将带来两大革命
那么,我们该如何看待ChatGPT带来的变化?

第一,交互革命。
乔布斯曾经在苹果的发布会上说过,每一次交互的革命都是一次产业的机会,苹果成功抓住过两次次机会,第一次是键盘输入替代打孔,第二次是图形化界面,而现在要抓住第三次,就是触摸屏。
人类为了能够使用机器,需要花费大量的时间和精力进行学习。例如要想做PPT,就要先学习PPT的格式。事实上,如今我们的很多工作都是帮机器翻译成它听得懂的语言。程序员便是如此,企业老板提出一种功能需求,程序员就需要将这句话变成机器能理解的语言。
但由于GPT的出现,以后机器将围绕人运转,要针对人类提出的需求开展工作。微软将它的AI工具称为Copilot,也就是说,人类发挥主观能动性即可,人和机器代码之间的翻译,机器自身就可以完成。
只要人类不出现问题,GPT一定是好的工具,它能够帮助人类完成重复性的智能推理工作。并且机器本身没有任何情绪,不会担忧人类将其摧毁,至少现在如此。
第二,生产力革命。
马化腾在一次财报会上说,过去会认为大模型是十年一遇的机会,而现在觉得它可能是几百年一次的大机遇。
互联网虽然促进了生产力的发展,但它不是生产力革命,它只是生产关系革命。通过互联网推动的生产关系极大优化,倒逼了生产力的效率提升;但问题在于,无论如何提升效率,最终还需要依靠机器生产。
生产力革命的核心是,当一个要素能够转变成另一个生产要素,就可以直接做范式转化。
蒸汽机出现之前,热能只能用来烧东西,动能单纯依靠的是人和畜牲,动能和热能是隔离的。蒸汽机的出现第一次让热能变成动能,进而迅速地提升了人均GDP。
通用人工智能,可以理解为机器插上电就可以获得智能,机器只需要经过简单的培训就能完成大量的工作。以前的电脑智能,更多是针对特定场景去写代码、做前期工作,边际成本降不下来。但在今天的通用人工智能模式下,公司内部的行政文档只要给大模型读取一遍,行政工作量就可以下降一半以上。员工通过虚拟机器人就可以完成很多工作,例如请假、购票、预定酒店等等。
生产力革命不仅存在于公司层面,也可能存在于国家层面。Sam Altman(萨姆·奥特曼)是OpenAI的CEO,他在过去几个月内见过20多个国家领导人,他们探讨的是这次的生产力革命会给国家竞争带来何种变化。在未来的竞争中,人口素质可能只占一半,而算力、大模型能力、智能能力可能会变成国家的核心竞争力。
4.人的能力如何发挥?
过去我们会认为,发明机器是帮人类做体力劳动,例如洗碗做饭;但没有想到,它首先替代了用电脑的人。
Altman(萨姆·奥特曼)提出,大模型首先让在电脑面前工作时间长的人价值贬值。因为在电脑面前工作,很大一部分时间都是将人类的需求翻译成电脑能理解的语言,无论是写PPT、Word还是程序代码,但现在不需要翻译了。
所以在这个时代,一定要积极主动学习。但应该学什么呢?GPT作为大号计算器,可以解决人类的很多问题。但是,人类的好奇心、梦想,还有追求一件事情的执着精神,这种起心动念是GPT完全没有办法替代的。所以,今后人类真正的能力在于想法和提问的能力。
人类也不必过于恐慌,大模型技术不会吞噬一切,它也不能解决所有问题。

第一,私有数据的问题。今天,ChatGPT所有数据都来自于公开的数据,但即使浩瀚的互联网数据也只是人类认知的冰山一角;人类是用没露出水面的那部分冰山去创造论文,这是大模型没有办法学习到的。
语言是高度压缩的,每个词都可以在人类脑海中形成万千景象,而每个词在传递过程中也会形成偏差,所以私有数据会是未来每个企业的核心竞争力。
第二,能力边界的问题。今天的大模型依然有能力边界的问题,即便AI很火,但当下大模型的稳定度还是要数GPT4好一些,哪怕是GPT3.5都不够,未来还有很长的路程要走。
第三,参数越大,大模型成本越高,不仅是训练成本,还有服务成本。虽然微软Copilot每月收费标准是20美金,但实际的服务成本却要八九十美金。
现在可以明显感受到,整个AI行业在向几个方向发展:
第一个是平台。包括OpenAI在内的大公司的梦想就是创造一个“爱因斯坦”或者是一百个“爱因斯坦”,这样就可以解决全人类的问题。Sam Altman(萨姆·奥特曼)表示,以后很多人都不用工作,超级大模型可以解决所有问题,从而实现物质生产的极大丰富。OpenAI正在开发10万块显卡并联的计算平台,他们要做大参数、做出超级人物,但是它的成本过高,并不适用所有企业。
第二个是私有化大模型。GPT3.5有1000多亿的参数,取得了很好的智能效果,但仍有发展的空间,现在GPT4的效果更加明显。
5.每个公司都要做大模型吗?
微软虽然投资了OpenAI,但考虑到成本过高,并没有选择做大模型。但微软却一直在做应用,当OpenAI推出ChatGPT之后,微软便把GPT集成在Bing里,放到Office里。也就是在应用界面里加一个聊天助手,这让微软的市值涨了差不多一万亿。
在OpenAI和谷歌都入局之后,Facebook相继发布了LLaMA1和LLaMA2,相比不能商用的LLaMA1,LLaMA2是开源可商用的。
为什么要开源?就是让更多人能够拥有自己的大模型,并且在上面做应用。所以当时我想出一句话,叫“忽然一夜开源来,千模万模智能开”。国内都在很多在做新的大模型,据不完全统计,目前已经接近200个,虽然绝大部分都是建立在开源巨人的肩膀上。
但开源是全人类的文明成果,安卓是建立在开源Linux内核之上,鸿蒙也是建立在安卓的内核之上,不分东方西方,能用好开源就是优势。由于开源的出现,很多行业垂直大模型的成本急速下降,最早说OpenAI的一次训练需要2000万美金,但现在训练百亿参数的模型成本可能已经降到了几百万人民币,下降速度非常快。
这样一来,第一,行业和企业大模型会越来越普及;第二,应用生态会决定大模型的商业价值。
通用大模型无法解决城市和企业的实际或特色问题。互联网上出现的人类知识只是冰山一角,水面之下大量的私有知识还无法体现。
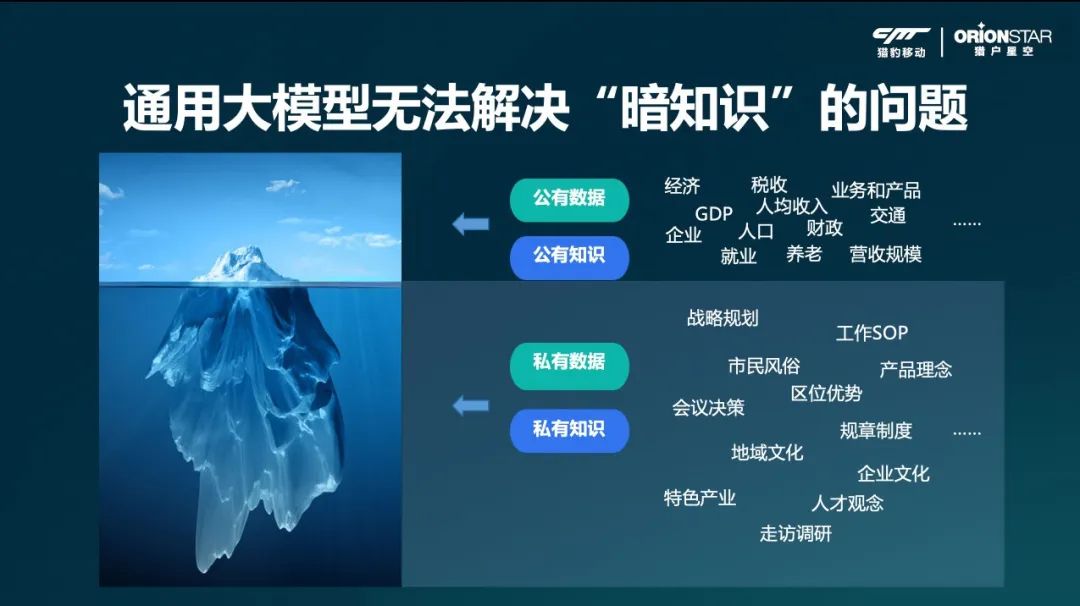
比如,互联网企业做的最多的一件事就是开会,开会就是数据,从开会前期的需求收集、中间的讨论、形成决策、实践并复盘,这些都是大模型没有的数据。一个公司真正的效率就是它的流程决策,从做出决定到付诸实践,这其中的一点一滴都是每一家公司的核心,这是通用大模型无法做到的。
所以在这个时代,中型以上的企业都要考虑拥有自己的私有化模型,当然小企业更可以快速地先上、先用。
但问题在于,有了大模型,企业是不是接个接口就能用的很好,就可以成为超级厉害的公司呢?也未必,应用需要把一些能力深度挖掘出来,比如Facebook要进行开源,开源最大的好处有两个方面:
第一,它调动了诸如大学等顶尖的研究团体的智慧,进而变成了一个大的技术反馈。谷歌提出,未来他们最大的对手就是开源,开源社区一旦打开,所有大学都可以使用,它的技术就可以实现快速迭代。
第二,程序员可以在开源上面写代码、写应用。程序员已经在接口上写好了应用,当它被移植到另一个系统时,就要耗费巨大的精力。
今天搭建操作系统没有技术难度,任何一家公司修改几个开源代码的参数就可以拥有自己的系统,但没有意义。操作系统的难度在于生态建设,程序员在上面写了大量代码,这才是操作系统最核心的价值。
所以为什么LLaMA2要开源?因为开源之后就可以在里面形成大量的规范。英伟达的芯片除了算力很优秀之外,更重要的是程序员已经养成了在它的CUDA框架下写代码的习惯,这就是生态的力量。大模型也是同理,它一定会有生态,会有很多不同的应用产生,它一定不会是一个聊天接口就可以解决的事情。所以,无论是平台还是生态,很多东西都需要一个过程。这也是为什么我说现在大模型一定不是一上就灵。
模型可以很大,但做的事情不要嫌小;从很小的细节开始做,相信每家公司都会有自己的AI创造力,都会让AI为自己插上腾飞的翅膀。
原文地址:https://ningg.top/ai-view-series-00-fusheng-overview-of-ai-trend/